EXISTS、IN与JOIN性能分析
来源:互联网 发布:快递不送货上门 知乎 编辑:程序博客网 时间:2024/04/30 22:21
EXISTS、IN与JOIN,都可以用来实现形如“查询A表中在(或不在)B表中的记录”的查询逻辑。
在论坛上看到很多人对此有所误解(如关于in的疑惑、用 外连接 和 Is Null 代替 not in两帖),特做一简单测试。
测试结果: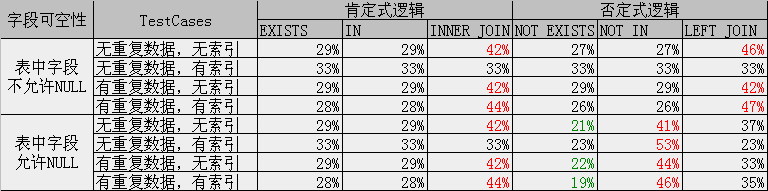
测试代码较长,附于本帖最后。
图表中百分数表示同一组3个查询的执行时间比例。红色表示3个语句中最慢,绿色表示3个语句中最快的,并列则没加颜色。
其中索引只测试了聚集索引,当表中字段较多且查询字段是非聚集索引时,选择执行计划的条件比较复杂,没有测试。并且当表中数量变化后,执行计划可能也有差异。图表反映了3种查询方式的解析机制的不同,基本结论是类似的,但具体情况还要视执行计划而定。
分析结论:
通常情况下,3种查询方式的执行时间:
EXISTS <= IN <= JOIN
NOT EXISTS <= NOT IN <= LEFT JOIN
只有当表中字段允许NULL时,NOT IN的方式最慢:
NOT EXISTS <= LEFT JOIN <= NOT IN
综上:
IN的好处是逻辑直观简单(通常是独立子查询);缺点是只能判断单字段,并且当NOT IN时效率较低,而且NULL会导致不想要的结果。
EXISTS的好处是效率高,可以判断单字段和组合字段,并不受NULL的影响;缺点是逻辑稍微复杂(通常是相关子查询)。
JOIN用在这种场合,往往是吃力不讨好。JOIN的用途是联接两个表,而不是判断一个表的记录是否在另一个表。
编程建议:
(以下三条建议中EXISTS和IN同时代指肯定式逻辑和加NOT后的否定式逻辑)
如果查询条件是单字段主键(有索引且不允许NULL),则EXISTS和IN的性能基本一样,IN的查询通常写法简单、逻辑直观。
如果查询条件涉及多个字段,则最好选择EXISTS,千万不要用字段拼接再IN的方式(索引会失效)。
如果条件不确定,选用EXISTS是最保险的办法,性能最好,不受三值逻辑影响(EXISTS只会返回True/False不会返回Unknown),但代码逻辑稍稍复杂,思路要理清楚,而且相关字段最好采用“表(别)名.字段名”的形式。
附一:IN/NOT IN容易出现的两个问题
参看如下代码:
[code=sql]
SELECT
EmployeeID = n,
EmployeeName = 'E' + RIGHT('000' + CAST(n AS varchar(10)),3)
INTO #Employees
FROM dbo.Nums WHERE n <= 10;
SELECT EmployeeID
INTO #Badboys
FROM (SELECT TOP(4) EmployeeID = n FROM dbo.Nums WHERE n <= 10 ORDER BY NEWID()) tmp
UNION
SELECT NULL;
--问题1:
SELECT * FROM #Employees WHERE EmployeeID IN (SELECT EmployeeID FROM #Badboys);
SELECT * FROM #Employees WHERE EmployeeID NOT IN (SELECT EmployeeID FROM #Badboys);
--问题2:
SELECT * FROM #Employees WHERE EmployeeName IN (SELECT EmployeeName FROM #Badboys);
SELECT * FROM #Employees WHERE EmployeeName NOT IN (SELECT EmployeeName FROM #Badboys);
[/code]
其中:
问题1是三值逻辑的问题,说明了在NOT IN遇到NULL时要特别小心(参看关于 not in的疑问一帖)。这也是为什么建议“如果可能,尽量让所有字段都声明为NOT NULL”的原因之一。
问题2是SQL Server子查询处理时命名空间解析的漏洞,说明了在多表查询中采用“表(别)名.字段名”的形式的好处,否则就要对字段名的拼写非常小心。
附二:EXISTS、IN与JOIN性能分析测试代码:
[code=sql]
--表中字段不允许NULL
--TestCase1: 无重复数据,无索引
CREATE TABLE T1(n int NOT NULL);
CREATE TABLE T2(n int NOT NULL);
INSERT INTO T1
SELECT n FROM dbo.Nums WHERE n <= 100;
INSERT INTO T2
SELECT n FROM dbo.Nums WHERE n <= 100 AND n % 2 = 0;
--TestCase2: 无重复数据,有索引
CREATE UNIQUE CLUSTERED INDEX IX_T1 ON T1(n);
CREATE UNIQUE CLUSTERED INDEX IX_T2 ON T2(n);
--TestCase3: 有重复数据,无索引
DROP TABLE T1;
DROP TABLE T2;
CREATE TABLE T1(n int NOT NULL);
CREATE TABLE T2(n int NOT NULL);
INSERT INTO T1
SELECT n FROM dbo.Nums WHERE n <= 100;
INSERT INTO T2
SELECT n FROM dbo.Nums WHERE n <= 100 AND n % 2 = 0
UNION ALL
SELECT n FROM dbo.Nums WHERE n <= 100 AND n % 3 = 0;
--TestCase4: 有重复数据,有索引
CREATE CLUSTERED INDEX IX_T1 ON T1(n);
CREATE CLUSTERED INDEX IX_T2 ON T2(n);
--表中字段允许NULL
--TestCase5: 无重复数据,无索引
DROP TABLE T1;
DROP TABLE T2;
CREATE TABLE T1(n int NULL);
CREATE TABLE T2(n int NULL);
INSERT INTO T1
SELECT n FROM dbo.Nums WHERE n <= 100;
INSERT INTO T2
SELECT n FROM dbo.Nums WHERE n <= 100 AND n % 2 = 0;
--TestCase6: 无重复数据,有索引
CREATE UNIQUE CLUSTERED INDEX IX_T1 ON T1(n);
CREATE UNIQUE CLUSTERED INDEX IX_T2 ON T2(n);
--TestCase7: 有重复数据,无索引
DROP TABLE T1;
DROP TABLE T2;
CREATE TABLE T1(n int NULL);
CREATE TABLE T2(n int NULL);
INSERT INTO T1
SELECT n FROM dbo.Nums WHERE n <= 100;
INSERT INTO T2
SELECT n FROM dbo.Nums WHERE n <= 100 AND n % 2 = 0
UNION ALL
SELECT n FROM dbo.Nums WHERE n <= 100 AND n % 3 = 0;
--TestCase8: 有重复数据,有索引
CREATE CLUSTERED INDEX IX_T1 ON T1(n);
CREATE CLUSTERED INDEX IX_T2 ON T2(n);
--Foreach TestCase above,分别执行以下两组语句并观察执行计划:
--肯定式逻辑
SELECT T1.*
FROM T1
WHERE EXISTS (SELECT * FROM T2 WHERE T2.n = T1.n);
SELECT T1.*
FROM T1
WHERE T1.n IN (SELECT T2.n FROM T2);
SELECT DISTINCT T1.* --不加DISTINCT可能会引起重复
FROM T1
INNER JOIN T2
ON T1.n = T2.n;
--否定式逻辑
SELECT T1.*
FROM T1
WHERE NOT EXISTS (SELECT * FROM T2 WHERE T2.n = T1.n);
SELECT T1.*
FROM T1
WHERE T1.n NOT IN (SELECT T2.n FROM T2);
SELECT T1.*
FROM T1
LEFT JOIN T2
ON T1.n = T2.n
WHERE T2.n IS NULL;
--End Foreach
--清场
DROP TABLE T1;
DROP TABLE T2;
[/code]
EXCEPT只用于计算两个相同结构的表的差集。
对于“查询A表中在(或不在)B表中的记录”这样的查询,如果B表和A表的结构不相同,怎么用EXCEPT?难道先用主键EXCEPT再IN一下吗?
Garnett_KG :
用执行计划的所占成本比例去判断这三种写法的快慢是有失偏颇的
数据量、数据分布、索引可选择度才是关键,重点是要让引擎很好的知道你写的查询的目的,让引擎可以做到最优
化,具体选择in/exits/join不是很重要。
拿你的例子来说,不允许NULL、无索引、无重复数据的情况下,LEFT JOIN成本最高,去到46%
但是将数据变化一下,T1加到1W笔,T2加到5000笔,LEFT JOIN产生的计划就会发生变化,跟in/exists的成本会变得差不多。
所以单纯的从写法角度来说,不能去判定其快慢的
KG说的有道理。
大数据量情况下,索引才是性能的关键,而3种写法的差异对性能的影响很小,几乎可以忽略。
其实我只是为IN/NOT IN打抱不平而已,很多人动不动就说JOIN比IN/NOT IN好。而事实上,用JOIN来实现“查询A表中在(或不在)B表中的记录”的查询逻辑通常并不合适(性能、逻辑、代码可读性)。
说明一点:这里拿EXISTS、IN与JOIN比较,都是在实现“查询A表中在(或不在)B表中的记录”查询逻辑的前提下进行。
如果是多表联接操作,当然是JOIN,无可取代。
- EXISTS、IN与JOIN性能分析
- EXISTS、IN与JOIN性能分析
- EXISTS、IN与JOIN性能分析
- EXISTS、IN与JOIN性能分析
- SQL Server-聚焦IN VS EXISTS VS JOIN性能分析
- IN EXISTS JOIN 用法分析
- In & Exists & Join 分析测试
- In & Exists & Join 分析测试
- In & Exists & Join 分析测试
- 浅谈sql中的in与not in,exists与not exists的区别以及性能分析
- EXISTS、IN、NOT EXISTS、NOT IN的区别与性能分析 (转载)
- EXISTS、IN、NOT EXISTS、NOT IN的区别与性能分析
- inner join 与 exists 性能比较
- Inner Join 与 Exists 性能对比
- exists、in区别与性能
- not in,not exists,left join性能对比
- JOIN、IN、EXISTS效率
- oralce中in和exists性能分析
- 有点成就感了
- c# 改变无边框窗体大小 张宇轩
- CSS书写规范参考
- c# 鼠标拖动控件 张宇轩
- Debug Staf Service
- EXISTS、IN与JOIN性能分析
- 学习C#修饰符:类修饰符和成员修饰符
- oracle 中 create table tb_content_bak as select * from tb_content where 1=2 long字段解决办法
- Winform中DataGridVieW进行ContextMenuScript操作获取右键选定行指定列的值
- mysql基本命令
- CSS解决未知高度垂直居中方法
- CSS解决未知高度垂直居中方法
- C程序设计语言(第2版)摘要
- 设计模式(C++实现)之Command


