核心路由器的交换矩阵设计
来源:互联网 发布:法拉克系统编程 编辑:程序博客网 时间:2024/04/30 10:44
综述
在设计一个路由器时,第一步就是要决定交换矩阵的工作方式以及交换矩阵与板卡(或物理端口)之间的界面,而不是板卡的种类或是转发芯片的功能。只有在交换矩阵的结构设计完成后,板卡的设计才能启动。而随着需求的变化,板卡可以被重新设计,交换矩阵的界面却不可以,否则旧的板卡就不能和新的板卡兼容。因此,交换矩阵是用来区分路由器最好的界标,
交换矩阵的特性,决定于其提速比 ( Speedup Ratio),对缓存的管理,延展性的好坏,制造的成本,冗余的能力,复制地能力,以及总容量。
提速比 -交换矩阵的输出速率与输入速率的比例。通常说,提速比越高,交换矩阵内的堵塞率( Blocking Ratio)就越小,但是,这样的矩阵系统的造价也将越高。因此,一味地追求的低堵塞率并不是一个现实的做法,只要能将堵塞率降至可用网络设计的方式解决,就可以合理的成本制造出接近完美的交换矩阵。
缓存的管理 - 交换矩阵可以被分成无缓存型及有缓存型,但是,不管交换矩阵是否有缓存,她都必须要管理缓存,特别是进入交换矩阵前的缓存。缓存的管理不善,很容易因为缓存系统的尾端掉包,造成服务品质政策的扭曲,因此,好的交换矩阵必须有好的缓存管理。
延展性 -任何系统的延展性都与其所用的零部件有关,规避零部件的物理限制是增加延展性的不二法则,举例说,动态随机存取记忆体( DRAM)的存取时间在20年间(1985-2004)仅仅缩小的50%,而半导体的速度却增加了2720倍,因此,动态随机存取记忆体就成为一个提升系统延展性的阻碍。设计交换矩阵系统时,也必须考虑所采用的零部件是否有很好的成长空间,这样一来,就可以在不变更其工作原理及界面的条件下,使系统的容量能有数十倍,甚至数百倍的提升。
制造的成本 -新的半导体制造技术,无论是在密度及缩小耗电上都有长足的进步,但是她的价格却也上升许多。一个交换矩阵的系统,在需要增大原设计的总容量 4倍,16倍,64倍,256倍,甚至数千倍时,可能会因为原系统中所采用的半导体零部件的物理限制,而必须使用新的半导体制造技术,使系统的成本大幅度的提高。因此,交换矩阵的设计者,总是在成本及性能间作平衡。一方面,系统本身必须达到升级的需求(缩小耗电,提高总容量),另一方面,又必须注意制造的成本,祈求系统能达到最好的性价比。
冗余的能力 -在交换矩阵系统的设计初期,因考虑规避半导体零部件在未来升级中,所可能遇见的瓶颈,交换矩阵系统的设计多采用多平面的结构,使核心部件在可预见的未来,不会成为系统升级的瓶颈。但多平面的结构可能会因为转发顺序的维护而造成不尽理想的冗余特性。如何能使交换矩阵在能保证转发的顺序的同时,又能有良好的冗余能力,就变成设计交换矩阵的一大挑战。
点对多点的复制功能 -交换矩阵的复制功能对其总容量有绝对的影响,一个 640G的交换矩阵如不能自行复制点对多点(组播,Multicast)的流量,则其总容量,在大量的多点广播的业务环境中,会出现大幅度缩减,因此,一个优秀的交换矩阵必须要能自然地(天生)支持点对多点的复制功能。
总容量 - 交换矩阵的总容量决定系统本身的吞吐能力及支持的板卡种类。在考虑前述的几个因素下,我们将对常见的五种交换矩阵做检视 (examine)。
下列是五种常见的交换矩阵系统:
* 共享式内存 Shared Memory
* 全连接 Fully Meshed Connections
* 多方存取的数据总线 Multi-access BUS
* 交叉 矩阵交换 CrossBar Switch
* 空间域多级交换矩阵 Space-domain Staged Switching Fabric
共享式内存
共享式内存作为交换矩阵的基本动作原理是利用共享的内存作为帧的交换点。对于交换矩阵而言,输入板卡将帧存入共享的内存中,并同时将帧内的必要讯息, 如 MPLS的SHIM HEADER,IP的原地址及终点地址等,连同帧在共享内存的位置存入原始排序,交换晶片利用这些存于原始排序的资料找寻出输出板卡及二层封装的讯息,连同帧在共享内存的位置存入输出板卡的排序中,输出板卡利用排序中的资料将帧从共享式的内存中读出,并将帧加上适当的二层封装后,由物理端口送出。
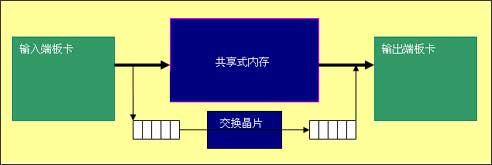
共享式的内存是用记忆体所组成,不像是查找路由,需要高速的定址能力,共享式的内存需要有的是高速的吞吐能力。
同步静态记忆体( SSRAM )的工作周期短,又不需要更新( refreshing ),但是其造价昂贵,且容量低,因此,同步静态记忆体更适合存放路由表,而并不适用于组成交换矩阵。
同步 动态记忆体( SDRAM)。单价低,容量大。但需要被周期性的更新,其吞吐能力也因为其较长的工作周期而不突出。解决这两个问题可以用多个交互更新的记忆体组-交互更新使得其中的一部分的记忆体组能交互地产出资料,而像是流水线的资料读取则可使吞吐能力大幅的提升。但是,使用多个记忆体组会使系统的数据接脚(data pins)快速的增加,造成系统的可服务性大幅下降。
分散式的共享内存,利用将记忆体组分散于不同板卡的方式,降低每块板卡所需的接脚个数,提高板卡的可服务性。分散式的共享内存,也利用分散于板卡上信元化的共享内存,提高了整个共享内存的吞吐能力,但整个共享内存的功能就变得与板卡的可用性节节相关,板卡一旦失效,整个共享内存就必须重组,排除失效板卡上的记忆体组,使得板卡成为(分散式)共享内存的单一出错点( single point of failure),因此,分享式的共享内存并不适合用于组成高冗余能力的交换矩阵。
点对多点的复制功能并不能自然地被共享式的内存交换矩阵所支持,因此,输出板卡的 DMA引擎必须从共享的内存多次拷贝来完成复制的功能,但是,这样的动作却会大量地消耗掉内存的带宽,使得这种交换矩阵,在这样得应用下,变得非常的低效能。
共享式内存的交换矩阵
提速比 冗余的能力 缓存的管理 延展性 复制功能 总容量 N:1 弱 佳 差 弱 不高全连接
将交换矩阵所有的输入联接至所有的输出是全连接交换矩阵基本的工作原理。对任何一个输出而言,均有到每一个输入的直接连接,因此,当有 N个输入时,任何一个输出都会有N个连接(包括对自己的环回),所以,全连接的交换矩阵的提速比是N:1.
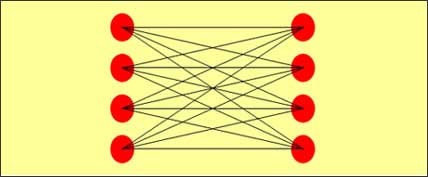
因提速比高的原因,全连接的交换矩阵不会在矩阵内出现阻塞。但是,当面临瞬间由多个输入输出端必须要有缓存的管理(如 WRED或排序限制),否则会造成排序溢出丢弃(Tail Q Drop)的现象,严重地扭曲QoS的policy.
提速比高的全连接交换矩阵也因连接的个数随着节点个数的增加而成平方的成长( N 2 ),因此,全连接的交换矩阵的延展性很差,如考虑冗余的能力(2×N 2 ),则将使此交换系统的延展性进一步的恶化。
全连接的交换矩阵不能支持点对多点的复制功能,因此,必须有输入板卡执行流量复制的工作。
从制造成本而言,全连接的交换矩阵随着节点个数的增加,连接的个数也将成平方的成长,每一条连接必须使用两颗 SerDes ASIC (Serialization and DeSerialization), SerDes ASIC 的运用解决了并行数据总线因高数目的接脚所引出的可服务性的问题(不易插拔板卡,并容易造成连接器针脚弯),但是,高数目的SerDes ASIC却使系统的制造成本大幅的提升。
全连接的交换矩阵
提速比 冗余的能力 缓存的管理 延展性 复制功能 总容量 N:1 弱 佳 差 弱 不高
多方存取的数据总线
多方存取的数据总线 ( Multi Access BUS)将所有的端口(或板卡)连接到同一的数据总线上,任何一方需要和任何一方或多方交换时,便要求总线时段(BUS Cycles)进行数据交换。取得总线时段的板卡(或端口)将数据依据(总线)协议放至总线上,一个或数个板卡(或端口)则同时从总线上将数据取出。
多方存取的数据总线,从结构上,非常像是一个有 N倍加速的交叉矩阵,N是端口的总数。
能自然地支持组播业务(点对多点)是用高提速比的多方存取数据总线作为交换矩阵的一大优势。不像是 交叉矩阵 ,总线上的任一端口都可以用一个总线周期,完成对所有端口的复制,因此这样的结构非常适合用于组播业务占绝对多数的环境。
提速比高的另一个优势则是简易的缓存管理。如果输入端的总流量没有超过交换矩阵的总容量,输入端的排序管理就没有太大的意义,但是,输出端的管理却总是需要的,但是,因为接近输出端口的原因,排序的管理只需要根据本地的物理或逻辑端口即可,不必考虑其他板卡或接口,大幅度的降低了缓存的管理工作。
大多数的数据总线的应用,都以不定长的帧( datagram)作为交换单元,因为不允许并行的交换同时进行,所以,没有交叉矩阵上常见的非同步等待,因此,用信元为交换单位和流水线的工作方式就没有太大的意义。
多方存取的数据总线有 N倍的提速比,因此,交换矩阵本身不易出现阻塞,但板卡(或端口)与交换矩阵的界面却也因为高提速比,变得非常的昂贵。高提速比的达成是利用高数量的总线,举例说,256条的总线,就算每一条的工作频率都在400MHz,这个矩阵的总容量也就只有100Gb,何况,总线的数目越高,背板和板卡之间的连接器针脚数也就越高,因而变得更难服务(当拔插板卡时)。因此,这种交换矩阵仅适用於中小型的网络设备。

用多方存取的数据总线作为交换矩阵
提速比 交换矩阵的输出速率与输入速率的比例 Blocking Ratio 堵塞率 DMA Direct Memory Access,不需处理器介入的记忆体读出及写入 WRED Weighted Random Early Disard Tail Q Drop 排序溢出丢弃,因排序满后而造成的丢包 SerDes ASIC Serialization and De-Serialization,将并行改为串行及串行改为并行的晶片。用以减缩背板的连接个数。 Scheduler 调度器,用于决定那些输入和输出可同时进行交换,避免冲突的发生。 HOL 头端阻塞(Head of Line Blocking) VOQ 虚拟输出端排序,放置於输入端的输出排序,用于避免 HOL VCSEL Vertical Cavity Surface Emitting Laser Pop Consolidation 合而为一路由政策(Consolidated Routing Policy) PAROLI并行光??路,由 CISCO,MOLEX 和 AMP共同设计的新型光连接系统 TCO Total Cost of Ownership, 总体拥有成本 Byte Slicing 字节切割,以字节为界,将整个包切割成数个小单元。
交叉矩阵交换
交叉矩阵交换,和它的名字一样,结构像是一个横竖交叉的矩阵,只不过横线(输入端)和竖线(输出端)并不直接相连,而是透过一个场效电晶体 (FET)将每一个横线与竖线连接。如此,只要控制场效电晶体的开关,便可以决定那个输入和那个输出(或那些输出)可以进行交换。矩阵交换的最大优点是允许多个相互不冲突的交换同时进行,并支持点对多点(Multicast)的交换。
像是其他的交换矩阵,交叉矩阵交换也有它在结构上的限制。首先,为了解决在交叉矩阵上常见的非同步等待( Asynchronous Wait)所造成的带宽浪费(特别是当提速比只有1:1时),交叉矩阵通常采用信元作为交换单位,任何一输入和输出都必须在一定的时间内,比如说 160us,完成固定字节的交换。整个交换矩阵采用同步的协议,每160us为一个周期,如此一来,就不会出现部份输出因其它(矩阵)节点仍在进行的交换而出现停顿的现象。
第一个在交叉矩阵常见的瓶颈则是调度器( scheduler),试想一个有着1024x1024交叉节点的矩阵,它的调度器需要在160us内完成一百万个场效电晶体的开关,当这个矩阵需要有四倍的容量扩容时,交叉节点的个数将从一百万个增加到一千六百万个,调度器也必须要在同样的160us秒内完成这一千六百万个场效电晶体的开关。以现今的半导体制造技术,这样的调度器根本无法制造(需要至少 1 TIPS),因此,必须以 多平面 的方式,限制(每一平面)输入的个数,才能延展这种矩阵。
第二个的瓶颈是因为要解决交叉矩阵上常见头端阻塞( Head of Line Blocking)所引出的大量的虚拟输出端排序(VOQ),减少排序的个数容易造成服务品质政策的扭曲,但除此以外,并无更好的办法解决这个瓶颈。
交叉矩阵的提速比,简单的说,就是横线 和竖线数目的比数。当横线与竖线的比例为 1:1时,这个矩阵的提速比就仅仅为一倍,并无任何的提速。当横线与竖线的比例为2:1或更高时,因提速比的提高,降低了矩阵出现阻塞的机会。
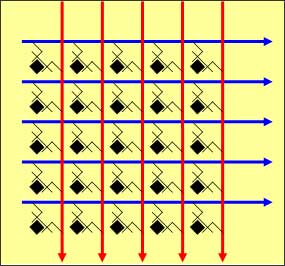
交叉矩阵交换
提速比 冗余的能力 缓存的管理 延展性 复制功能 总容量 1:1 or Better 佳 佳 佳 佳 高
空间域多级交换矩阵
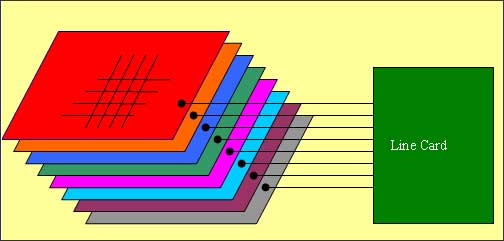
空间域多级交换矩阵是一种多级多平面的交换矩阵系统。它的动作原理是利用多个独立自主的交换矩阵,组成一个多级多平面的交换矩阵系统。多平面的设计是为了增进系统的冗余能力以及解决现行制造技术的瓶颈。多级的设计则是使系统具有动态扩展的能力,同时利用统计复用的原理,提升对于单一板卡(或端口)的提速比。
如同前述的几种交换矩阵,每一种结构都有它相对的架构限制,因此,我们利用一个系统来解决这些问题,而不是一种特定的技术。譬如说,空间域多级交换矩阵就是一种交换系统技术。
空间域交换矩阵(多平面交换矩阵)
单一平面的交换矩阵,或多或少,都面临不同的技术瓶颈。譬如说,这些矩阵或者是因为提速比太高,而使这种交换矩阵的界面,因为支持的高数目接口,变的太过于昂贵。或是因为提速比低,使得这种交换矩阵的输入端排序(虚拟输出端排序, VOQ),随着接口的个数的增加,成指数级成长。这些瓶颈的共同因数都是接口数目的增加,因此,限制一个交换矩阵的接口个数便成为解决这些技术瓶颈的不二法则。多平面的交换矩阵利用了多个并行的交换矩阵,使系统可以接纳的接口数和并行的交换矩阵数目成正比。
以下图而言,如果每一个平面均提供 16个6.125G的接口,这个有着8个平面的交换矩阵系统就能为16片40G的板卡作交换。
利用多平面的设计,解决了单一交换矩阵的限制,但是,多平面的设计却也带来了传送序列错误这个可能发生的问题,解决的办法有两种,一是允许传送序列错误的发生,但在矩阵的输出端将序列重新恢复,另一种办法是使交换矩阵平面之间同步,阻止传送序列错误的发生。下列是这两种办法的简述及其相对的优缺点:
修正传送序列错误
当多平面的交换矩阵相对独立时(非同步),可能会因为流量分配(于不同平面)的机制和流量本身的不匹配,而产生负载不均的现象,因而造成了传送序列错误。解决传送序列错误要求多平面的交换矩阵(系统)的输出端具有序列更正的机制,并利用回??( feedback)的机制,降低因丢包所造成的假传送序列错误。非同步的多平面交换矩阵使每一个平面均能独自工作,因此,具有较好的冗余能力,而平面之间的无关联性,则使任何元件仅仅受限於单一平面的输入个数,而不是系统(多个平面)的输入个数,使延展性能根据平面的个数提升。
同步所有的平面
当所有平面的交换矩阵成同步时,(交换矩阵)系统本身造成传送序列错误的现象被降到为零,但是,平面间的同步就随着速度(频率)的提高而变得艰难,同时,系统本身因同步的要求,同时间必须有一定数目平面的交换矩阵正常工作,因此,系统的冗余性也会有所降低。
上列两种解决方案都可以修正或阻止传送序列错误,但是在高容量(高工作频率)的前提下,利用输出端排序修正传送序列的错误是目前较经济的解决方案
多级交换矩阵
单级的交换矩阵从结构上相对的固定,因此,当面临升级时,必须更换原有的交换矩阵,造成 固定投资费用( CAPEX)的增加。因此当把总体拥有成本(TCO,Total Cost of Ownership)列入设计考虑后,新型的交换矩阵大多采用多级的交换矩阵系统,以期在面临升级时,仅仅需要增加新的交换矩阵及变更平面的组成方式,便可使系统的总容量成倍数成长。
在下图中的三级交换矩阵,第一级的交换矩阵( S1)和第二级的交换矩阵(S2)有两条连线。当这个交换系统只有两个输入及输出时,一个第二级的交换矩阵便可以组成这个交换系统。当这个交换系统需要扩容至四个输入及输出时,则只需要加入另一个第二级交换矩阵便可以组成两倍大的新交换系统,而原来系统中组件并不需要更换或升级,因此,保障了原有的投资,降低了总体拥有成本。
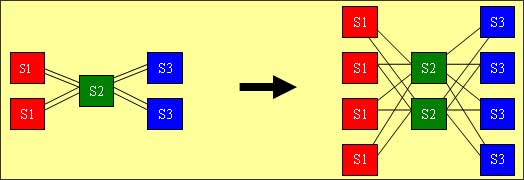
多级的交换矩阵系统通常会将第二级的交换矩阵单独置放,使系统能随时根据需求变更连接的方式,达到所需的交换容量。而系统的最大容量则受限制於第一级和第二级的交换矩阵之间的连接个数。不同级的交换矩阵之间,则使用大对数的并行光纤连接。
不同级的交换矩阵之间,通常也会进行提速,借此,降低在前一级交换矩阵堵塞的比率。再利用不同级之间的讯息隐藏,再不增加矩阵界面的制造成本的前提下,使得提速比得到数十倍的提升,更大幅度地降低了在前一级交换矩阵堵塞的比率,
空间域多级交换矩阵(多级多平面交换矩阵系统)
如果将多级交换矩阵系统的灵活性,配合非同步多平面交换矩阵系统的冗余性,将可使这样的交换矩阵系统能根据需求,在弹性地变更容量的同时,不会造成服务的中断。
空间域多级交换矩阵
提速比 冗余的能力 缓存的管理 延展性 复制功能 总容量 2:1 or Better特佳 佳 特佳 佳 特高交换矩阵的综合比较
交换矩阵种类 提速比 冗余的能力 缓存的管理 延展性 复制功能 总容量 共享式内存的交换矩阵 N:1 弱 佳 差 弱 不高 全连接的交换矩阵 N:1 弱 佳 差 弱 不高 多方存取的数据总线 N:1 佳 佳 差 佳 不高 交叉矩阵交换 1:1 or Better 佳 佳 佳 佳 高 空间域多级交换矩阵 2:1 or Better特佳 佳 特佳 佳 特高每一种交换矩阵都有其优缺点,但如果能被利用于能凸现它们相对的优点的应用时,那?N,它们便是该种应用最佳的交换矩阵。相反地,就有可能使其缺点暴露无遗。
共享式内存和全连接的交换矩阵延展性差,因此不适和用于大型须扩展的网络设备。它们的复制功能薄弱,也使它们不适用于有大量点对多点业务的环境。但是它们的结构简单,并能被快速地实现,适合于用为中小型网络设备地交换矩阵。
多方存取的数据总线和交叉矩阵交换都有良好地复制能力,因此,较适合应用于有大量的组播的应用。但从延展性的角度,交叉矩阵交换,因为较低的提速比,以及允许多个交换同时发生的原因,所以比多方存取的数据总线更适用于大型骨干网设备。可是也正因为这两个原因,使得交叉矩阵需要有大量得虚拟输出端排序以及高性能得调度器。降低物理(和逻辑)端口的个数可以帮助省却掉很多虚拟输出端排序,而使板卡的速率相符合则能减调度器的负载,由此推论,交叉矩阵非常适合由于核心骨干路由器。
互联网在中国,已经是连续数年以高于 250%的速率在增长,在不久的将来,单级单平面的交换矩阵就不能再承担核心骨干路由器的心脏。 空间域多级交换矩阵(多级多平面交换矩阵系统),将交换矩阵的输入分散于多个独立路由平面(良好冗余性,无调度器的瓶颈),再利用多级的结构,使矩阵本身具有重组的功能及较高的加速比。因此,应用空间域多级交换矩阵的核心路由器,配合合而为一的 路由政策(Consolidated Routing Policy),将可使互联网面向下一个十年的增长,使得互联网成为更有价值的网络平台。
Terminology and Definitio
提速比 交换矩阵的输出速率与输入速率的比例 Blocking Ratio 堵塞率 DMA Direct Memory Access,不需处理器介入的记忆体读出及写入 WRED Weighted Random Early Disard Tail Q Drop 排序溢出丢弃,因排序满后而造成的丢包 SerDes ASIC Serialization and De-Serialization,将并行改为串行及串行改为并行的晶片。用以减缩背板的连接个数。 Scheduler 调度器,用于决定那些输入和输出可同时进行交换,避免冲突的发生。 HOL 头端阻塞(Head of Line Blocking) VOQ 虚拟输出端排序,放置於输入端的输出排序,用于避免 HOL VCSEL Vertical Cavity Surface Emitting Laser Pop Consolidation 合而为一路由政策(Consolidated Routing Policy) PAROLI并行光??路,由 CISCO,MOLEX 和 AMP共同设计的新型光连接系统 TCO Total Cost of Ownership, 总体拥有成本 Byte Slicing 字节切割,以字节为界,将整个包切割成数个小单元。
- 核心路由器的交换矩阵设计
- 有路由器完整的三层交换网络
- 交换器和路由器的区别
- 路由器和交换的本质区别解析
- 路由器和交换的本质区别解析
- 路由器和交换器的区别
- 路由器和交换的区别解析
- 新一代的核心路由器的发展趋势分析
- 猫,路由器,交换器
- 谈多层交换路由器的架构演进 (2)
- 谈多层交换路由器的架构演进 (1)
- zip的妙用--矩阵行列交换
- 矩阵行或列的交换
- matlab 交换矩阵的行和列
- 核心板的设计
- Hadoop的核心设计
- 核心路由器十项性能指标
- 核心路由器十项性能指标
- MFC树控件应用实例
- CentOS添加永久静态路由
- Java中的instanceof关键字(转)
- Thread
- MapBalanceReduce介绍
- 核心路由器的交换矩阵设计
- 安装程序的制作
- Visual Assist X最新版本 10.6.27
- 关于Java中的二维数组
- ORACLE SQL搜集
- 集合时少用数组,用iList,少用list
- 正则表达式 应用
- 网站发布图解
- linux下安装mysql的方法


