dictmatch及多模算法串讲(一)
来源:互联网 发布:手机淘宝聊天工具 编辑:程序博客网 时间:2024/05/02 00:13
多模式匹配在这里指的是在一个字符串中寻找多个模式字符字串的问题。一般来说,给出一个长字符串和很多短模式字符串,如何最快最省的求出哪些模式字符串出现在长字符串中是我们所要思考的。该算法广泛应用于关键字过滤、入侵检测、病毒检测、分词等等问题中。多模问题一般有 Trie 树, AC 算法, WM 算法等等。我们将首先介绍这些常见算法。
1. hash
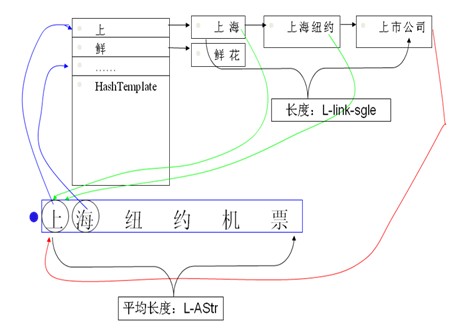
可以单字、双字、全字、首尾字 hash 。
优点:简单、通常有效
缺点:受最坏情况制约,空间消耗大,需要回朔。
2. Trie 树
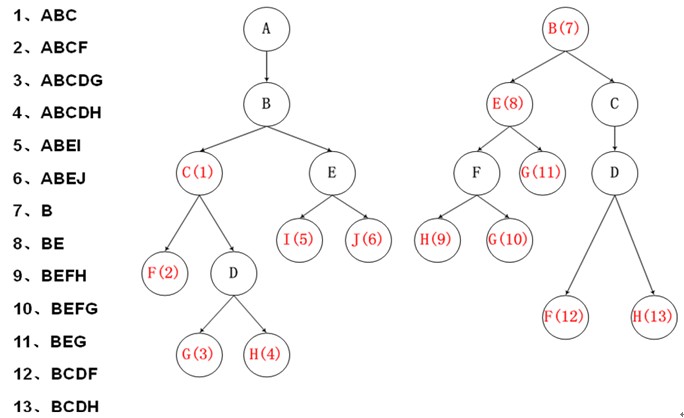
改进:进行穿线,参考 KMP 的算法,进行相同前缀匹配,建立跳转路径,避免回朔。
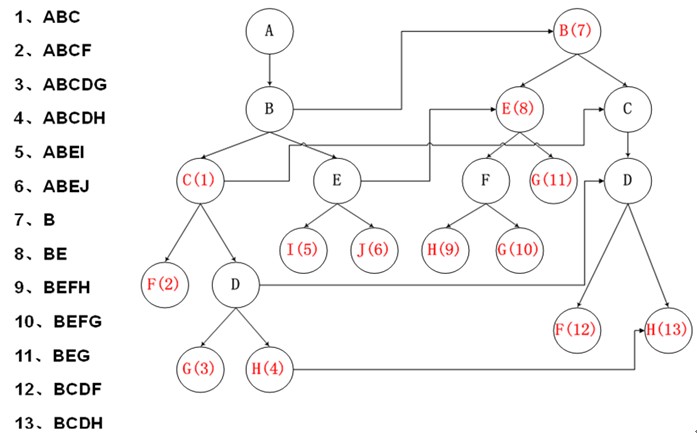
跳转路径建立的算法思想:
如果要建立节点 A -> A’ 的 跳转路径需要满足:
1) A = A’ 节点有相同的 value 值,代表同一个字
2) A 的深度 >A’ 的深度
3) 对于 A 节点的父节点 F ,和 A’ 节点的父节点(如果有父节点的话),有 F->F’
优点:无回朔,查询效率一般较高
缺点:数据结构复杂难以维护,浪费空间多,建树时间长。
3. AC 算法
本质上来说和 Trie 树一样。

转向函数:建立一个根据输入字符转变状态的有限自动机
失效函数:当出现状态无法根据输入字符继续走时,需要根据失效函数转化当前状态。失效函数的建立需要满足:节点 r 深度之前都已建立失效函数 f 。则若有 g(r, a) = s ,回朔 r’=f( r ) 直至找到 g(r’, a) 存在,则将 f(s)=g(r’, a) 。和 Trie 树是一致的。实际上,如果某状态节点 r 对输入字符 a 无路径,则可以将该节点的失效函数 f( r ) 指向的状态节点 r’ 的 g(r’, a) 作为 g(r, a) 。这样在搜索中就不需要专门考虑失效节点的问题了,只需要沿着转向函数一直走。
输出函数:某状态代表着匹配某模式的结束,因此输出函数的值就是匹配成功模式的集合。因为模式之间可能会有互包含,因此可能有多个成功匹配的模式。
AC 算法比 Trie 树数据结构简单,因此运用广泛。用于 snort 等代码中。
4. WM 算法
先讲 BM 算法。 BM 算法是 KMP 之外的另一个单模式字符串匹配算法,其思想也很简单:
假设模式串是 P 主串是 T, m=strlen(P),n=strlen(T)
1) 从左向右移动模式串
2) 对于模式串的匹配 , 从右向左检查 , 也就是 P[m-1],p[m-2]...
3) 当发现不匹配时 , 使用好后缀和 / 或坏字符来决定模式串移动的距离 通常同时使用两个来加快查找速度
当发现一个不匹配时 如下 :
Consider a mismatch at P[n - 5]:
T: mahtava t alomaisema omalomailuun
P: maisemaom aloma
上面 m != t ,
这时 T 中的 t 字符叫做坏字符, P 中的字符 "aloma" 叫做好后缀
坏字符算法 :
当出现一个坏字符时 , BM 算法向右移动模式串 , 让模式中最靠右的对应字符与坏字符相对。然后继续匹配。移动距离可预先计算为 delta1(x) = m - max{k|P[k] = x, 1 <= k <= m}; ( x 出现在 P 中)。
好后缀算法 :
如果程序匹配了一个好后缀 , 并且在模式中还有另外一个相同的后缀 , 那把下一个后缀移动到当前后缀位置 ( 类似 KMP 只是 KMP 是从左向右移动 ) 。移动距离 delta2 可预先计算为 delta2 ( j ) = {s|P[j+1..m]=P[j-s+1..m-s]) && (P[j] ≠ P[j-s])(j>s)} 。
BM 算法在查找开始时 先根据模式串中所有字符建立一个坏字符表,然后创建一张好后缀表。在匹配过程中,取 max{delta1, delta2} 作为实际移动的离尾部的距离,即尽量移动距离最大。
BM 算法的最坏时间复杂度为 O(m*n) ,但实际比较次数只有文本串长度的 20% ~ 30% 。可以看作是亚线性的时间复杂度算法。
WM 算法的思想从 BM 算法思想演变而来,但是用于多模匹配中。 WM 算法也是从右到左进行匹配。 WM 算法有一个重要假设,假设所有的模式的字符串长度是一样的,为 m 。若不一样,则按最短的那个模式长度在做匹配时截断其他的模式。
WM 算法将建立三张表: SHIFT[], HASH[], PREFIX[] 。其中, SHIFT 表用于决定匹配时出现失配的情况时的移动距离,类似于 BM 算法中的坏字符策略。 HASH 和 PREFIX 表则用于当 SHIFT 表匹配成功不需要移动后,决定是否具体匹配到某个模式的问题。
SHIFT 表:考虑一块大小为 B 的字符块,而不是单纯的一个字符。一般取 B=2 或 3 。 SHIFT 为长度为 B 的一切可能的字符排列都建立一个索引,因此其下标的大小就是所有可能的长度为 B 的排列数。(实际上,可以通过压缩的策略将一些排列串弄到相同的空间)。 SHIFT 中每一项的值决定在文本中出现某 B 个字符组成的字符串时 pattern 的移动距离,也就是在所有的 pattern 中出现的最右的 B 离 pattern 尾部的距离。假设 X 为当前计算的 B 长字符块,且被 hash 为 i ,考虑两种情况:
第一: X 不在任何一个 pattern 中出现,我们可以将当前 text 考察的位置向后移
动 m-B+1 个字符的距离,于是我们在 SHIFT[i] 中存放 m-B+1 。
第二: X 在某些 pattern 中出现,这种情况下,我们考察那些 pattern 中
X 出现的最右位置。假设, X 在 P[j] 中的 q 位置出现,且在其他的出现 X 的 pattern 中 X 的位置都不大于 q 。那么我们应该在 SHIFT[i] 中存放 m-q 。
最后我们将得到 SHIFT 表,表中存放的值是我们 text 中出现某一长为 B 的字符串时能够移动的最大的安全距离。当检查 pos 位置,得到其 B 块的 hash 值为 i ,当 SHIFT[i]<> 0 时, pos=pos + SHIFT ,跳动。

HASH 表:当 SHIFT[i]=0 时使用。 SHIFT[i]=0 时,代表匹配串当前位置的 X 可能匹配上了某个(某些)模式的尾部。因此 HASH[i] 指向了尾部 B 长的字符块散列值为 i 的模式链表的头 p 。我们可以将所有的模式以尾部 B 长的字符块的散列值进行排序存放在某个模式表数组中,则只需要依次递增 p 就可以找到所有尾部散列值为 i 的模式,直到 p = hash[i+1] ,代表了该链表的尾部。
PREFIX 表:当 SHIFT[i]=0 时,且通过 HASH 表列出了所有可能的模式时使用。通过对每个模式头部 B’ 个字符进行 hash ,将其散列值放在 PREFIX 表中。 HASH[i] 中的指针同时也是指向 PREFIX 表的,通过比较 PREFIX[p] 和匹配串的头 B’ 个字符的 hash 值,能够进一步确定是哪个模式匹配上了。最终,对该模式和匹配串的每一个字符进行一一匹配确定是否匹配。
如果 SHIFT[i]=0 ,且检查匹配完成,则 pos = pos + 1 ,继续检查 pos 位置的 SHIFT 。
实践证明,大部分时间 SHIFT 都不为 0 ,(在一个典型的例子中,对于 100 个模式 5% 的时间移动值为 0 , 1000 个模式 27% 的时间移动值为 0 , 5000 个模式 53% 的时间。),也就代表匹配串是跳跃着前进的,因此可以达到亚线性的时间复杂度。经过计算,复杂度为 O(mp)+ O(BN/m) ,设 N 是文本的大小, P 是模式的数量, m 是每个模式的长度。
优点:快速,数据结构简单,实现容易。
缺点:需要所有模式长度基本相同(不能有太短的模式),不支持变长的编码,例如 GB18030 。
- dictmatch及多模算法串讲(一)
- dictmatch及多模算法串讲(二)
- 【百度分享】dictmatch及多模算法串讲 -- dictmatch基本数据结构及算法
- 【百度分享】dictmatch及多模算法串讲 -- 简介
- [百度分享]dictmatch及多模算法串讲 -- 简介(转)
- 多模匹配算法与dictmatch实现
- 多模匹配算法与dictmatch实现
- [转]多模匹配算法与dictmatch实现
- 交换排序(exchange sorts)算法大串讲
- 交换排序(exchange sorts)算法大串讲
- 选择排序(selection sorts)算法大串讲
- 插入排序(insertion sorts)算法大串讲
- 归并排序(merge sorts)算法大串讲
- 分布排序(distribution sorts)算法大串讲
- 分布排序(distribution sorts)算法大串讲
- 自考《计算机应用基础》串讲冲刺讲义(一)
- .NET Framework基本概念串讲 (一)
- java中级-2-Collection集合类知识串讲(1)-List及Set
- 三思而后行的真意
- matlab中fix, floor, ceil, round 函数的使用方法
- C++中extern “C”含义深层探索 [转]
- 这是最好的年代,也是最坏的年代?
- 如何将Excel中的数据导入数据库
- dictmatch及多模算法串讲(一)
- Thread 摘要
- 给sqlite数据库加密的两种方法
- Dwr 搜索条
- 如何将DBGrid中的数据原样导出到Excel表中
- C#读取HTML文件内容写入记事本
- 不做人生规划,你离挨饿只有三天
- OSE(OpenNMS Sans Effort):CentOS装好,OpenNMS也就装好了,真的!
- C# 日期格式---格式模式


