高效SQL查询之索引(II)
来源:互联网 发布:选项卡切换js 编辑:程序博客网 时间:2024/05/16 02:06
上回我们说到评估一条语句执行效率主要看逻辑 IO (啥是逻辑 IO ,啥是物理 IO 见联机文档),这次我们继续。
我们先说说,返回多行结果时,为什么 SQLServer 有时会选择 index seek ,有时会选择 index scan 。
以 nonclustered index 为例说明。
像所有的索引 B 树一样,非聚集索引树也包括完全由索引数据组成的根节点和中间级节点;但是和聚集索引树不同的是,聚集索引树叶节点包含的是基础表的数据页(我们常说,表的物理存储顺序和聚集索引相同,就是这个原因),非聚集索引树叶节点是索引页。 SQLServer 通过非聚集索引查找数据时,会通过这个非聚集索引键值去搜索聚集索引,进而检索基础表数据行。
假设有这样一张表,非聚集索引树深度为 2 ,一层根节点( 1 个索引页),一层叶节点( 4 个索引页)。聚集索引树深度为 3 ,一层根节点( 1 个索引页),一层中间级节点( 2 个索引页),一层叶节点( 250 页,也就是基础表物理存储页)表的数据假设 1w 行。注:所有数据均为假设,只为说明原理。
我们首先,再强调一遍, SQLServer 获取数据,总是以页为单位,就算是只读取一行也会获取整张页 (见《写有效率的 SQL 查询( I )》)
现在有一条简单查询 ( 如: select * from tb where col2 = 99 , col2 是 tb 表中的非聚集索引 ) ,假设会返回 100 行。
Ok ,我们来分析如果以 Index seek 来查找这 100 行会有多少 IO 。 index seek 每次都从索引树根节点开始查找,找到中间级节点( 99 对应的索引行),然后从该节点行开始连续遍历所有 col2 为 99 的索引行。在遍历这些行时,每拿到一条,都会通过该条索引行中聚集索引键值去聚集索引树中 index seek ,然后从数据页中获取数据。在最坏的情况下, col2 为 99 对应的索引行跨越了全部 4 个叶级非聚集索引页(当然,这没啥可能性,举例而已,切勿深究);每次通过聚集索引树进行 index seek , IO 开销最坏情况下是一个根节点,一个中间级节点,一个数据页 , 一共要 seek100 次,开销 300 个逻辑 IO 。综上,通过 nonclustered index seek 总共开销是 305 个 IO 。
要知道,我们的基础表数据页一共才 250 页,这说明了啥?说明就算是我从头到尾扫描一遍表也比 noncustered index seek 快。这时, SQL2k5 会产生一个完完全全的 clustered index scan 执行计划来搞定表扫描。
好了,现在我们再来分析 select * from tb1 where col2 = 1 。假设它的结果集为 5 行。如果这时还是进行 nonclustered index seek 的话,逻辑 IO 按照上面相似的分析,应该是 19 个 IO ,远远要小于整个的 clustered index scan 。这时, SQLServer 自然会采用 nonclustered index seek 。
我们再来看聚集索引。聚集索引和非聚集索引最大的不同在于聚集索引的存储顺序就是基础表的物理存储顺序。还是上面的表 tb ,假设聚集索引建在了 col1 上 . 如果 where 条件是 col1 = XX 的话,自然是 index seek ,因为 IO 最小,撑死了只有 3 (一个聚集索引根节点页,一个聚集索引中间级节点页,一个数据页);如果 where 条件是 col1 > XX 的话,不管行集是多大, SQLServer 总是首先通过 index seek 拿到 XX 对应的数据页,然后挨梆往后遍历基础表数据页到尾巴就 OK 了。最坏情况 XX 恰好比表中最小的 col1 小,那就读取所有行。如果 where 条件是 col1 < XX ,那就倒着检索聚集索引,无他。
OK ,到这里,我们明白了为啥 SQLServer 会选择 index seek 和 index scan 。也顺便明白了通过非聚集索引查询时,结果集相对总行数多寡对查询计划选择的巨大影响。
(结果集 / 总行数)被称为选择性,比值越大,选择性就越高。
你得到了它,本文的重点就是选择性。
统计信息,说白了,就是表中某个字段取某个值时有多少行结果集。统计信息可以说是一种选择性的度量, SQLServer 就是根据它来估算不同查询计划的优劣。
后面将通过一个实际的例子来说明统计信息对查询计划的影响。
以下是示例表的表结构:
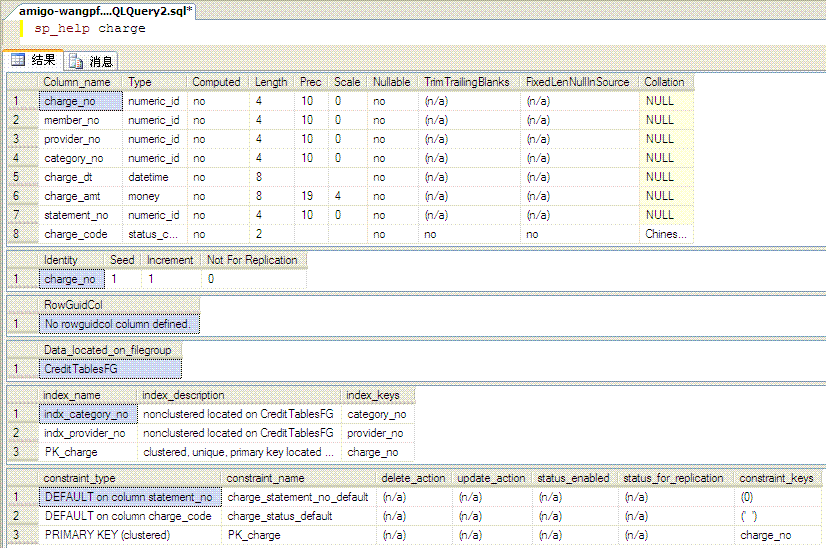
:![]()
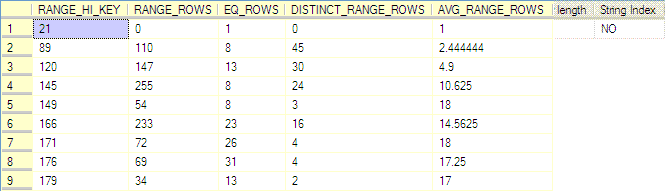
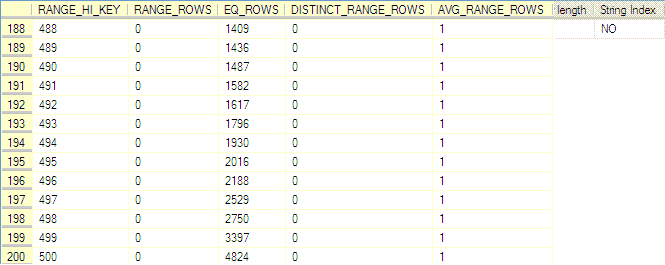
(上述各字段含义,见联机文档对 DBCC SHOW_STATISTICS 的描述)
从上面的贴图可以看到,表中总行数为 1w ,采样行数为 1w 。 provider_no 值为 21 的只有 1 行,而值为 500 的行则有 4824 行。下面两张图是两条 SQL 的查询计划,我就不多嘴解释了。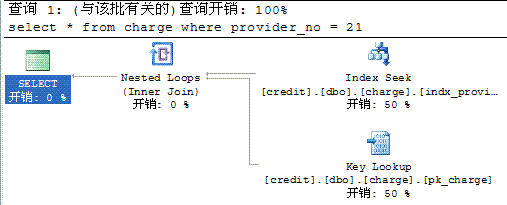
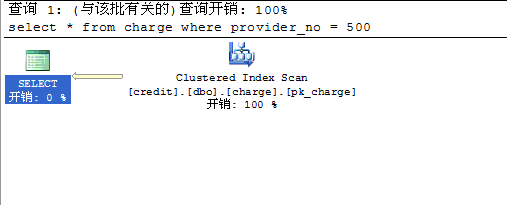
那么问题来了:
我们知道, SQLServer 会缓存查询计划,假如有这么一个存储过程:
create proc myproc
(
@pno int
)
as
select * from charge where provider_no = @pno
第一次我们传进来一个 21 , OK ,它会缓存该存储过程的执行计划为 nonclustered index seek 那个。后来我们又传进来一个 500 ,完蛋了,服务器发现它有一个 myproc 的缓存, so ,又通过 nonclustered index seek 执行,接着你的同伙看到你的查询花费了巨量的 IO ,于是,你被鄙视了。
这说明了啥?说明如果你的查询选择性变动剧烈,你应该告诉 SQLServer 不要缓存查询计划,每次都应该重新评估、编译。实现方法很简单,查询的尾巴上加一个 option ( recompile )好了。而且 SQL2k5 还有一个 nb 的 feature ,可以每次只重新编译存储过程的一部分(当然,你也可以选择重新编译整个存储过程,这取决于你的需求。详见联机文档。)
各位可以注意到,该表上有一个 identity 字段 charge_no ,聚集索引就创建在它上面。有两个非聚集索引 indx_category_no , indx_provider_no ,我们重点关注 indx_provider_no 。现在来看看 provider_no 字段的统计信息(有点长,我前边粘一部分,后边粘一部分):
- 高效SQL查询之索引(II)
- 高效SQL查询之索引(II)
- 高效SQL查询之索引(II)
- 高效SQL查询之索引(I)
- 高效SQL查询之索引(III)
- 高效SQL查询之索引(V)
- 高效SQL查询之索引(V)
- 高效SQL查询之索引(VI)
- 高效SQL查询之索引(I)
- 高效SQL查询之索引(III)
- 高效SQL查询之索引(I)
- 高效SQL查询之索引(III)
- 高效SQL查询之索引(VI)
- 高效SQL查询之索引(V)
- 高效SQL查询之索引(VI)
- 高效SQL查询之索引覆盖(index coverage)
- 高效SQL查询之索引覆盖(index coverage)
- 高效SQL查询之索引覆盖(index coverage) .
- TEKLA 15.0 PLUGINS DLL 编译手册
- 评原百度CTO李一男的经典语录
- 蛇形矩阵和远程注入
- 高效SQL查询之索引(I)
- JAVA培训题库-AJAX
- 高效SQL查询之索引(II)
- 看完电影他哭了
- 存储控制器
- 高效SQL查询之索引(III)
- 寻找NV项
- 日志不能成功归档,找不到目的地
- 高效SQL查询之索引(VI)
- JAVA培训题库-JavaScript
- Send SMS with GSM Modem - CMS Error codes


