边学边记(五) lucene索引结构二(segments_N)
来源:互联网 发布:魔法王座进阶数据文库 编辑:程序博客网 时间:2024/04/27 19:26
lucene中索引文件的存储用段segments来描述的,通过segments.gen来维护gen信息
和segments.gen一样头信息是一个表示此索引中段的格式化版本 即format值 根据format值判断此段信息中的信息存储格式和存储内容
一个segment_N文件中保存的信息和信息的类型 如下图所示
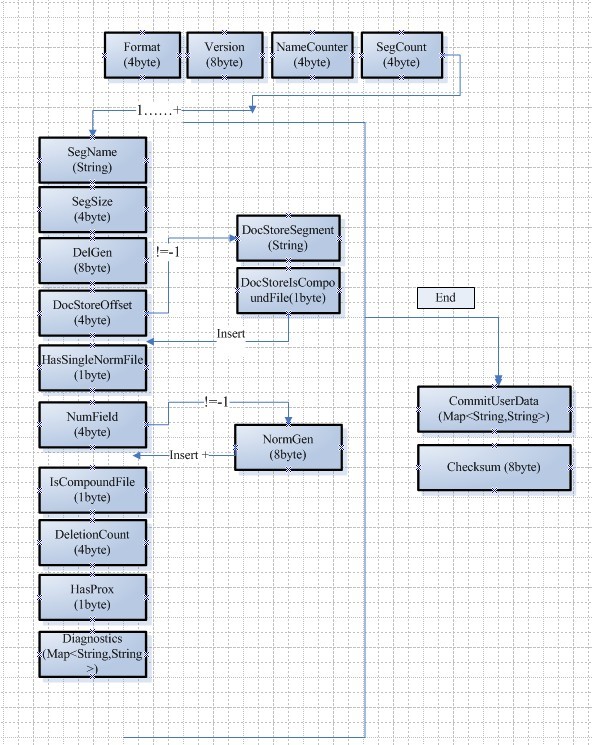
信息存储的格式是这样的
Format, Version, NameCounter, SegCount, <SegName, SegSize, DelGen, DocStoreOffset, [DocStoreSegment, DocStoreIsCompoundFile], HasSingleNormFile, NumField, NormGenNumField, IsCompoundFile, DeletionCount, HasProx, Diagnostics>SegCount, CommitUserData, Checksum
Format 是一个int32位的整数一般为-9 SegmentInfos.FORMAT_DIAGNOSTICS
Version 值保存操作此索引的时间的long型时间 System.currentTimeMillis()
NameCounter 用来生成新的segment的文件名
SegCount 记录索引中有多少个段 有多少个段后面红色标记的属性就会重复多少次
每个段的信息描述:
SegName, SegSize, DelGen, DocStoreOffset, [DocStoreSegment, DocStoreIsCompoundFile], HasSingleNormFile, NumField, NormGenNumField, IsCompoundFile, DeletionCount, HasProx, Diagnostics
SegName -- 和字段有关的索引文件的前缀 上篇博文中生成的索引中 存储的应该是"_0"
SegSize -- 记录的此段中 document的个数
DelGen -- 记录了删除操作过后产生的*.del文件的数量 如果为-1 则没有此文件 如果为0 就在索引中查找_X.del文件 如果 >0就查找_X_N.del文件
DocStoreOffset -- 记录了当前段中的document的存储的位置偏移量 如果为-1 说明 此段使用独立的文件来存储doc,只有在偏移量部位-1的时候[DocStoreSegment, DocStoreIsCompoundFile] 信息才会存储
DocStoreSegment -- 存储和此段共享store的segment的name
DocStoreIsCompoundFile --用来标识存储是否是混合文件存储 如果值为1则说明使用了混合模式来存储索引 那么操作的时候就回去找.cfx文件
HasSingleNormFile -- 如果为1 表明 域(field)的信息存储来后缀为.fnm文件里 如果不是则存在.fN文件中
NumField -- field的个数 即NormGen数组的大小 这个数组中具体存了域的gen信息 long类型 前提是每个field都分开存储的
DeletionCount, HasProx, Diagnostics
DeletionCount -- 记录在此段中被删除的doc的数量
HasProx -- 此段中是否已一些域(field) 省略了term的频率和位置 如果值为1 则不存在这样的field
Diagnostics -- 诊断表 key - value 比如当前索引的version,系统的版本,java的版本等
CommitUserData 记录用户自己的一些属性信息 在使用commit preparecommit 等操作的时候产生
Checksum 记录了当前Segments_N文件中到此信息之前的byte的数量 这个信息用来在打开索引的时候做一个核对 如果用户非法自己修改过此文件 那么这个文件记录的checksum就和文件的大小产生了冲突
这些信息都存储在SegmentInfos bean中 单个segmeng的信息存储在bean SegmentInfo 中 用上篇博客中写好的索引读取类
检测segments_n中存储的信息 这里仅检测前几个数据 其他的数据都由SegmentInfos 自己构造 读取函数都是从IndexInput类中继承
编写CheckSegmentsInfo 类
运行结果如下:
seg format:-9
seg Version:1275404730705
info Version:1275404730705
info Counter:1
info Seg Count:1
****************** segment [0]
segment name:_0
the doc count in segment:2
del doc count in segment:0
segment doc store offset:0
segment's DocStoreSegment:_0
segment's DocStoreIsCompoundFile:false
segment IsCompoundFile :false
segment's delcount:0
segment's is hasprox:true
Diagnostic key:os.version Diagnostic value:5.1
Diagnostic key:os Diagnostic value:Windows XP
Diagnostic key:lucene.version Diagnostic value:3.0.0 883080 - 2009-11-22 15:43:58
Diagnostic key:source Diagnostic value:flush
Diagnostic key:os.arch Diagnostic value:x86
Diagnostic key:java.version Diagnostic value:1.6.0
Diagnostic key:java.vendor Diagnostic value:Sun Microsystems Inc.
根据提到的个个byte的值表示的信息可以检测文件中都存的什么值,下面着重分信息lucene对string类型的存储和读取
luncene 写字符串的代码如下:
lucene写入字符串的时候使用的是UTF-8 编码格式,java本身的字符串是用unicode表示的 也就是UTF-16 1-2个字节表示 这里说下UTF-16是unicode的一种实现。
UTF-8编码的优点这里就不说了 和UTF-16不一样 UTF-8是用1-3个字节来存储的
转换为UTF-8后将所得的byte数组的长度作为前缀存为一个VInt类型整数后面跟字符串,例如:字符串:’“我” 在lucene中的存储为:
3 -26 -120 -111
3表示字符串"我"的utf8 的byte的长度 后面接的三位就是字符串的字节码
这样也是为了方便读取。具体代码可以看IndexInput类 。很简单
至于map<String,String>也就是一个循环
mapsize,<String,String>N
lucene读取segment_n文件的代码:
- 边学边记(五) lucene索引结构二(segments_N)
- 边学边记(八) lucene索引结构五(_N.tis,_N.tii)
- 边学边记(九) lucene索引结构五(_N.frq,_N.prx)
- lucene结构详解之一段的元数据信息segments_N
- 全文索引 (二)lucene 索引管理
- 边学边记(六) lucene索引结构三(_N.fnm)
- Lucene学习-创建索引(二)
- Lucene基础(二)--索引的操作
- Lucene学习笔记(二)--------构建索引
- lucene学习笔记(二)lucene建立索引
- lucene索引结构(对lucene索引段中的各个类型的文件有所解释)
- lucene索引结构(二)--域(Field)信息索引
- Lucene五(添加日期和数字类型索引)
- 基于hadoop创建lucene索引(二)编程模型二
- 基于hadoop创建lucene索引(二)编程模型二
- Lucene 源码剖析 五 索引文件结构(4)
- (四)Lucene中索引文件结构剖析
- 边学边记(七) lucene索引结构四(_N.fdx,_N.fdt)
- 3.37如何动态地切换MDI子窗口或者在SDI主应用程序窗口显示的视图?
- spring的笔记
- WTL开发插件更新至0.82
- 从魔兽看PHP设计模式
- 基于 libmad 的简单 MP3 流媒体播放器的实现
- 边学边记(五) lucene索引结构二(segments_N)
- System.Collections 常用类,结构和结构
- mysql中使用sql语句插入日期时间类型的写法
- crysis2 video&cryengine3 editor show
- 框架之随便谈谈 (转)
- PE52
- VS 下 Open Cascade Source Code 编译及自定义工程设置
- J2ME CANVAS做的 LIST
- 结构体中位域存储


