《C安全编码标准》阅读有感及个人观点(1):PRE00-C
来源:互联网 发布:程序源码 编辑:程序博客网 时间:2024/05/01 08:35
规则建议条款:PRE00-C
条款建议内容:用内联函数或静态函数代替与函数相似的宏。
建议原因:与函数相似的宏有可能出现未定义状态导致出现危险。
具体例子:
#define CUBE(X) ( (X) * (X) * (X) )
……
int i=2;
int a=81 / CUBE(++i);
则展开宏之后,会变成:
int a=81/ ( (++i) * (++i) * (++i) );
结果会是多少呢?最重要的问题是( (++i) * (++i) * (++i) )的结果是?
先去看看编译器的答案:
VS 2008:125。
GCC:80。
Dev C++:80。
结果很奇怪,为何会这样呢,于是根据书本提示,查了EXP30-C,并查找ANSI C 99 6.5节,第2条:

翻译:在前一个与后一个序列点,一个对象所存储的值在一条表达式中最多只能被修改一次。另外,读取前一个值只能用于决定需要存储的值。(什么是序列点这个问题于ANSI C 99 6.5节第一条已经说明:表达式是一个操作符和操作数的序列,则言下之意,表达式中每一个非运算符的项,即变量等等就是一个序列点。)
即按照标准和书中的例子,某个变量在某条表达式中,对其运算的次数超过两次(也就是)都会是一种未定义的危险行为!
例如a[i++]=i,i= ++i+1这样的操作就具备相当的危险性,虽然一样是受运算符方向性和优先级限制,但由于该为未定义行为,即标准没强调某些运算顺序,可能因为编译器的语法树差别而产生结果相差!
而为了体现上边这些,我特意将( (++i) * (++i) * (++i) )变成了( (++i) * (++i) * (++i) * (++i) ),在不同编译器中进行了测试就验证了未定义操作在不同编译器上的语法树有不同情况的问题(把式子变为四个++i相乘,比三个更容易看出乘号间的运算顺序)。
结果:
VS 2008:
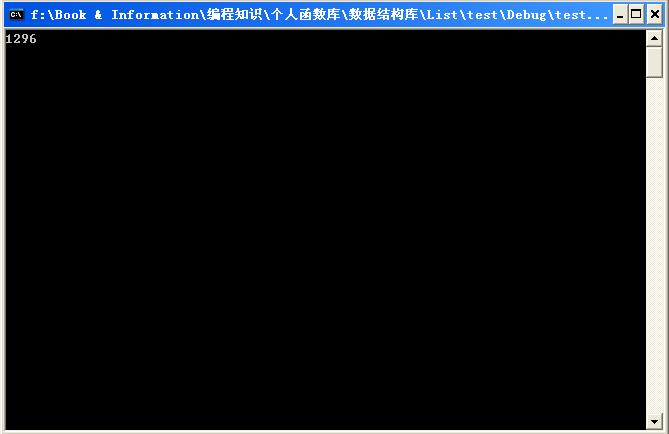
GCC:
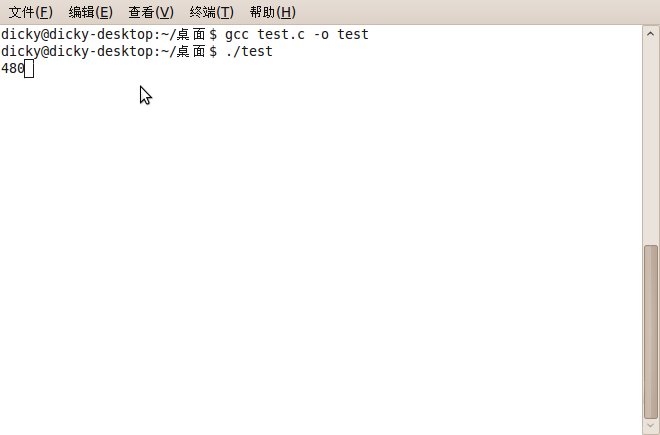
Dev C++也是480(因为Dev C++使用的编译内核为mingw,是GCC的WINDOWS移植版)。
从上边就可以猜出两个编译器的运算顺序差别,微软的是 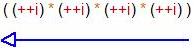
而GCC的语法顺序则是每遇到乘号先结合,就如 ,即6*(5*(4*4)),所以就得480,至于为何一开始是4*4,而不是3*4,这个也大概是寄存器与指令使用的问题!
而PRE00-C条款的提出正是为了这个原因,因为宏被替换后很容易就出现些非定义的操作,而内联函数则更像一个函数,被函数调用时,其参数的副作用只执行一次!
总结与个人观点:
1、内联函数与宏定义的对比:
(1)实现机制:
宏定义由预处理器实现,代码中某处预到宏,则根据宏定义中的内容进行实际替换。因为这样,
以往经常有人经常定义一点类似函数的宏,这样做,调用时不用经过函数的参数压栈,时间效率很高,所以比较
受欢迎,但存在一定危险性,就如上边举的例子。
内联函数则是保存于符号表,使用时直接展开,同样是不用经过参数压栈等问题,所以时间效率同样会很
高。但与宏定义的差别是,其虽然也是用时才展开,但它是一组真正的函数,其参数等等正确性受编译器检查限
制,安全性较高,而且如上边所讲,参数的副作用只执行一次,大大降低出现未定义危险行为的情况!
(2)内联函数的适用范围:
因为内联函数的出现某程度上是为了取代宏定义,因为其安全性比较好,而且时间效率很高,但内联函数并非
哪里都合适用,因为其在调用时会具体展开,而且是保存于符号表的,某程度上度,就是一种用空间换时间的措
施,因此某些情况下并不适合用,例如,函数体内出现递归、迭代等等这类消耗比较多空间的算法,及功能
实现代码行数较多函数,当展开后就占用着比较大的空间,所以不适合用!
当然,这个条款是非必要的,有某些情况是例外的:
书本第8页就讲了一些相关的条款,其中相关的书本已经有例子,只的PRE00-EX1和4是没有的,1这个意思可能是对应C++或是其它的或是我还没透彻了解到,但令我联想起一个,宏作用域问题,在C和C++中可以通过宏作用域来限制某些宏的作用,而内联函数在C++中,作用域也可以是类内的,但是C中函数作用域就是一个比较麻烦的问题,这是内联函数相对于宏不足的一个方面。
另外,第四点,这个通用型函数,其实想想之前那个 #define offsetof(type,member) ((size_t) &((TYPE *)0)->MEMBER),这就正正是一个典型了,书本MEM02-C也是个非常值得学习的例子!
除了以上书本例子之外,还有的就是上边提到的一些比较耗内存的算法及函数功能实现代码超过5行的,要使用内联就要注意了。
值得注意: 因为内联函数是一个建议,所以编译器是选择性执行的,也就是说声明了是内联函数的,有机会是内联函数,但也有机会不是,通常只有类内的函数肯定会是内联函数。因为有时可能间接地函数进行了递归方式的调用及等等问题,而内联函数本身就是空间换时间,编译器为免陷入某些无穷无尽地需要空间的情况下,是会自动转成非内联函数的。否则如果内联出现了问题不能内联,而直接将代码嵌入某处,轻则代码膨胀,重则就会出现重定义等等问题!所以,使用内联函数尽量将代码保持在5等下,复杂功能不要用内联函数,在写内联函数时也尽量考虑清楚作用域!
最后建议:
(1)尽可能用内联函数取代宏。
(2)宏定义尽量不要搞得太复杂,以免导致在意想不到的情况下出现未定义操作!
(3)编码时尽量使用简单表达式,这样对代码可读性、降低危险性及代码执行效率都有一定好处!
(4)在用内联函数时,请认真地考虑作用域,尽量避免重复调用及过多地间接性的调用!(这个万分注意,危险!)
- 《C安全编码标准》阅读有感及个人观点(1):PRE00-C
- C标准库的阅读(1)
- C安全编码--预处理
- C安全编码--预处理
- C/C++编码标准(转载)
- C++/CLI中的安全编码
- C安全编码标准:开发安全、可靠、稳固系统的98条规则(原书第2版)——互动出版网
- 阅读C标准库的个人体会
- 学好C/C++的办法(个人观点)
- 学好C/C++的办法(个人观点)
- 阅读《C 风格的内存分配程序》有感
- 工作有感!(C开发)
- C标准库(1)
- Java安全编码标准
- SEI CERT C安全编码-信号(SIG)
- C/C++标准的编码风格举例
- C语言编码风格和标准
- c语言安全编码建议一
- Eric Raymond:几种计算机语言的评价
- 常用的SQL
- setTimeout与setInterval
- 体验Windows 7新特性之基于VHD虚拟磁盘文件启动计算机
- 再议UTF-16的编码
- 《C安全编码标准》阅读有感及个人观点(1):PRE00-C
- MyEclipse 6.5 异常 java.lang.UnsupportedClassVersionError: Bad version number in .class file
- ajax中的xmlhttprequest对象介绍
- C 与C++中的异常处理
- ajax题目
- 最近读书总结和计划。。
- 通达信目录文件结构及说明
- 2010.3.22 晴 星期一
- Tcp发送或接收数据不全


