HDU 3336 Count the string (记忆化搜索)
来源:互联网 发布:淘宝村服务站怎样申请 编辑:程序博客网 时间:2024/04/29 13:47
Count the string
Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)
Total Submission(s): 745 Accepted Submission(s): 320
Problem Description
It is well known that AekdyCoin is good at string problems as well as number theory problems. When given a string s, we can write down all the non-empty prefixes of this string. For example:
s: "abab"
The prefixes are: "a", "ab", "aba", "abab"
For each prefix, we can count the times it matches in s. So we can see that prefix "a" matches twice, "ab" matches twice too, "aba" matches once, and "abab" matches once. Now you are asked to calculate the sum of the match times for all the prefixes. For "abab", it is 2 + 2 + 1 + 1 = 6.
The answer may be very large, so output the answer mod 10007.
s: "abab"
The prefixes are: "a", "ab", "aba", "abab"
For each prefix, we can count the times it matches in s. So we can see that prefix "a" matches twice, "ab" matches twice too, "aba" matches once, and "abab" matches once. Now you are asked to calculate the sum of the match times for all the prefixes. For "abab", it is 2 + 2 + 1 + 1 = 6.
The answer may be very large, so output the answer mod 10007.
Input
The first line is a single integer T, indicating the number of test cases.
For each case, the first line is an integer n (1 <= n <= 200000), which is the length of string s. A line follows giving the string s. The characters in the strings are all lower-case letters.
For each case, the first line is an integer n (1 <= n <= 200000), which is the length of string s. A line follows giving the string s. The characters in the strings are all lower-case letters.
Output
For each case, output only one number: the sum of the match times for all the prefixes of s mod 10007.
Sample Input
1
4
abab
Sample Output
6
解题思路:
利用记忆化搜索,算法上依然是搜索的流程,但是搜索到的一些解用动态规划的那种思想和模式作一些保存。记忆化算法在求解的时候还是按着自顶向下的顺序,但是每求解一个状态,就将它的解保存下来,以后再次遇到这个状态的时候,就不必重新求解了。
题目的意思是,给个字符串,要求自身从第一个字符开始叠加,一共有多少次跟原串符合的。数组长度过于长,很容易超时,所以算法复杂度得减少。我们给定一个整型b[]数组记录匹配下标(从1下标开始)。如下图所示:
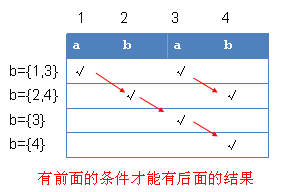
从上面的图,我们可以知道每次求出的b[]数组的值都对于后面的求解有用处,是必要条件,这样就可以节省很多时间了。
- HDU 3336 Count the string (记忆化搜索)
- HDU 3336 Count the string (记忆化搜索)
- hdu 3336 Count the string(记忆化搜索)
- HDU 3336 Count the string(KMP)||记忆化搜索
- Count the string(记忆化搜索)
- C语言记忆化搜索___Count the string(Hdu 3336)
- HDU 4472 Count(记忆化搜索)
- HDU 3336 Count the string
- hdu 3336 Count the string
- hdu 3336 Count the string
- hdu 3336 Count the string
- hdu 3336 Count the string
- hdu 3336 Count the string
- hdu 3336 Count the string
- HDU-Count the string -3336
- hdu 3336 Count the string
- HDU 3336 Count the string
- HDU 3336Count the string
- 深入分析MFC文档视图结构(项目实践)
- FILTER过滤JAVA WEB的字符编码
- 供应无线模块
- XPO学习三
- 字符串截取
- HDU 3336 Count the string (记忆化搜索)
- 应该清理CBA场内和场外的垃圾
- 华为 深圳枫叶城市酒店面试
- 知识产权保护与知识传播
- Does VFP 9.0 Work Well For Windows 7?
- 用的和学到的
- 房地产业务学习(01):低成本运营策略
- 个人整理的消息队列的几个函数
- 美国的教育体制是完美的吗


