Google Pangrank 算法
来源:互联网 发布:大学生工资低 知乎 编辑:程序博客网 时间:2024/05/05 19:31
网上很多,刚好要用,稍稍整理一下
Wiki
PageRank算法
简单的
假设一个由4个页面组成的小团体:A,B, C 和 D。如果所有页面都链向A,那么A的PR(PageRank)值将是B,C 及 D的和。
- PR(A) = PR(B) + PR(C) + PR(D)
继续假设B也有链接到C,并且D也有链接到包括A的3个页面。一个页面不能投票2次。所以B给每个页面半票。以同样的逻辑,D投出的票只有三分之一算到了A的 PageRank 上。
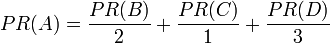
换句话说,根据链出总数平分一个页面的PR值。
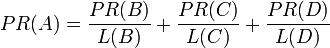
最后,所有这些被换算为一个百分比再乘上一个系数q。由于下面的算法,没有页面的PageRank会是0。所以,Google通过数学系统给了每个页面一个最小值1 − q。
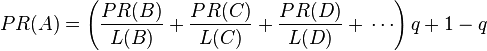
所以一个页面的 PageRank 是由其他页面的PageRank计算得到。Google 不断的重复计算每个页面的 PageRank。如果您给每个页面一个随机 PageRank 值(非0),那么经过不断的重复计算,这些页面的 PR 值会趋向于正常和稳定。这就是搜索引擎使用它的原因。
[编辑]完整的
这个方程式引入了随机浏览的概念,即有人上网无聊随机打开一些页面,点一些链接。一个页面的PageRank值也影响了它被随机浏览的概率。为了便于理解,这里假设上网者不断点网页上的链接,最终到了一个没有任何链出页面的网页,这时候上网者会随机到另外的网页开始浏览。
为了对那些有链出的页面公平,q = 0.15(这里的q被称为阻尼系数(damping factor), 其意义是,在任意时刻,假想的随机浏览者停止在某页面后继续浏览的概率。)的算法被用到了所有页面上,估算页面可能被上网者放入书签的概率。
所以,这个等式如下:
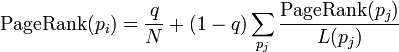
p1,p2,...,pN是被研究的页面,M(pi)是链入pi页面的数量,L(pj)是pj链出页面的数量,而N是所有页面的数量。
PageRank值是一个特殊矩阵中的特征向量。这个特征向量为

R是等式的答案
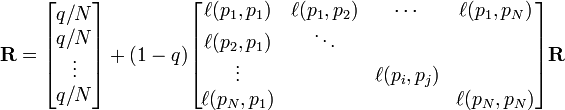
如果pj不链向pi, 而且对每个j都成立时,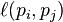 等于 0
等于 0
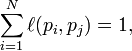
这项技术的主要缺點是旧的页面等级会比新页面高。因为即使是非常好的新页面也不会有很多上游链接,除非它是某个站点的子站点。
这就是PageRank需要多项算法结合的原因。PageRank似乎倾向于维基百科页面,在条目名称的搜索结果中总在大多数或者其他所有页面之前。原因主要是维基百科内相互的链接很多,并且有很多站点链入。
Google经常处罚恶意提高PageRank的行为,至於其如何区分正常的链接交换和不正常的链接堆积仍然是商业机密。
2009年10月14日,Google員工蘇珊·莫斯科(Susan Moskwa)確認該公司已自其網站管理員工具部分移除 PageRank。她對這部分移除的公告表示:「我们長久以來一直在告诫人們不应该过分注重 PageRank;很多網站站主似乎认为對他們來說得時時追蹤的網站最重要指标,而这簡直是個误解。」[2]然而在蘇珊確認後兩天, PageRank 仍舊在Google工具欄上顯示。
Baidu 百科
PageRank相关算法:
1.PageRank
基本思想:如果网页T存在一个指向网页A的连接,则表明T的所有者认为A比较重要,从而把T的一部分重要性得分赋予A。这个重要性得分值为:PR(T)/C(T)
其中PR(T)为T的PageRank值,C(T)为T的出链数,则A的PageRank值为一系列类似于T的页面重要性得分值的累加。
优点:是一个与查询无关的静态算法,所有网页的PageRank值通过离线计算获得;有效减少在线查询时的计算量,极大降低了查询响应时间。
不足:人们的查询具有主题特征,PageRank忽略了主题相关性,导致结果的相关性和主题性降低;另外,PageRank有很严重的对新网页的歧视。
2.Topic-Sensitive PageRank(主题敏感的PageRank)
基本思想:针对PageRank对主题的忽略而提出。核心思想:通过离线计算出一个PageRank向量集合,该集合中的每一个向量与某一主题相关,即计算某个页面关于不同主题的得分。主要分为两个阶段:主题相关的PageRank向量集合的计算和在线查询时主题的确定。
优点:根据用户的查询请求和相关上下文判断用户查询相关的主题(用户的兴趣)返回查询结果准确性高。
不足:没有利用主题的相关性来提高链接得分的准确性。
3.Hilltop
基本思想:与PageRank的不同之处:仅考虑专家页面的链接。主要包括两个步骤:专家页面搜索和目标页面排序。
优点:相关性强,结果准确。
不足:专家页面的搜索和确定对算法起关键作用,专家页面的质量决定了算法的准确性,而专家页面的质量和公平性难以保证;忽略了大量非专家页面的影响,不能反应整个Internet的民意;当没有足够的专家页面存在时,返回空,所以Hilltop适合对于查询排序进行求精。
那么影响google PageRank的因素有哪些呢?
1 与pr高的网站做链接:
2 内容质量高的网站链接
3 加入搜索引擎分类目录
4 加入免费开源目录
5 你的链接出现在流量大、知名度高、频繁更新的重要网站上
6 google对PDF格式的文件比较看重。
7 安装Google工具条
8 域名和tilte标题出现关键词与meta标签等
9 反向连接数量和反向连接的等级
10 Google抓取您网站的页面数量
11 导出链接数量
- Google Pangrank 算法
- PangRank算法到TextRank
- pangrank算法--PageRank算法并行实现
- google pagerank checksum算法
- Google的PageRank算法
- Google的多元化“算法”
- Google pagerank 算法
- Google地图数据算法
- Google Page Rank 算法
- PR GOOGLE算法概念
- Google Hilltop算法
- Google搜索引擎算法研究
- Google PageRank 算法
- Google PageRank 算法
- 一道google算法题
- Google 的 pagerank 算法
- .Google PageRank 算法
- Google 图片搜索算法
- 加入csdn一周岁
- 让ASP.Net HTML页面代码 清爽起来
- 测试文章
- QT4.3.3+VC6.0安装编译过程详解
- 2010.3.14 OA项目组工作报告
- Google Pangrank 算法
- 关于scrum敏捷开发(1)
- 相信自己,就是奇迹
- 这就是男人(一)
- 这就是男人 (续)
- 用手机做猫来上网
- Exhaustion of Natural Resources
- extern c作用
- 这就是男人(再续)


