淘宝 封住baidu的蜘蛛了吗?
来源:互联网 发布:手机淘宝开店教程2016 编辑:程序博客网 时间:2024/05/01 15:08
首先祝大家月饼节快乐!
由于一开始没有弄清楚robots.txt和robot.txt,造成了一些错误,感谢“那山那人那狗 [未注册用户] ”的提醒。所以对原来的内容进行了一下修改。
前几天看见博友写文章说淘宝封了baidu的蜘蛛,用http://www.taobao.com/robots.txt 这个地址查看了robots.txt 文件内容,确实是不允许baidu的蜘蛛了,其他二级域名里的 robots.txt 文件,比如 http://store.taobao.com/robots.txt 也禁止了baidu的蜘蛛。robots.txt 内容是(如下),
User-agent: Baiduspider
Disallow: /
User-agent: baiduspider
Disallow: /
那么过了好几天了,我们再来看baidu 里面的收录情况,打开baidu,输入site:www.taobao.com ,第一条就是9月12日的快照。 再输入 site:taobao.com 第四条就是9月13日的快照。第一页有8条九月份的快照。这样看来,根本就没有限制住!
下面是截图:
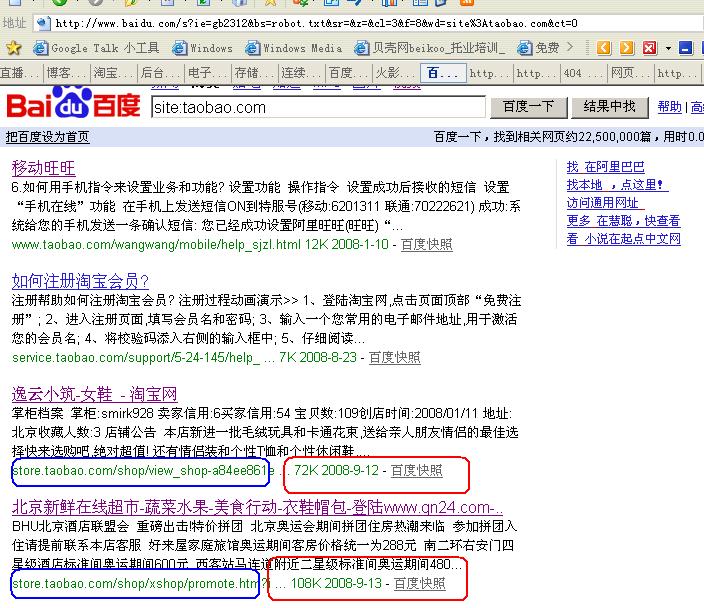
我到网上查了一下robots.txt文件的格式,http://www.baidu.com/search/robots.html 这里是baidu对robots.txt的解释,有一点值得注意一下。
“baiduspider通常每天访问一次网站的robots.txt文件,您对robots所做的修改,会在48小时内生效。需要注意的是,robots.txt禁止收录以前百度已收录的内容,从搜索结果中去除可能需要数月的时间。”
现在baidu已经收录了 约22,500,000篇 网页,这些网页什么时候会被去除呢?“需要数月”。
感谢 那山那人那狗 [未注册用户] 的提醒,确实是把网址给弄错了,其实这个网址是从http://www.cnblogs.com/dingxue/archive/2008/09/09/1287262.html 这里第四楼拷贝过来的。被害了,呵呵。
不过,http://store.taobao.com/robot.txt 这个地址确实有内容,导致了我的误解。
- 淘宝 封住baidu的蜘蛛了吗?
- 淘宝的店被封掉了!!
- 淘宝、腾讯、Sohu和Baidu谈大型网站的开发
- 小试了一下baidu的blog
- 蜘蛛来了!
- 蜘蛛来了!
- 有的像全身长满了爪子的蜘蛛
- 蜘蛛不爬取,您检查过网站的robots了么
- 淘宝网开始屏蔽百度蜘蛛爬虫
- baidu又作恶了
- 今天比较了一下google和baidu的图片搜索
- Baidu HI使用了QQ TM的代码
- 一个收集了很多网络知识的Baidu博客。。
- 无聊,做了几道baidu之星的题目
- 淘宝蝌蚪的SVN免费对外开放了
- 淘宝推出了定制版本的 JVM
- 淘宝的东西越来越多了
- 看了淘宝的商业模式分析
- 开发速度之我见
- 客户的一个问题,给我交了一盆冷水。
- update 的一种用法
- 如此之乱的思绪,如何才能专心工作?
- csdn里面的 “飞信”源代码下载
- 淘宝 封住baidu的蜘蛛了吗?
- “自然”架构
- 面对蛋糕,您是如何下刀的?
- Heritrix使用的初步总结
- 实体类的变形【2】—— 行列转换
- 遨游浏览器2与Google的chrome
- 实体类的变形【1】—— 餐盘原理
- 分层、实体类与耦合!
- 昨天去爬香山了!


