Cassandra 源码解析 6: Storage Engine (DB Layer)
来源:互联网 发布:淘宝帮摇号车牌靠谱吗 编辑:程序博客网 时间:2024/04/26 22:17
原理
http://thoss.org.cn/mediawiki/index.php/Cassandra_data_model
http://labs.google.com/papers/bigtable.html
cassandra 的存储模型来自google的bigtable。
bigtable data model
bigtable 是一个key-value map,其key值由三者组成,行键(row key),列键(column key, cassandra中叫作column name),时间戳,value是字符串(即bytes数组)
(row:string, column:string, time:int64) -> string
要理解bigtable,由传统数据库存储入手,假定有一张user table,首先我们有定义table的结构,有哪些字段以及类型,主外键等
然后,我们按行插入数据
上述数据存储到bigtable中,则为8个key-value 数据,上述数据表中的每一个cell值对应bigtable中的一个存储项,例如第一行数据转换成4个key-value
bigtable将相同列键类型的key-value存储在一个ColumnFamily中。如同每一行按row key排序一样,cassandra中的column按照column key排序。
这样设计一个最显而易见的灵活性就是每个row key对应的column数量(类型)可以任意变化,传统的关系数据库中,每张表的column固定,每一行具有相同的column. 在bigtable论文中的Figure1到很贴合这种场景,每张网页被其他网页链接,这种链接的数目有多有少,无法使用固定的结构化table来存储- 当然也可以新建一张relation table来另外存储
写入延迟
在cassandra中,最近的更新(写入)首先是写在内存(memtable)和log文件中。memtable按key值排序(首先是行key,然后是列key),当memtable增长到一定size时(比如300M),将此memtable一次性的dump到disk上形成一个只读的sstable,metable被清空,从头开始增长。sstable包含索引信息,以判断某个key值是否存在和快速定位key值.
读入时,则从所有的SStable包含给定key值的sstable中读取数据,结合内存中的memtable,根据读取策略将各个不同版本的value进行merge返回,比如返回最新版本的数据给client
写入非常快,避免了磁盘的随机写入(包括对索引文件的建立都是在内存中完成,然后一次写入);sstable是只读文件,存储内容有序,可快速高效的读取。
log文件的写入是append操作和header更新,应该很快。
数据归并
如果一个key值被反复更新,则很可能多个sstable中存储着其不同版本的value。这样时间越长,这个key值所在的sstable越多,读取越耗时,简而言之,就是保存了太多的history version和已经被deleted的数据。因此每隔一段时间,定期的对sstable进行merge(major compaction),将几个sstable合并成一个大的sstable
Bloom Filter
怎么判断一个sstable中是否包含给定key。如果索引文件中有所有key值,可以将索引文件全部读入内存,然后判断。bigtable中使用的是一种更高效的方法:bloom filter. 原理简述如下:使用m个bit加k个hash函数来判断n个值的有无。对加入到集合的n,使用k个hash函数生成k个位置(<m),将这k个位置的bit设为1。判断n是否存在时,用同样的hash函数,得到k个位置,将bit取出,如果全为1,则说明存在。Bloom Filter有一定的假命中率,即n不在集合中,但根据bloom filter可能判断其存在,恰好被其他key值设置为1。要想减少假命中率,根据n的大小调整m,k。
厉害的地方在于:m是固定,小于n;而n不固定,可能很大. 有一定的假命中率(可控制),但不会漏命中。
Cassandra 实现
文件格式
如前所述,同样类型的column被放在一起,形成一个ColumnFamily. conf/storage-conf.xml(0.61) 中定义Keyspaces即定义各种ColumnFamily。我们可以将每个keyspace看成一个Table,而每个ColumnFamily看成一个超级大列存储,存储column key类型相同的key-value,比如前文中的email和姓名存在一个ColumnFamily中,而电话和年龄存在另外一个ColumnFamily中。Table 仅仅在内存中存在,由一个(或多个)ColumnFamily中的一个(或多个)Column组成。
Cassandra为每个keyspace生成一个目录,每个ColumnFamily生成独立的文件sstable文件(Data, Filer, Index)。如前所述,sstable文件是由memtable不断dump生成,所以每个ColumnFamily会对应多个sstable,每个sstable文件name由ColumnFamily和编号组成- 注意是ColumnFamily对应sstable和memtable,而不是keyspace
数据文件
在Memtable.writeSortedContents 中将一个Memtable dump为一个SStable到磁盘,将[key, value]按序写入。每对[key, value]存储格式如下:
下面一一道来,ColumnFamily.serializer().serializeWithIndexes进行序列化:
row key,不用多说, row size 则是row key之后所有数据的大小
接下来是bloom filter,用来判断某个column是否存在
然后是column的index信息(从设计上,Cassandra假定同一个row key可以有成千上万个column,所以建立column的bloom filter 和 index),ColumnIndexer.doIndexing 中建立索引。建立索引并不是每个column都生成一个IndexHelper.IndexInfo,而是分段索引(range 思想贯穿在cassandra中),默认每64k(ColumnIndexSizeInKB)的数据建立一个索引,比如column1, column2, column3, ...。如果column1 + column2 + column3 的大小超过64k,则建立一个IndexInfo,由(该range中)第一个column的name(column1),最后一个column的name(column3),第一个column的偏移(offset,第一个column为0,后者累加),数据的长度(length,该段内所有column的size之和)生成一个IndexInfo.
然后写入column内容,首先是column的数量,然后依次写入每个column
这里有两个字段localDeletionTime, markedForDeleteAt 作什么用,为什么写在这个位置,暂时打上问号
索引文件
序列化化完成后,调用SSTableWriter.append将数据写入data 文件,同时更新Index文件和bloom filter。索引文件格式很简单,如下:
关于索引文件,有两点有问号:一是为什么只有position信息,而没有size信息,要得到Size需要下个Index的信息;二是读取时,内存中并不是保存整个索引文件,而仅仅是IndexSummary,每128个key值生成一个KeyPosition(key, index position)放入内存中,如果遇到span情况(跨buffer?)则将PositionSize(data position, data size)也放入内存。
Bloom Filter 文件
bloom filter 的更新很简单,将key值加入即可。在所有数据写入完成后,bloom filter也生成,将其写入文件(SSTableWriter.closeAndOpenReader)
读取sequence
READ_STAGE 中执行读请求
ColumnFamilyStore.getTopLevelColumns中分别从所有该ColumnFamily的SStable文件和Memtable中读入,然后使用IteratorUtils.collatedIterator(org.apache.commons.collections 包)进行多路归并,将最新的cloumn返回。比如从SStable中读入column1, column2(version1), Memetable中有column2(version2), column3,多路归并后并为column1, column2(version1), column2(version2), column3,然后调用QueryFilter.collectCollatedColumns使用ReducingIterator将相同的column合并成单个column(又调用了ColumnFamily.addColumn来选择version较高的版本),形成结果column1, column2(version2), column3,返回.
Filter, Iterator模式应用到底(大量使用了google collection包中的AbstractIterator),有点让人眼花缭乱。
从Memtable(Memtable.getSliceIterator) 中再详述,从SStable中读取是生成一个SSTableSliceIterator对象
- 在构造函数中,调用:SSTableReader.getFileDataInput,该函数调用SSTableReader.getPosition(bloom filter和index file在此使用),找到该key在数据文件中的位置,返回数据文件句柄,并定位至对应位置。
- 在构造函数中,生成ColumnGroupReader对象,该对象的构造函数
- 将数据文件中的column index读入内存
- 设置mark,即第一个column开始的位置
- 读取时,调用getNextBlock,根据column index(offset, width,见前文数据文件格式) 一次读入多个column
- file pointer reset至mark
- skip offset
- read column 直到current file pointer超过width
- 读取过程中,和query 条件中的start column和end column比较,如果不在范围内,则提前返回
这里回过头来介绍cassandra的查询API,cassandra实际支持两种查询ReadCommand,SliceFromReadCommand和SliceByNamesReadCommand,对应不同的QueryFilter。NamesQueryFilter,根据column name查询,即给定key(row key, column name),返回单个column,当然可以一次性指定多个column name;另外一种是SliceQueryFilter,给定key(row key, start column, end column),查询一个切片的columns(column name在start column和end column之间)。
写入sequence
写入比较简单,append log file;写入Memtable,如果Memtable size超过一定值,则flush
Log
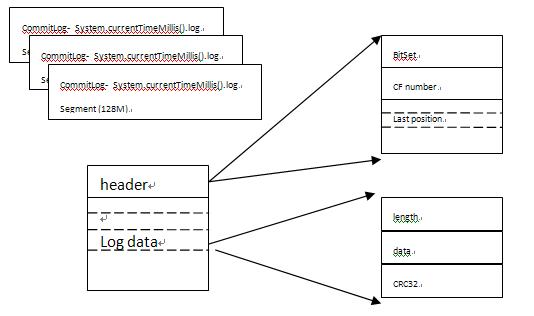
log文件格式
- 每128M生成一个log文件(对应CommitLogSegment)
- 每个log文件有header和log data组成
- header记录每个columnfamily是否有未提交log(dirty位)和已经最后一次提交log的position
- log data有一条条的数据组成:length + data + CRC
log的插入很简单:
- 生成一个Task(CommitLog.LogRecordAdder),在一个独立的Executor中(CommitLogExecutorService)中运行所有write log的task
- 更新header,将对应的bit打开,设置此ColumnFamily的last flush position 为current file pointer
- append data 到segment文件尾部
log 的提交
在刷新Memtable成为SStable后,当前segment之前的segments文件中对应ColumnFamily的dirty位会被清除,如果所有dirty都被清除,则这个segments文件会被discard掉。
ColumnFamilyStore.maybeSwitchMemtable
-> CommitLog.discardCompletedSegments
-> CommitLog.discardCompletedSegmentsInternal
log 的recover,在系统初始化或者收到drain命令时,log会replay然后被删除
- 找到segement中ColumnFamily最小的last flush position
- 从这个position开始,依次读入log data,校验CRC,如果正确,则生成Task,在MUTATION_STAGE中Table.apply。注意此时writeCommitLog设置为false
- 等待,直到所有log被都apply - 使用的是AtomicInteger来,apply一个则加1,完成apply则减1,最后为0
- 强制刷新Memtable(Table.flush),等待,直到刷新完毕.
Flush sequence
log replay时会刷新
size满时会刷新
compaction sequence
CompactionManager.submitMajor
将几个SSTable写入一个大的SSTable
- Cassandra 源码解析 6: Storage Engine (DB Layer)
- Cassandra 源码解析汇总
- Cassandra源码解析
- Cassandra 源码解析 5: MerkleTree
- Cassandra 源码解析 5: MerkleTree
- [Caffe]源码解析之Layer
- Caffe源码解析2:Layer
- Caffe源码解析3:Layer
- Caffe源码解析3:Layer
- Caffe源码解析3:Layer
- caffe源码解析之layer
- Cassandra 源码解析 1:网络通信
- Cassandra 源码解析 4: GMS 集群管理
- Spark源码解析——Storage模块
- caffe源码解析之Layer层(1)
- caffe源码解析之Layer层(1)
- express框架layer.js源码解析
- caffe源码简单解析—Layer层
- 2010_3
- JavaScript高级程序设计:第2版(china-pub首发)
- linux /proc文件目录
- 如何选择一个稳定的VPS供应商
- java 用path与classpath在命令行下指定一个运行环境(多个JDK版本中指定一个)
- Cassandra 源码解析 6: Storage Engine (DB Layer)
- amchart画图笔记
- http服务器返回代码
- STL之容器:选择时机,删除元素,迭代器失效
- oracle 中系统函数,将多行转为一列
- scp命令
- Web服务器控件:PlaceHolder控件
- DHCP协议详解
- Android.mk for your own module


