手把手教你SQL Server2008性能数据收集
来源:互联网 发布:火车头7.6 数据库 编辑:程序博客网 时间:2024/04/29 18:59
简介:通过这个动手实验室,您可以了解到:了解与性能数据收集相关的组件及术语;创建并配置管理数据仓库;管理数据收集的类型及间隔;对收集上来的数据进行分析;创建自定义的数据收集类型。
动手实验室操作脚本
1. 创建管理数据仓库
在SQL Server 2008中有很多组件可以进行性能数据收集。为了设定收集数据的类型以及收集计划,数据收集器需要使用管理数据仓库。管理数据仓库也是一个关系型数据库,但在创建该数据库时很多默认设置需要进行修改,在我们后面的实验中将深入讨论。理想状态下,管理数据仓库最好和生产环境的数据库位于不同的服务器上,以便实现更好的性能。
数据收集所针对的目标是SQL Server 的实例,每一个实例都有收集组与之相对应,其中收集组指特定的收集类型,例如磁盘和查询统计。数据收集依靠SQL Server Agent 或SSIS按照计划来执行,因此作业和计划都会存储在msdb数据库中。管理数据仓库的角色就是存储数据、一些聚合值、以及针对系统分析而生成的历史信息。
在第一个练习当中,我们将安装管理数据仓库:
1. 打开 SQL Server Management Studio.
依次点击Start | All Programs | Microsoft SQL Server 2008 | SQL Server Management Studio
2. SQL Server Management Studio 打开以后,在Connect to Server 对话框中,输入如下信息,然后点击Connect:
Server type: Database Engine
Server name: CHICAGO/CONFIGSERVER
Authentication: Windows Authentication
3. 在Object Explorer中,依次展开Management 和Data Collection.
4. 右键点击Data Collection 然后点击Configure Management Data Warehouse.
5. 点击Next.
6. 在配置Management Data Warehouse 时需要做两件事:创建SQL Server 数据库用于存储收集上来的数据计数;指定缓存文件夹,数据在加载到管理数据仓库之前会临时被缓存在这里。对于收集操作比较频繁的数据集,所收集的数据会在本地缓存,然后再批量导入到管理数据仓库,从而降低了网络负载并提高了数据收集时的性能。
7. 在Configure Management Data Warehouse Wizard 页面中,选择Create or upgrade a management data warehouse 然后点击Next.
8. 服务器名称会自动填写
注意:你必须有足够的权限,以便在服务器中创建管理数据仓库。更多详细信息,请参考SQL Server 2008 Books Online 中的CREATE DATABASE (Transact-SQL) 以及Data Collector Security 部分
9. 点击New新建管理数据仓库。
按照下图所示进行设置。即将数据库名称设置为ManagementDW:
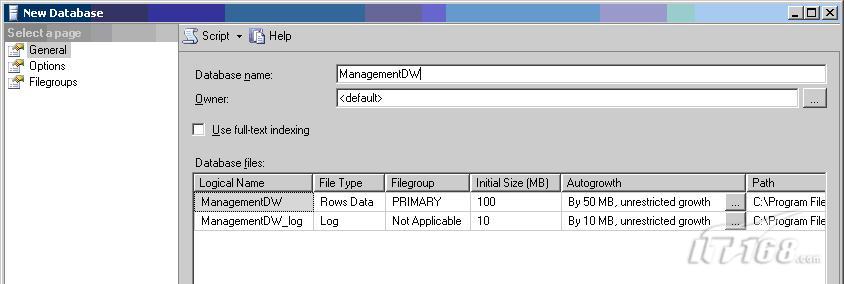
10. 点击 OK 接收默认设置并创建ManagementDW 数据库。注意:即便在后面的步骤中取消向导,该数据库也将在该步骤中创建
11. 点击Next.
12. 在Map Users and Logins 对话框中将要设置管理数据仓库如何使用以及被谁所使用。在此实验中,我们将使用Administrator登陆帐号对数据仓库进行读写,该帐号已经对此数据库有了相应权限。在一些拥有多个DBA及操作员的复杂环境中,我们需要在此进行详细设置。
13. 点击 Next.
14. 在Complete the Wizard 对话框中,点击Finish 完成管理数据仓库的创建
15. 完成后点击Close 退出Configure Management Data Warehouse Wizard.
16. 返回到Object Explorer 中,可以看到:
• ManagementDW 数据库已经成功创建
• ManagementDW 数据库的还原模式为SIMPLE (数据库属性的options中可以看到)
• ManagementDW 的数据文件大小为100MB 且日志文件的大小为10MB
• ManagementDW 数据库中包含两个架构:core 架构和snapshot 架构,每个架构中都包含很多对象
17. 下面我们将在CHICAGO/SQLDEV01 实例中配置数据收集,并使用刚刚在CHICAGO/CONFIGSERVER 实例中创建的管理数据仓库
18. 在 SQL Server Management Studio的Object Explorer中点击Connect, 然后点击Database Engine…. 在Connect to Server 对话框中,输入如下信息并点击Connect:
Server type: Database Engine
Server name: CHICAGO/SQLDEV01
Authentication: Windows Authentication
19. 在 Object Explorer 中依次展开Management 节点和Data Collection 节点
20. 右键点击Data Collection 然后点击Configure Management Data Warehouse.
21. 点击Next
22. 在配置Management Data Warehouse 时需要做两件事:创建SQL Server 数据库用于存储收集上来的数据计数;指定缓存文件夹,数据在加载到管理数据仓库之前会临时被缓存在这里。对于收集操作比较频繁的数据集,所收集的数据会在本地缓存,然后再批量导入到管理数据仓库,从而降低了网络负载并提高了数据收集时的性能
23. 在Configure Management Data Warehouse Wizard 页面中,选择Set up data collection 并点击Next.
24. 在Configure Management Data Warehouse Storage 对话框中,选择CHICAGO/CONFIGSERVER 作为Server name: 选择ManagementDW 作为Database name:.
25. 缓存文件夹默认将采用%TEMP% 或%TMP% 目录。在真实环境中建议将缓存文件夹放在不同的磁盘中。在此实验中,我们采用默认设置,即保留Cache directory 为空
26. 点击Next.
27. 在Complete the Wizard 对话框中,点击Finish 完成管理数据仓库的创建。
28. 完成后点击Close 退出Configure Management Data Warehouse Wizard.
29. 关闭所有打开的窗口,保持SQL Server Management Studio处于打开状态
30. 继续进行下面的实验
在此实验中,您将查看系统支持的数据收集类型和收集计划,并配置其属性;任务:通过管理数据仓库向导查看系统收集组及其状态。
管理数据仓库配置完成后,向导不仅仅会创建数据库(即ManagementDW),同时还将自动启动SQL Server Agent 作业来收集并更新系统数据收集组
1. 在CHICAGO/SQLDEV01 实例中返回Object Explorer 并依次展开Management, Data Collection, System Data Collection Sets. 此时可以看到三种系统数据收集组:Disk Usage, Query Statistics, 以及 Server Activity.
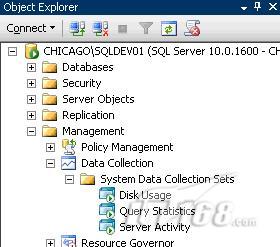
右键点击Disk Usage然后点击Properties. Disk Usage统计数据的完整属性将通过三个选项卡显示,即General, Uploads 以及Description.点击Description选项卡可以看到: Collects data about disk and log usage for all databases. 此描述信息并不是很详细,但可以让我们快速了解到磁盘使用的统计信息;这些信息针对实例中的所有数据库的数据文件和日志文件。
4. 3. 点击Uploads 选项卡可以看到所有信息均为灰色,因为这些特殊的数据集都采用非缓存模式收集。在非缓存模式中数据的收集和上传通过相同的代理作业进行处理。因此Uploads选项卡中的信息对于此收集组来说没有实际意义。非缓存模式对于相对负载较轻或数据集收集操作不是很频繁的情况下很适用
5. 4. 最后,点击General 选项卡,可以看到该数据收集的特定属性:
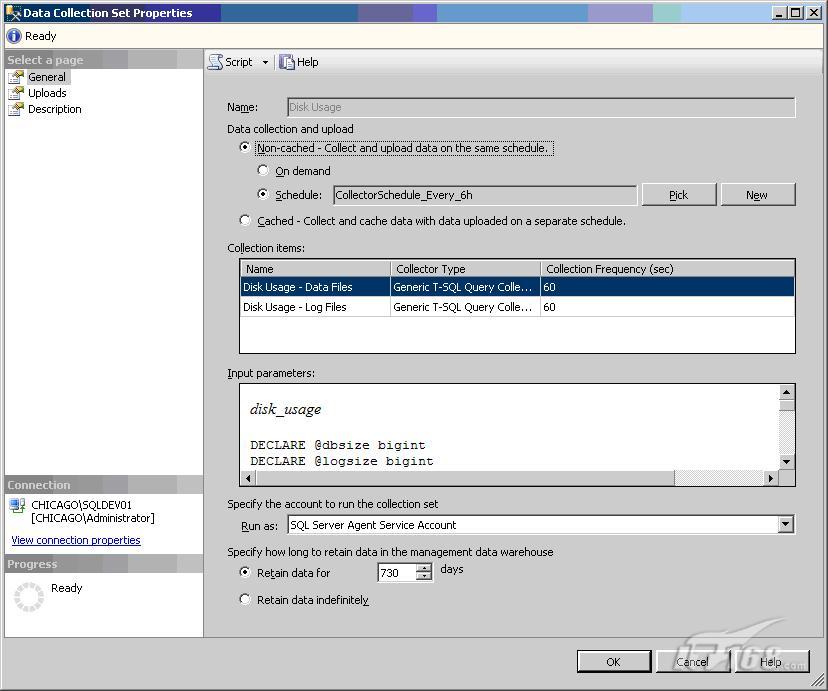
7. Data collection and upload
8. 在这里可以将Data collection and upload 更改为缓存模式。但由于我们实验中的数据收集操作并不是很频繁,因此不需要进行缓存。如果数据收集操作很复杂且很频繁,则建议选择缓存模式。理想状态下,缓存将只对进行收集的本地服务器性能产生影响,然后再将收集上来的数据慢慢上传到管理数据仓库。例如,针对特定数值的收集频率可能为30-60秒,但上传频率可以设置为30或60分钟。
9. Schedule:
点击 Pick 可以看到可用的计划。在这里可以看到我们选择的计划是occur every day every 6 hour(s) between 12:00:00 AM and 11:59:59 PM 并且使用该计划的作业数为1.如果设置多台服务器采用相同的计划进行数据收集并将数据上传到相同的管理数据仓库,则建议将作业的启动时间岔开,这样可以更好的平衡管理数据仓库的负载。
Collection items
这里可以看到两个项目:Disk Usage – Data Files 和Disk Usage – Log Files. 每一个收集器的类型均为 “Generic T-SQL Query Collector Type” ,因此在Input parameters 中的T-SQL脚本将用于执行这些收集项目
Disk Usage – Data Files
选择Disk Usage – Data Files 行,然后在Input parameters 文本框中将显示下列代码:
--disk_usage
DECLARE @dbsize bigint
DECLARE @logsize bigint
DECLARE @ftsize bigint
DECLARE @reservedpages bigint
DECLARE @pages bigint
DECLARE @usedpages bigint
SELECT @dbsize = SUM(convert(bigint,case
when type = 0 then size else 0 end))
,@logsize = SUM(convert(bigint,case
when type = 1 then size else 0 end))
,@ftsize = SUM(convert(bigint,case
when type = 4 then size else 0 end))
FROM sys.database_files
SELECT @reservedpages = SUM(a.total_pages)
,@usedpages = SUM(a.used_pages)
,@pages = SUM(CASE
WHEN it.internal_type IN (202,204)
THEN 0
WHEN a.type != 1
THEN a.used_pages
WHEN p.index_id < 2
THEN a.data_pages
ELSE 0
END)
FROM sys.partitions p
JOIN sys.allocation_units a
ON p.partition_id = a.container_id
LEFT JOIN sys.internal_tables it
ON p.object_id = it.object_id
SELECT @dbsize as 'dbsize',
@logsize as 'logsize',
@ftsize as 'ftsize',
@reservedpages as 'reservedpages',
@usedpages as 'usedpages',
@pages as 'pages'
选中这些代码并将其复制到新建的查询窗口中,首先注释掉第一行(disk_usage),然后在 master 数据库中执行这段代码
查询结果如下图所示:

请注意上述查询结果只针对一个数据库,而通过SQL Server Agent 作业执行时将收集并上传所有数据库的数据集
Disk Usage – Log Files
选中Disk Usage – Log Files 然后查看Input parameters 文本框中的相关代码
注意:在此版本中,针对Disk Usage – Log Files 的数据收集操作是通过执行DBCC SQLPERF (logspace)语句而实现的
Specify the account to run the collection set
保留默认设置SQL Server Agent Service Account 即可
Specify how long to retain data in the management data warehouse
Disk Usage 的数据收集并不会产生大量的数据,默认的保留期限是730 天。(假设系统有10个数据库,则在730天中将会有29200行的数据产生。即每天收集4次,则730天中共插入4 x 10 x 730 = 29200 行)
如果数据库数量很多且收集频率很高,则可以将保留期限适当减少
5. 连接到CHICAGO/CONFIGSERVER 实例中,新建查询窗口并直接查询ManagementDW.snapshots.disk_usage 和ManagementDW.snapshots.log_usage 这两个表:
SELECT * FROM ManagementDW.snapshots.disk_usage
SELECT * FROM ManagementDW.snapshots.log_usage
6. 除了直接查询数据集,还可以在Object Explorer 中通过报表来进行查看,下一个练习当中我们将使用该功能。出于实验目的,在此我们还需要修改一些收集属性,加大进行数据收集的频率,以便更清晰的看到结果。
在这里我们将收集频率调整为15分钟。在真正的生产环境中,不建议这样设置,否则将影响msdb 数据库以及管理数据仓库的性能。
7. 修改System Data Collection Sets 收集属性的方法有很多。根据缓存模式的区别,每个收集组都有1个或2个作业,例如Server Activity采用缓存模式,有2个作业;而Disk Usage 和Query Statistics 则采用非缓存模式,因此只有1个作业。为了提高收集和上传的频率,我们可以更改作业计划。
重要提示:在进行充分测试以前,不要在生产环境中更改收集频率
8. 在CHICAGO/SQLDEV01 实例和 CHICAGO/CONFIGSERVER 实例的Object Explorer 中,依次展开SQL Server Agent 节点和Jobs 节点,查看当前的作业
9. 每个SQL Server 实例中至少会有一个作业,用于进行系统健康的监控。详细信息,请参考下面链接中的文章:http://blogs.msdn.com/psssql/archive/2008/07/15/supporting-sql-server-2008-the-system-health-session.aspx
10. 其它作业是我们手动创建的(目前在CHICAGO/SQLDEV01 实例中有5个用于收集数据的实例,在CHICAGO/CONFIGSERVER 实例中有一个作业用于清除历史记录,如下表所示
Data Collection Set TypeCached v. Non-cachedJob Collection or Upload (or both)Current Job NameDescriptive Job Name
(change to)
Disk UsageNon-cachedBothcollection_set_1_noncached_collect_and_uploadDiskUsage_noncached
Query StatisticsCachedCollectioncollection_set_2_collectionQueryStats_collection
Query StatisticsCachedUploadcollection_set_2_uploadQueryStats_upload
Server ActivityCachedCollectioncollection_set_3_collectionServerActivity_collection
Server ActivityCachedUploadcollection_set_3_ uploadServiceActivity_upload
根据上述表格,将每个作业的名称改为更具描述性的名称,即上表的最后一列
11. 在CHICAGO/SQLDEV01 实例中,右键点击SQL Server Agent 然后依次点击New 和Schedule…
12. 在New Job Schedule 对话框,输入JobSchedule_Every_1min 作为作业名称,然后如下图所示进行设置:

13. 确定作业将在午夜每隔1分钟执行一次,然后点击 OK
14. 将这个计划添加到下面两个作业中:DiskUsage_noncached 和QueryStats_upload. 右键点击作业名称,然后点击Properties, 在Schedules 选项卡中,点击Pick… 并选择JobSchedule_Every_1min 计划。为ServerActivity_Upload 选择CollectorSchedule_Every_5min 计划。
重要提示:在生产环境中设置收集频率过高的时候要特别小心
任务:为数据收集和分析操作而生成相关信息
此任务并不复杂,但第一个批处理文件需要执行将近5分钟的时间,第二个批处理文件将打开多个SQLCMD 命令行窗口,直到手动停止。这些脚本在进行分析前都需要时间。因此我们先将它们启动,直到后面的步骤再将其停止。另外,我们不需要关注这些脚本如何运行也不需要等待它们执行完毕。
15. 运行批处理文件。打开我的电脑,然后打开下面的文件夹:
C:/Manageability Labs/Performance Data Collection
16. 双击GenerateData.cmd 文件。该脚本将执行将近5分钟的时间直至完成
17. 双击GenerateActivity.cmd 文件。该脚本将循环执行,直到我们在后面的练习中关闭该窗口
任务:查看Server Activity 和 Query Statistics 这两个系统数据收集组的代码、设计、以及参数
18. 返回到CHICAGO/SQLDEV01 实例的Object Explorer 并依次展开Management, Data Collection, 以及System Data Collection Sets. 在此可以看到三个系统数据收集组:Disk Usage, Query Statistics, and Server Activity.
19. 右键点击Query Statistics 然后点击Properties. 注意该收集组和Disk Usage 数据收集组属性的区别:
相同点
• 两者均为非缓存模式
• 两者在Uploads 选项卡中均为灰色
• 两者均通过SQL Server Agent 运行
不同点
• Disk Usage 数据收集组通过T-SQL 语句实现,在Input Parameters 中可以看到相关语句。而Query Statistics 则通过 内部的 “Query Activity Collector Type” 来处理,且无法直接查看。该数据收集组所收集的内容在Description 选项卡中可以看到:Collects query statistics, sql text and plans of most performance-affecting queries and normalized query text. Allows to analyze details of the worst performing queries and correlates them with overall SQL Server activity.
• Disk Usage 的保留期限是730 天,而Query Statistics 只有14天
20. 右键点击Server Activity 然后点击Properties. 注意与上述两个数据收集组(Disk Usage 和Query Statistics)的区别:
不同点
• Server Activity 采用缓存模式,因此有两个相关作业,一个用于收集,另一个用于上传
• Uploads 选项卡不是灰色显示,数据收集之后会首先进行缓存,然后每隔15分钟批量上传一次。
• 21. 删除DiskUsage_noncached, QueryStatistics_noncached 和ServerActivity_Uploads 中多余的计划,只保留JobSchedule_Every_1min 计划。右键点击每个作业,然后点击Properties,选中 Schedules 页面。点击Remove…
22. 不要关闭SQLCMD 窗口
23. 在SQL Server Management Studio 中关闭所有打开的查询窗口,不要关闭SQL Server Management Studio
3. 分析系统数据收集组
在此练习中,我们将分析系统所支持的数据收集组,并查看其中所提供的信息。
任务:查看并分析Disk Usage 的趋势
1. 在Object Explorer 中右键点击Management, 然后点击Data Collection. 依次点击Reports, Management Data Warehouse, Disk Usage Summary.
1)可以看到每个数据库的初始大小,当前大小,以及平均每天的增量均会显示出来
2. 2)点击AdventureWorks2008 数据文件的趋势图,可以看到该数据库的详细信息:
查看Disk Usage Collection Set 的输出信息,从而可以了解到数据库的增长速度是否超过了预期值
2. 如果数据库的增长速度超过预期值,我们还可以双击该数据库中的数据表,以便查看最为消耗资源的数据表是哪些
3. 3. 在Object Explorer 中展开Databases 然后右键点击AdventureWorks2008并点击Reports, 从而查看Disk Usage by Top Tables 的标准报表。在Reports 菜单中,依次点击Standard Reports, Disk Usage by Top Tables.
任务:查看并分析Query Statistics 的趋势
当这些查询运行时,系统处于非常忙碌的状态,因此会产生大量CPU负载
5. 在Object Explorer 中,依次展开Management, Data Collection, Reports, Management Data Warehouse, 然后右键点击Query Statistics History
6. 点击Rank Queries by:中的Duration链接,查看Most Expensive Queries by Total Duration
在Most Expensive Queries by Total Duration 中点击Query 1,可以看到详细信息,包括哪些查询最耗资源、不同查询计划的开销等。
7. 在Most Expensive Queries by Total Duration 中点击Query 1,可以看到详细信息,包括哪些查询最耗资源、不同查询计划的开销等。
8. 此外,我们还可以查看查询计划的详细信息:
9. 在Object Explorer 中,依次展开节点Management, Data Collection, Reports, Management Data Warehouse并右键点击Server Activity
11. 注意Server Activity 分为CPU, Memory, Disk I/O, Network, Waits 以及Activity 几个部分,每个部分我们都可以查看到更为详细的信息
12. 任意点击SQL Server Waits 中的某个竖条,可以查看到不同的等待状态;
13. 展开Lock 节点查看详细信息。在Lock 节点中我们可以打开SQL Server Blocking 页面:
13. 点击Chain # 下的1 可以看到更为详细的信息
14. 关闭所有SQLCMD 窗口
15. 退出SQL Server Management Studio
1. 创建管理数据仓库
在SQL Server 2008中有很多组件可以进行性能数据收集。为了设定收集数据的类型以及收集计划,数据收集器需要使用管理数据仓库。管理数据仓库也是一个关系型数据库,但在创建该数据库时很多默认设置需要进行修改,在我们后面的实验中将深入讨论。理想状态下,管理数据仓库最好和生产环境的数据库位于不同的服务器上,以便实现更好的性能。
数据收集所针对的目标是SQL Server 的实例,每一个实例都有收集组与之相对应,其中收集组指特定的收集类型,例如磁盘和查询统计。数据收集依靠SQL Server Agent 或SSIS按照计划来执行,因此作业和计划都会存储在msdb数据库中。管理数据仓库的角色就是存储数据、一些聚合值、以及针对系统分析而生成的历史信息。
在第一个练习当中,我们将安装管理数据仓库:
1. 打开 SQL Server Management Studio.
依次点击Start | All Programs | Microsoft SQL Server 2008 | SQL Server Management Studio
2. SQL Server Management Studio 打开以后,在Connect to Server 对话框中,输入如下信息,然后点击Connect:
Server type: Database Engine
Server name: CHICAGO/CONFIGSERVER
Authentication: Windows Authentication
3. 在Object Explorer中,依次展开Management 和Data Collection.
4. 右键点击Data Collection 然后点击Configure Management Data Warehouse.
5. 点击Next.
6. 在配置Management Data Warehouse 时需要做两件事:创建SQL Server 数据库用于存储收集上来的数据计数;指定缓存文件夹,数据在加载到管理数据仓库之前会临时被缓存在这里。对于收集操作比较频繁的数据集,所收集的数据会在本地缓存,然后再批量导入到管理数据仓库,从而降低了网络负载并提高了数据收集时的性能。
7. 在Configure Management Data Warehouse Wizard 页面中,选择Create or upgrade a management data warehouse 然后点击Next.
8. 服务器名称会自动填写
注意:你必须有足够的权限,以便在服务器中创建管理数据仓库。更多详细信息,请参考SQL Server 2008 Books Online 中的CREATE DATABASE (Transact-SQL) 以及Data Collector Security 部分
9. 点击New新建管理数据仓库。
按照下图所示进行设置。即将数据库名称设置为ManagementDW:
10. 点击 OK 接收默认设置并创建ManagementDW 数据库。注意:即便在后面的步骤中取消向导,该数据库也将在该步骤中创建
11. 点击Next.
12. 在Map Users and Logins 对话框中将要设置管理数据仓库如何使用以及被谁所使用。在此实验中,我们将使用Administrator登陆帐号对数据仓库进行读写,该帐号已经对此数据库有了相应权限。在一些拥有多个DBA及操作员的复杂环境中,我们需要在此进行详细设置。
13. 点击 Next.
14. 在Complete the Wizard 对话框中,点击Finish 完成管理数据仓库的创建
15. 完成后点击Close 退出Configure Management Data Warehouse Wizard.
16. 返回到Object Explorer 中,可以看到:
• ManagementDW 数据库已经成功创建
• ManagementDW 数据库的还原模式为SIMPLE (数据库属性的options中可以看到)
• ManagementDW 的数据文件大小为100MB 且日志文件的大小为10MB
• ManagementDW 数据库中包含两个架构:core 架构和snapshot 架构,每个架构中都包含很多对象
17. 下面我们将在CHICAGO/SQLDEV01 实例中配置数据收集,并使用刚刚在CHICAGO/CONFIGSERVER 实例中创建的管理数据仓库
18. 在 SQL Server Management Studio的Object Explorer中点击Connect, 然后点击Database Engine…. 在Connect to Server 对话框中,输入如下信息并点击Connect:
Server type: Database Engine
Server name: CHICAGO/SQLDEV01
Authentication: Windows Authentication
19. 在 Object Explorer 中依次展开Management 节点和Data Collection 节点
20. 右键点击Data Collection 然后点击Configure Management Data Warehouse.
21. 点击Next
22. 在配置Management Data Warehouse 时需要做两件事:创建SQL Server 数据库用于存储收集上来的数据计数;指定缓存文件夹,数据在加载到管理数据仓库之前会临时被缓存在这里。对于收集操作比较频繁的数据集,所收集的数据会在本地缓存,然后再批量导入到管理数据仓库,从而降低了网络负载并提高了数据收集时的性能
23. 在Configure Management Data Warehouse Wizard 页面中,选择Set up data collection 并点击Next.
24. 在Configure Management Data Warehouse Storage 对话框中,选择CHICAGO/CONFIGSERVER 作为Server name: 选择ManagementDW 作为Database name:.
25. 缓存文件夹默认将采用%TEMP% 或%TMP% 目录。在真实环境中建议将缓存文件夹放在不同的磁盘中。在此实验中,我们采用默认设置,即保留Cache directory 为空
26. 点击Next.
27. 在Complete the Wizard 对话框中,点击Finish 完成管理数据仓库的创建。
28. 完成后点击Close 退出Configure Management Data Warehouse Wizard.
29. 关闭所有打开的窗口,保持SQL Server Management Studio处于打开状态
30. 继续进行下面的实验
在此实验中,您将查看系统支持的数据收集类型和收集计划,并配置其属性;任务:通过管理数据仓库向导查看系统收集组及其状态。
管理数据仓库配置完成后,向导不仅仅会创建数据库(即ManagementDW),同时还将自动启动SQL Server Agent 作业来收集并更新系统数据收集组
1. 在CHICAGO/SQLDEV01 实例中返回Object Explorer 并依次展开Management, Data Collection, System Data Collection Sets. 此时可以看到三种系统数据收集组:Disk Usage, Query Statistics, 以及 Server Activity.
右键点击Disk Usage然后点击Properties. Disk Usage统计数据的完整属性将通过三个选项卡显示,即General, Uploads 以及Description.点击Description选项卡可以看到: Collects data about disk and log usage for all databases. 此描述信息并不是很详细,但可以让我们快速了解到磁盘使用的统计信息;这些信息针对实例中的所有数据库的数据文件和日志文件。
4. 3. 点击Uploads 选项卡可以看到所有信息均为灰色,因为这些特殊的数据集都采用非缓存模式收集。在非缓存模式中数据的收集和上传通过相同的代理作业进行处理。因此Uploads选项卡中的信息对于此收集组来说没有实际意义。非缓存模式对于相对负载较轻或数据集收集操作不是很频繁的情况下很适用
5. 4. 最后,点击General 选项卡,可以看到该数据收集的特定属性:
7. Data collection and upload
8. 在这里可以将Data collection and upload 更改为缓存模式。但由于我们实验中的数据收集操作并不是很频繁,因此不需要进行缓存。如果数据收集操作很复杂且很频繁,则建议选择缓存模式。理想状态下,缓存将只对进行收集的本地服务器性能产生影响,然后再将收集上来的数据慢慢上传到管理数据仓库。例如,针对特定数值的收集频率可能为30-60秒,但上传频率可以设置为30或60分钟。
9. Schedule:
点击 Pick 可以看到可用的计划。在这里可以看到我们选择的计划是occur every day every 6 hour(s) between 12:00:00 AM and 11:59:59 PM 并且使用该计划的作业数为1.如果设置多台服务器采用相同的计划进行数据收集并将数据上传到相同的管理数据仓库,则建议将作业的启动时间岔开,这样可以更好的平衡管理数据仓库的负载。
Collection items
这里可以看到两个项目:Disk Usage – Data Files 和Disk Usage – Log Files. 每一个收集器的类型均为 “Generic T-SQL Query Collector Type” ,因此在Input parameters 中的T-SQL脚本将用于执行这些收集项目
Disk Usage – Data Files
选择Disk Usage – Data Files 行,然后在Input parameters 文本框中将显示下列代码:
--disk_usage
DECLARE @dbsize bigint
DECLARE @logsize bigint
DECLARE @ftsize bigint
DECLARE @reservedpages bigint
DECLARE @pages bigint
DECLARE @usedpages bigint
SELECT @dbsize = SUM(convert(bigint,case
when type = 0 then size else 0 end))
,@logsize = SUM(convert(bigint,case
when type = 1 then size else 0 end))
,@ftsize = SUM(convert(bigint,case
when type = 4 then size else 0 end))
FROM sys.database_files
SELECT @reservedpages = SUM(a.total_pages)
,@usedpages = SUM(a.used_pages)
,@pages = SUM(CASE
WHEN it.internal_type IN (202,204)
THEN 0
WHEN a.type != 1
THEN a.used_pages
WHEN p.index_id < 2
THEN a.data_pages
ELSE 0
END)
FROM sys.partitions p
JOIN sys.allocation_units a
ON p.partition_id = a.container_id
LEFT JOIN sys.internal_tables it
ON p.object_id = it.object_id
SELECT @dbsize as 'dbsize',
@logsize as 'logsize',
@ftsize as 'ftsize',
@reservedpages as 'reservedpages',
@usedpages as 'usedpages',
@pages as 'pages'
选中这些代码并将其复制到新建的查询窗口中,首先注释掉第一行(disk_usage),然后在 master 数据库中执行这段代码
查询结果如下图所示:
请注意上述查询结果只针对一个数据库,而通过SQL Server Agent 作业执行时将收集并上传所有数据库的数据集
Disk Usage – Log Files
选中Disk Usage – Log Files 然后查看Input parameters 文本框中的相关代码
注意:在此版本中,针对Disk Usage – Log Files 的数据收集操作是通过执行DBCC SQLPERF (logspace)语句而实现的
Specify the account to run the collection set
保留默认设置SQL Server Agent Service Account 即可
Specify how long to retain data in the management data warehouse
Disk Usage 的数据收集并不会产生大量的数据,默认的保留期限是730 天。(假设系统有10个数据库,则在730天中将会有29200行的数据产生。即每天收集4次,则730天中共插入4 x 10 x 730 = 29200 行)
如果数据库数量很多且收集频率很高,则可以将保留期限适当减少
5. 连接到CHICAGO/CONFIGSERVER 实例中,新建查询窗口并直接查询ManagementDW.snapshots.disk_usage 和ManagementDW.snapshots.log_usage 这两个表:
SELECT * FROM ManagementDW.snapshots.disk_usage
SELECT * FROM ManagementDW.snapshots.log_usage
6. 除了直接查询数据集,还可以在Object Explorer 中通过报表来进行查看,下一个练习当中我们将使用该功能。出于实验目的,在此我们还需要修改一些收集属性,加大进行数据收集的频率,以便更清晰的看到结果。
在这里我们将收集频率调整为15分钟。在真正的生产环境中,不建议这样设置,否则将影响msdb 数据库以及管理数据仓库的性能。
7. 修改System Data Collection Sets 收集属性的方法有很多。根据缓存模式的区别,每个收集组都有1个或2个作业,例如Server Activity采用缓存模式,有2个作业;而Disk Usage 和Query Statistics 则采用非缓存模式,因此只有1个作业。为了提高收集和上传的频率,我们可以更改作业计划。
重要提示:在进行充分测试以前,不要在生产环境中更改收集频率
8. 在CHICAGO/SQLDEV01 实例和 CHICAGO/CONFIGSERVER 实例的Object Explorer 中,依次展开SQL Server Agent 节点和Jobs 节点,查看当前的作业
9. 每个SQL Server 实例中至少会有一个作业,用于进行系统健康的监控。详细信息,请参考下面链接中的文章:http://blogs.msdn.com/psssql/archive/2008/07/15/supporting-sql-server-2008-the-system-health-session.aspx
10. 其它作业是我们手动创建的(目前在CHICAGO/SQLDEV01 实例中有5个用于收集数据的实例,在CHICAGO/CONFIGSERVER 实例中有一个作业用于清除历史记录,如下表所示
Data Collection Set TypeCached v. Non-cachedJob Collection or Upload (or both)Current Job NameDescriptive Job Name
(change to)
Disk UsageNon-cachedBothcollection_set_1_noncached_collect_and_uploadDiskUsage_noncached
Query StatisticsCachedCollectioncollection_set_2_collectionQueryStats_collection
Query StatisticsCachedUploadcollection_set_2_uploadQueryStats_upload
Server ActivityCachedCollectioncollection_set_3_collectionServerActivity_collection
Server ActivityCachedUploadcollection_set_3_ uploadServiceActivity_upload
根据上述表格,将每个作业的名称改为更具描述性的名称,即上表的最后一列
11. 在CHICAGO/SQLDEV01 实例中,右键点击SQL Server Agent 然后依次点击New 和Schedule…
12. 在New Job Schedule 对话框,输入JobSchedule_Every_1min 作为作业名称,然后如下图所示进行设置:
13. 确定作业将在午夜每隔1分钟执行一次,然后点击 OK
14. 将这个计划添加到下面两个作业中:DiskUsage_noncached 和QueryStats_upload. 右键点击作业名称,然后点击Properties, 在Schedules 选项卡中,点击Pick… 并选择JobSchedule_Every_1min 计划。为ServerActivity_Upload 选择CollectorSchedule_Every_5min 计划。
重要提示:在生产环境中设置收集频率过高的时候要特别小心
任务:为数据收集和分析操作而生成相关信息
此任务并不复杂,但第一个批处理文件需要执行将近5分钟的时间,第二个批处理文件将打开多个SQLCMD 命令行窗口,直到手动停止。这些脚本在进行分析前都需要时间。因此我们先将它们启动,直到后面的步骤再将其停止。另外,我们不需要关注这些脚本如何运行也不需要等待它们执行完毕。
15. 运行批处理文件。打开我的电脑,然后打开下面的文件夹:
C:/Manageability Labs/Performance Data Collection
16. 双击GenerateData.cmd 文件。该脚本将执行将近5分钟的时间直至完成
17. 双击GenerateActivity.cmd 文件。该脚本将循环执行,直到我们在后面的练习中关闭该窗口
任务:查看Server Activity 和 Query Statistics 这两个系统数据收集组的代码、设计、以及参数
18. 返回到CHICAGO/SQLDEV01 实例的Object Explorer 并依次展开Management, Data Collection, 以及System Data Collection Sets. 在此可以看到三个系统数据收集组:Disk Usage, Query Statistics, and Server Activity.
19. 右键点击Query Statistics 然后点击Properties. 注意该收集组和Disk Usage 数据收集组属性的区别:
相同点
• 两者均为非缓存模式
• 两者在Uploads 选项卡中均为灰色
• 两者均通过SQL Server Agent 运行
不同点
• Disk Usage 数据收集组通过T-SQL 语句实现,在Input Parameters 中可以看到相关语句。而Query Statistics 则通过 内部的 “Query Activity Collector Type” 来处理,且无法直接查看。该数据收集组所收集的内容在Description 选项卡中可以看到:Collects query statistics, sql text and plans of most performance-affecting queries and normalized query text. Allows to analyze details of the worst performing queries and correlates them with overall SQL Server activity.
• Disk Usage 的保留期限是730 天,而Query Statistics 只有14天
20. 右键点击Server Activity 然后点击Properties. 注意与上述两个数据收集组(Disk Usage 和Query Statistics)的区别:
不同点
• Server Activity 采用缓存模式,因此有两个相关作业,一个用于收集,另一个用于上传
• Uploads 选项卡不是灰色显示,数据收集之后会首先进行缓存,然后每隔15分钟批量上传一次。
• 21. 删除DiskUsage_noncached, QueryStatistics_noncached 和ServerActivity_Uploads 中多余的计划,只保留JobSchedule_Every_1min 计划。右键点击每个作业,然后点击Properties,选中 Schedules 页面。点击Remove…
22. 不要关闭SQLCMD 窗口
23. 在SQL Server Management Studio 中关闭所有打开的查询窗口,不要关闭SQL Server Management Studio
3. 分析系统数据收集组
在此练习中,我们将分析系统所支持的数据收集组,并查看其中所提供的信息。
任务:查看并分析Disk Usage 的趋势
1. 在Object Explorer 中右键点击Management, 然后点击Data Collection. 依次点击Reports, Management Data Warehouse, Disk Usage Summary.
1)可以看到每个数据库的初始大小,当前大小,以及平均每天的增量均会显示出来
2. 2)点击AdventureWorks2008 数据文件的趋势图,可以看到该数据库的详细信息:
查看Disk Usage Collection Set 的输出信息,从而可以了解到数据库的增长速度是否超过了预期值
2. 如果数据库的增长速度超过预期值,我们还可以双击该数据库中的数据表,以便查看最为消耗资源的数据表是哪些
3. 3. 在Object Explorer 中展开Databases 然后右键点击AdventureWorks2008并点击Reports, 从而查看Disk Usage by Top Tables 的标准报表。在Reports 菜单中,依次点击Standard Reports, Disk Usage by Top Tables.
任务:查看并分析Query Statistics 的趋势
当这些查询运行时,系统处于非常忙碌的状态,因此会产生大量CPU负载
5. 在Object Explorer 中,依次展开Management, Data Collection, Reports, Management Data Warehouse, 然后右键点击Query Statistics History
6. 点击Rank Queries by:中的Duration链接,查看Most Expensive Queries by Total Duration
在Most Expensive Queries by Total Duration 中点击Query 1,可以看到详细信息,包括哪些查询最耗资源、不同查询计划的开销等。
7. 在Most Expensive Queries by Total Duration 中点击Query 1,可以看到详细信息,包括哪些查询最耗资源、不同查询计划的开销等。
8. 此外,我们还可以查看查询计划的详细信息:
9. 在Object Explorer 中,依次展开节点Management, Data Collection, Reports, Management Data Warehouse并右键点击Server Activity
11. 注意Server Activity 分为CPU, Memory, Disk I/O, Network, Waits 以及Activity 几个部分,每个部分我们都可以查看到更为详细的信息
12. 任意点击SQL Server Waits 中的某个竖条,可以查看到不同的等待状态;
13. 展开Lock 节点查看详细信息。在Lock 节点中我们可以打开SQL Server Blocking 页面:
13. 点击Chain # 下的1 可以看到更为详细的信息
14. 关闭所有SQLCMD 窗口
15. 退出SQL Server Management Studio
- 手把手教你SQL Server2008性能数据收集
- SQL Server手把手教你使用profile进行性能监控
- SQL Server 手把手教你使用profile进行性能监控
- SQL Server 手把手教你使用profile进行性能监控
- 手把手教你收集产品情报
- SQL SERVER2008数据挖掘
- Sql Server2008数据挖掘
- 工具| 手把手教你信息收集之子域名收集器
- SQL Server2008 删除大量数据
- 手把手教你写 SQL Join 联接
- <WP7>(四)手把手教你写天气预报程序:本地数据库SQL CE,XML数据解析
- 手把手教你-----巧用Excel批量生成SQL语句,处理大量数据
- 【转】手把手教你-----巧用Excel批量生成SQL语句,处理大量数据
- 手把手教你 企业服务器安全性能测试
- 收集并存储性能监控器数据到SQL Server表
- 利用typeperf工具收集SQL Server性能数据
- 利用typeperf工具收集SQL Server性能数据
- 利用typeperf工具收集SQL Server性能数据
- 用C#生成不重复的随机数
- 《BREW进阶与精通——3G移动增值业务的运营、定制与开发》连载之46---BREW SDK 九大功能之系统服务
- 投入和产出比例是衡量信息化成功的最主要标准
- Shrink space合并表的碎片
- 网络协议
- 手把手教你SQL Server2008性能数据收集
- 硬件的艺术-layout
- 可以看看的书籍
- vc 创建线程
- Design by Contract 契约式设计
- JBPM 3.1.X 与 JBPM 3.2.X 中的Timer区别
- 困在水中央
- 少先队员捐水还是免了吧
- java web 开发 之 jsf2 入门系列之1


