信息传递、编码和计算机表示(四)
来源:互联网 发布:大数据时代对生活影响 编辑:程序博客网 时间:2024/04/30 01:58
信息传递、编码和计算机表示(三)中讲述了中文编码。 本篇将说明Unicode编码、Unicode的转换格式(UTF,Unicode Translation Format)以及MBCS
一、UCS和Unicode
Unicode是基于通用字符集(Universal Character Set)的标准来发展。UCS就是使用多个字节对字符进行统一编码,是的各种语言的各种字符存在于一个编码空间中。其中UCS-2使用2字节进行编码,USC-4使用4字节进行编码。 目前Unicode编码和USC-2编码原理一致。
USC-2,2个字节进行编码,理论上可以对 2^16 = 65536 种字符进行编码。 其中前256(0x0000-0x00FF)个和ASCII(0x00-0xFF)相对应。实际上目前版本的Unicode尚未填充满这16位编码,保留了大量空间作为特殊使用或将来扩展。
USC-4,4个字节进行编码,是一个更大的尚未填充完全的31位字符集,加上恒为0的首位,共需占据32位,即4字节。理论上最多能表示231个字符,完全可以涵盖一切语言所用的符号。
USC-4的4个字节可以表示为 2 ^32 = 2 ^ 16 * 2 ^ 16 = 65536 * (2 ^ 16)。 其中2 ^ 16称为一个平面(Plane),那么USC-4公有65536个平面(Plane)。其中第一个Plane就是USC-2,这占用16位编码的Unicode字符构成基本多文种平面(Basic Multilingual Plane,简称BMP)。
USC-2在USC-4中的表示,是高两字节为0。
为了使Unicode与已存在和广泛使用的旧有编码互相兼容,尤其是差不多所有电脑系统都支援的基本拉丁字母部分,所以Unicode的首256字符仍旧保留给ISO 8859-1所定义的字符,使既有的西欧语系文字的转换不需特别考量;另方面因相同的原因,Unicode把大量相同的字符重复编到不同的字符码中去,使得旧有纷杂的编码方式得以和Unicode编码间互相直接转换,而不会遗失任何资讯。举例来说,全角格式区段包含了主要的拉丁字母的全角格式,在中文、日文、以及韩文字形当中,这些字符以全角的方式来呈现,而不以常见的半角形式显示,这对竖排文字和等宽排列文字有重要作用。
二、Unicode实现方式
Unicode的实现方式不同于编码方式。一个字符的Unicode编码是确定的。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。Unicode的实现方式称为Unicode转换格式(Unicode Translation Format,简称为UTF)。
例如,如果一个仅包含基本7位ASCII字符的Unicode文件,如果每个字符都使用2字节的原Unicode编码传输,其第一字节的8位始终为0。这就造成了比较大的浪费。对于这种情况,可以使用UTF-8编码,这是一种变长编码,它将基本7位ASCII字符仍用7位编码表示,占用一个字节(首位补0)。而遇到与其他Unicode字符混合的情况,将按一定算法转换,每个字符使用1-3个字节编码,并利用首位为0或1进行识别。这样对以7位ASCII字符为主的西文文档就大大节省了编码长度(具体方案参见UTF-8)。类似的,对未来会出现的需要4个字节的辅助平面字符和其他UCS-4扩充字符,2字节编码的UTF-16也需要通过一定的算法进行转换。
再如,如果直接使用与Unicode编码一致(仅限于BMP字符)的UTF-16编码,由于每个字符占用了两个字节,在Macintosh (Mac)机和PC机上,对字节顺序的理解是不一致的。这时同一字节流可能会被解释为不同内容,如某字符为十六进制编码4E59,按两个字节拆分为4E和59,在Mac上读取时是从低字节开始,那么在Mac OS会认为此4E59编码为594E,找到的字符为“奎”,而在Windows上从高字节开始读取,则编码为U+4E59的字符为“乙”。就是说在Windows下以UTF-16编码保存一个字符“乙”,在Mac OS里打开会显示成“奎”。此类情况说明UTF-16的编码顺序若不加以人为定义就可能发生混淆,于是在UTF-16编码实现方式中使用了大端序(Big-Endian, 简写为UTF-16 BE)、小端序(Little-Endian,简写为UTF-16 LE)的概念,以及可附加的字节顺序记号解决方案,目前在PC机上的Windows系统和Linux系统对于UTF-16编码默认使用UTF-16 LE。(具体方案参见UTF-16)
此外Unicode的实现方式还包括UTF-7、Punycode、CESU-8、SCSU、UTF-32等,这些实现方式有些仅在一定的国家和地区使用,有些则属于未来的规划方式。目前通用的实现方式是UTF-16小尾序(LE)、UTF-16大尾序(BE)和UTF-8。在微软公司Windows XP操作系统附带的记事本(Notepad)中,“另存为”对话框可以选择的四种编码方式除去非Unicode编码的ANSI(对于英文系统即ASCII编码,中文系统则为GB2312或Big5编码) 外,其余三种为“Unicode”(对应UTF-16 LE)、“Unicode big endian”(对应UTF-16 BE)和“UTF-8”。
目前辅助平面的工作主要集中在第二和第三平面的中日韩统一表意文字中,因此包括GBK、GB18030、Big5等简体中文、繁体中文、日文、韩文以及越南喃字的各种编码与Unicode的协调性被重点关注。考虑到Unicode最终要涵盖所有的字符,从某种意义而言,这些编码方式也可视作Unicode的出现于其之前的既成事实的实现方式,如同ASCII及其扩展Latin-1一样,后两者的字符在16位Unicode编码空间中的编码第一字节各位全为0,第二字节编码与原编码完全一致。但上述东亚语言编码与Unicode编码的对应关系要复杂得多。
注:以上部分引用自http://zh.wikipedia.org/zh-cn/Unicode,更多关于Unicode的内容请点击链接查看。
三、Unicode和GB2312、GBK、GB18030的关系
Unicode(UCS-2)对汉字和ASCII字符集都使用2字节编码。
GB2312、GBK、GB18030对汉字使用2字节,对ASCII字符集使用1字节。
并且对于同一个汉字,其Unicode编码和GBK编码也不一样。
我们称象GBK这样使用变长字节进行编码的方法叫做MBCS(Muilti-Bytes Charecter Set,多字节字符集),CJK(Chinese,Japane,Korea)使用的都应该是MBCS编码方法。
<!-- 以下引用自 http://zh.wikipedia.org/zh-cn/UTF8 -->
四、UTF-8产生原因和编码方法
ASCII转换成UCS-2,在编码前插入一个0x0。用这些编码,会含括一些控制符,比如"或 '/',这在UNIX和一些C函数中,将会产生严重错误。因此可以肯定,UCS-2不适合作为Unicode的外部编码,也因此诞生了UTF-8。
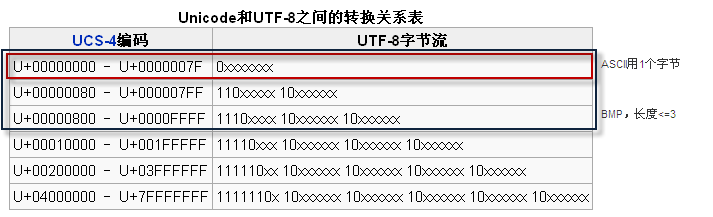
UTF-8就是以8位为单元对UCS进行编码,而UTF-8不使用大尾序和小尾序的形式,每个使用UTF-8存储的字符,除了第一个字节外,其余字节的头两个位都是以"10"开始,使文字处理器能够较快地找出每个字符的开始位置。
但为了与以前的ASCII码兼容(ASCII为一个字节),因此UTF-8选择了使用可变长度字节来存储Unicode:
- 在ASCII码的范围,用一个字节表示,超出ASCII码的范围就用字节表示,这就形成了我们上面看到的UTF-8的表示方法,这様的好处是当UNICODE文件中只有ASCII码时,存储的文件都为一个字节,所以就是普通的ASCII文件无异,读取的时候也是如此,所以能与以前的ASCII文件兼容。
- 大于ASCII码的,就会由上面的第一字节的前几位表示该unicode字符的长度,比如110xxxxxx前三位的二进制表示告诉我们这是个2BYTE的UNICODE字符;1110xxxx是个三位的UNICODE字符,依此类推;xxx的位置由字符编码数的二进制表示的位填入。越靠右的x具有越少的特殊意义。只用最短的那个足够表达一个字符编码数的多字节串。注意在多字节串中,第一个字节的开头"1"的数目就是整个串中字节的数目。。
ASCII字母继续使用1字节存储,重音文字、希腊字母或西里尔字母等使用2字节来存储,而常用的汉字就要使用3字节。辅助平面字符则使用4字节。
在UTF-8文件的开首,很多时都放置一个U+FEFF字符(UTF-8以EF,BB,BF代表),以显示这个文字文件是以UTF-8编码。
<!-- 引用结束 -->
四、MBCS和UTF-8
虽然MBCS和UTF-8都是用变长字节来编码,但是确切的来说MBCS是一种编码方法。 而UTF-8不是。UTF-8只是对定长的Unicode的一种转换格式。MBCS中,中文用2个字节,ASCII字符用1个字节。 UTF-8中,中文用三个字节,ASCII用1个字节。
- 信息传递、编码和计算机表示(四)
- 信息传递、编码和计算机表示(一)
- 信息传递、编码和计算机表示(二)
- 信息传递、编码和计算机表示(三)
- 计算机基础四之数制和信息的编码上
- 计算机基础四之数制和信息的编码下
- 计算机表示和操纵信息的方式
- 计算机图形学(四)几何变换_2_矩阵表示_1_矩阵表示和齐次坐标
- 字符信息的表示和编码
- 计算机中的信息表示
- 深入理解计算机系统之旅(二)信息在计算机中的表示和处理
- 计算机中字符的二进制编码表示(ASCII)
- 各种信息在计算机中的表示(数字、字母、汉字)
- 第三章信息编码与数据表示(一)
- 第三章信息编码与数据表示(二)
- ReactNative学习实例(四) 使用Navigator实现页面跳转和信息传递
- 计算机中汉字的二进制编码表示
- 计算机编码类型以及变量表示范围
- 你是人间的四月天
- Struts2初体验中的 Unable to load configuration 的解决方案
- 第一部分,第二章
- PHP图表制作工具集
- asp.net在iis种部署遇到的问题
- 信息传递、编码和计算机表示(四)
- 【SQL SERVER2005页面存储3之--聚集索引的存储】
- 知识的汪洋
- 十二生肖相配相克
- C/C++文档注释神器——Doxygen常用知识整理(持续更新)
- flex收藏
- 2010英特尔信息技术峰会(IDF)第2天大事记
- JMS Development Guide
- MySQL 6.0免安装配置


