基于CUDA的光线跟踪算法
来源:互联网 发布:软件新技术有哪些 编辑:程序博客网 时间:2024/05/01 12:24
光线跟踪是目前常用的主流绘制技术之一,由于它能方便地模拟生成复杂的光照效果,生成高质量的图像,在很多领域得到了广泛的应用,如真实感绘制,虚拟现实,可视化,计算机动画等。但光线跟踪算法的计算开销较大,妨碍了其应用效率。光线跟踪渲染的主要运算操作耗费在光线与场景求交的过程中,为此,为了加快这一计算过程,人们研究了大量的技术来加快求交操作。其中,通过建立一定的空间组织结构来加速求交计算机取得了很大的进展,如基于场景的空间层次划分结构等。
对场景进行层次化的树形结构划分与组织,可使得空白区域能以较大的结点表示,从而减少光线穿过空白区域的开销。目前已经被学者提出肯经常使用的空间划分方式有均匀网格划分、层次包围划分、八叉树、KD-Tree等,这些方法在此前论文中均有所研究,且都得到了相应不错的加速效果。而其中最为常用、且被证明效果较好的当属KD-Tree。
1. 基于KD-Tree的场景空间划分
为了对场景与光线相交的碰撞检测过程进行加速,对场景的空间划分组织不可缺少。当前主要使用的空间划分技术有基于空间划分的均匀网格,八叉树,KD-Tree等,
以及结合这几个划分方式的混合结构。这些结构各有特点,需要根据所处理的场景的特点及绘制任务进行相应的划分方式的选择,没有哪一种空间划分方法能
最优地处理各种场景。不过这些通过空间划分来对光线和场景之间的相交检测进行加速的基本原理相同,即是将场景中的原始几何体元抽象化后向上层组织,比
如以包围盒的形式,通过首先对包围盒进行与光线的碰撞检测进而来排除那此不可能与光线相交的几何体元与光线之间的相交测试。
1.1 KD-Tree的优势
针对不同的场景可以有不同的空间划分方式,不过当前对于光线跟踪所使用的主流空间划分方式为KD-Tree,这主要是因为以下几个原因:
1. KD-Tree是一种特殊的BSP树,它将BSP划分中的任意分割平面退化为轴对齐的分割平面,这样就降低了BSP生成时的几何体元分割操作。但是它却同样具有BSP树
的优良特征,即一定程度上的启发式空间划分,这样可以使得到的最终划分二叉树尽可能地平衡,这样就降低了最坏情况下的光线与划分结构之间的求交次数,进而提升的效率。
2. 由于KD-Tree是一种二叉树,因此在遍历的时间就要比八叉树等非二叉树的划分结构更简单,这也推广了它的使用范围。
3. 最后,很重要的一点是由于二叉树遍历的简易性可以使它们比较容易移植于不支持堆栈递归结构的GPU之中。
鉴于KD-Tree所具有的上述优良特性,本文在实现中也采用了KD-Tree的结构来对空间场景进行划分。
1.2 KD-Tree的创建
KD-Tree的创建过程是一个自顶向下的递归过程,从根结点开始执行向下的空间划分,空间划分过程中最主的操作就是对分割平面的选取。KD-Tree中各结点的分割平面
相对于八叉树、均匀分割等划分结构的分割平面增加了一个自由度,但相对于BSP分割中的任意方向的分割平面却又降低了一个自由度。KD-Tree的分割平面均是轴对齐的,
这样就可以直接确度分割平面的法向量,接下来主要做的就是对此有向平面在轴对齐方向上进行定位。而这里对分割平面进行定位的基本原则即是使得到的整棵KD-Tree尽可
能的平衡,这也就要求将当前结点中的几何体元尽可能均匀地分配到两个子结点中。对于网格组成的三维场景,这里的几何体元主要为三角形,因此现在的问题就转化为
对当前结点中的三角形的分配问题。
给定一个含有n个三角形的KD-Tree结点,假设需要定位其在X方向上的分割平面。由空间知识可得任意三角形与其可能的分割平面
有三种相对位置关系,即:与平面相交、处于平面前方(相对于其法向)、处于平面后方。对于不相交的这些三角形,在产生子结点时直接分配即可,对于相交的三角形,则需要在产生子结点时进行分割。一个三角形被平面分割后可能产生多个三角形,而且根据分割平面所处的位置不同对三角形的分割方式也不同。如果将这些相交的三角形分割后所得到的子三角形的数目也考虑到分割平面的选取中则增加了很多计算量,而且通过分析可得知,在一个结点中与分割平面相交的三角形数目要少于不相交的三交形数目,因而可以在分割平面的选择时不考虑这些处于相交位置的三角形的影响。这样就可以在生成子结点时较快得到分割平面。不过在一个法向量方向上潜在的分割平面又有无数种位置可能,在实践中只能取一种近似的操作,这里采用一种常用的方法,即使用几何体元的AABB包围盒在分割平面法向上的位置来作为分割平面的潜在位置。这样既确定的潜在平面的分布位置,又有了分割平面的选取标准,接下来要做的就是从潜在分割平面中选取一个最优的分割平面。
设当前结点的潜在分割平面集全为![]() ,每个分割平面所对应的三角形位置集合为
,每个分割平面所对应的三角形位置集合为![]() ,则最优分割平面pb的选择可由下式来确定:
,则最优分割平面pb的选择可由下式来确定:
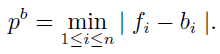
在上式中潜在分割平面的数量为当前结点中三角形数量的2倍速,这是由于每个三角形的AABB在轴对齐的两端均确定了一个潜在的分割平面。分割平面确定之后即相当于完成了对当前结点的分割操作,接下来要做的就是根据与分割平面的相对位置关系,将三角形或直接或者分割后分配到不同的子结点即可。对当前结点分割完成这后再递归地对子结点进行上述操作直到叶子结点。叶子结点的定义也有多种方法,可以是树创建到一定深度后,此深度之后的结点即为叶子结点,也可以上结点中三角形的数目达到一定数量之后,再少于该数值的结点即为叶子结点。本文中采用的方法是当结点中三角形的数目少于一定数量之后即成为叶子结点,到达叶子结点之后当前分割操作即可停止。
2. 无堆栈的空间二叉树遍历
使用空间划分对三维场景进行有机地合理组织以后,整个场景在抽象上即变成为一树形结构,而光线与场景的求交加速算法正得益于这样的树形结构可以快速地排除无关结点的影响。基于树形结构的光线求交算法也即转化成为树的遍历问题。根据光线跟踪问题的特点,多数情况下是需要求解与当前光线最近的几何体元的相交点,因此在空间划分树进行遍历时多采用深度优先遍历方法。深度优先遍历方法即是在当前结点同时有子结点和兄弟结点时,其下一步的搜索对象是其子结点而非兄弟结点。对于树的遍历也是一种递归结构的调用过程,对每个结点均执行相同的操作,这种遍历算法在传统的CPU上实现很容易借助于堆栈就可以实现这样的操作。不过在GPU上,由于其无类似的堆栈结构故而也就不支持这样的递归调用操作,因此对空间二叉树的遍历就不能采用传统的递归调用方法来实现。在本文中使用一种无堆栈的方法来实现GPU平台的空间二叉树遍历。
2.1 无堆栈解决方案
本文中的无堆栈解决方法其实也可以理解为模拟堆栈的解决方法。由于在对空间分割树进行遍历过程中采用了深度优先搜索,因此对于搜索路径的选取就存在一个由当前结点向上回溯的过程,即需要不断的由子结点向上寻找到其相应的父结点。在CPU的堆栈中可以方便的利用递归特性,依次将父结点子结点入栈,这样在退出子结点之后,接着出栈即可得到相应的父结点。而在GPU上无法利用硬件这样实现,但却可以模拟这样的一个过程,建立一个类堆栈的结构,通过使用一些变量来记录一些数据,从而来记录当前搜索的路径,在向上回溯时利用已有的路径求得待搜索的路径。比如在当前结点处,我们可以使用一组数据来当前结点的标号,子结点的状态等来存储当前搜索的方向,如果它的一个孩子的状态为已经遍历过,则在回溯到此结点时则不需要再向该子结点搜索,对其它的子结点做同样的操作即可模拟地实现回深度优先搜索的效果。
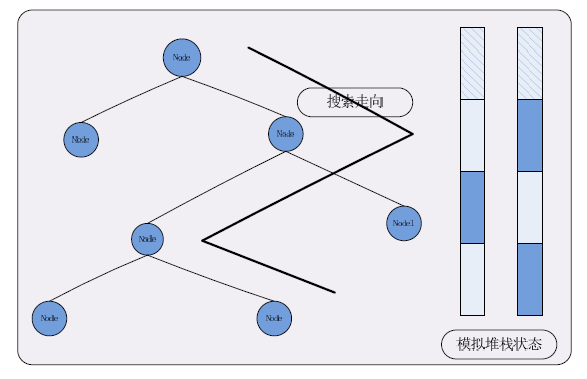
图1. 在对空间二叉树进行无堆栈遍历过程的操作示意图。
2.2 具体实现细节
空间树无堆栈遍历的主要实现策略是建立虚拟的类堆栈结构来记录结点的信息,从而实现控制遍历的走向。我们需要对每个结点记录相应的状态,在遍历中对于每个结点也只有两种状态:已遍历过、末遍历过,互斥的两种状态很容易使用开关值来进行标记。同时对于二叉树来说,每个结点又最多有两个子结点,故而在当前结点上的遍历方向也最多有两种状态。这样归结下来就可以得到对于每个结点需要两个开关值来记录遍历过程在此结点处的走向。对于开关值最节省空间,且判断效率较高的一种表示方法即是使用位来表示,而且对场景划分得到的二叉树的深度有限,因而可以在预测范围内使用一定字长的变量来表示一个一定深度的二叉树遍历模拟堆栈。基于GPU的无堆栈空间划分二叉树的遍历主要以下述方法实现:使用两个int来表示两个深度为64的模拟堆栈,每个模拟堆栈中的每一位记录当前结点的了个子结点的状态,通过在当前结点处从模拟堆栈中通过位操作来得到其子结点的状态,从而控制遍历的方向而实现深度搜索或是向上回溯。
3. 基于GPU的加速光线跟踪算法
光线跟踪是计算机图形学领域的经典算法,它主要是模拟现实现世界中的成像原理,通过对每个像素进行着色。这其中主要涉及以下个问题:光线如何传递、光线传递到什么位置中止、光线所得到着色值。光照到达物体表面时,物体会对光发生反射、透射、吸收和折射等,对所有这些情况进行处理涉及复杂的光照模型。在本文中为了抽象并简化问题的实现,使用了当前在硬件渲染管线中所主要采用的Phong光照模型。它主要在光线与场景的交点处根据物体的材质计算相应的specular、diffuse值来确定像素的颜色值。光线跟踪的过程就是从屏幕中的像素点出发,计算该点处光线的方向,然后在此方向上对场景进行遍历然后进行着色计算,这里主要有两个问题:1. 光线的产生问题,2. 光线与场景的碰撞检测问题。传统的于CPU上实现的光线跟踪算法对于这两个问题只能串行地进行处于,首先,对于每条光线,生成光线的基本参数,然后利用空间划分结构与此条光线进行碰撞检测,最后在碰撞点对像素进行着色。对于折射及反射效果则只需要碰撞点再进行二、三级光线的生成,并重复上述的着色过程,最后对原始像素进行着色效果的叠加,最后即可以得到具有反射、折射效果的高质量渲染图像。由上述分析可知,对于每个像素进行着色时,不存在像素间的依赖,即在当前层的光线中不存在依赖,因而这就具有很好的并行性。而光线跟踪与GPU平台上的并行化实现也下在是利用这一并行特性而进行高效的实现。
并行化的GPU光线跟踪算法结构如下图所示:

图2. 基于GPU的并行化光线跟踪算法结构。
总体来说,光线跟踪在GPU上的实现主要有以下几个并行部分:
1. 对于光线生成的GPU并行化。这里对每个光线均独立地生成相应的基本参数。
2. 对于光线与场景碰撞检测及着色过程的并行化。由于同一层的光线之间在着色时并没有相素依赖关系,因而就可以并行地对每一条光线进行处理。
4. 优化细节
使用上述算法实现基于GPU的光线跟踪算法以后,可以根据具体的需求对算法进行再优化,这里主要涉及一些细节方面的优化。虽然算法的整体效率是由算法的架构来决定,
不过通过对细节上的优化也可以在很大程度上提升算法的执行效率,特别是专门针对GPU架构的有针对性的优化操作。
1. 在KD-Tree创建时,首先采用均匀分割,当三角形数目达到一定数量时采用最优分割面的选取分割,这样可以提高KD-Tree创建的效率。
2. 将KD-Tree信息、场景原始几何数据,分别归类存放于不同纹理之中,通过纹理参照在需要进行同类型数据的访问。这样一方面可以利用纹理提供的虚拟cache提高数据访问时的效率,另一方面相关数据的打包存放又减少了相同数据的重复访问次数,减少了访问的延时。
5. 实验结果与结论
最后在实现上述算法并进行相应细节上的优化操作之后,通过实验对算法的整体性能进行了测试。实验时所采用的PC平台为Windows 32位操作系统,处理器和内存为:Intel Core Duo CPU 2.8GHz, RAM 2.0GB,所使用的显卡GPU支持为GTX 260。算法的核心部分在GPU版本与CPU版本均做相同的操作,并且均对代码进行了相就应的优化。对于几个典型测试场景的光线跟踪效果图片见于下图所示:

图3. 对几种典型场景进行基于GPU的光线跟踪所得到渲染结果,从图中可以看出使用基于GPU的光线跟踪算法可以得到较高质量的渲染效果。
如图所示,可见利用GPU的高效浮点运算能力可以得到高质量的渲染图像。而且算法最重要的是相对于传统CPU上的光线跟踪算法有重要的性能提升,通过对渲染时间进行测试,统计得到如下的算法执行进间与加速比:
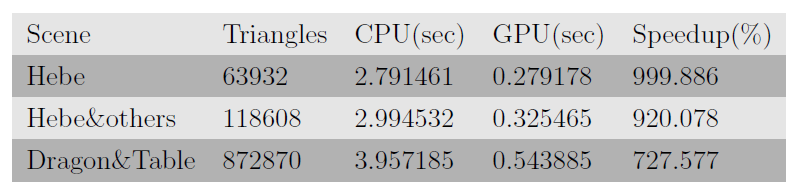
表1. 对几个典型场景进行渲染测试所得到时间列表。测试进所使用的GPU平台为GTX 260,从上表中可以看出将算法合理并行化后移植于GPU平台得到了乐观的加速比。
通过实验说明合理地对光线跟踪算法进行并行化后,利用CUDA提供的GPU高效加速运算效果可以显著地提高传统的光线跟踪算法的效果,这也为这一经典、但却耗费大量运算资源的经典算法注入了新的生命活力。
6. 将来的工作
将光线跟踪算法在GPU上进行高效地实现为GPU的推广和应用提供了有力的支持,在将来的工作中针对光线跟踪及其它图形学领域的渲染算法实现与改进将主要集中于以下几个方面:
1. 针对GPU数据存取的延时问题,虽然通过利用texture的存取方式可以在一定程度上解决这个问题,不过延时仍然限制了算法的效率。一种解决方法就是对光线进行pcaket打包,这样对于一种光线的遍历就可以扩展为同时对多条光线的遍历,这样就节省了反复对存global memory中的大量数据访问,从而提升算法的执行效率。
2. 由于GPU对大量数据通过纹理的方式进行访问可以得到硬件的虚拟cache的支持来提高访问效率,因此更好地利用这一特性就可以减少执行的延时。通过分析可以得到如果相邻的光线之间的关联性较大,即相邻的光线之间在KD-Tree中的遍历路线大致相同时,这样就要在相邻的光线遍历KD-Tree时合理地重用一些资源,这样就也提高了效率。将来工作的一方面就是研究这样的一个问题,通过对光线进行再分析,而实现更合理地有机组织,比如对光线根据方向进行一种排序,从而提高算法的效率。
3. 利用GPU的高并行处理特性,在将来的研究与实践工作中将尝试将更多的计算机图形学领域的算法利用CUDA来进行加速,如光子映射、辐射度算法等基于物理的经典、大耗时算法。
- 基于CUDA的光线跟踪算法
- 基于CUDA的光线跟踪算法 .
- 光线跟踪的算法
- 光线跟踪的算法
- CUDA 交互式光线跟踪
- 基于体积绘制的光线跟踪技术
- 光线跟踪算法
- 光线投射算法与光线跟踪算法
- 光线投射与光线跟踪算法归纳
- 光线跟踪的基本原理
- 读《光线跟踪算法技术》
- RayTracking 光线跟踪算法 集总
- 光线跟踪算法描述—计算机图形学
- 光线跟踪
- Physically Based Rendering,PBRT(光线跟踪:基于物理的渲染) 笔记
- 计算机图形学之光线跟踪算法的研究与实现2017年我的优秀毕业论文
- 计算机图形学之光线跟踪算法的研究与实现2017年我的优秀毕业论文
- 计算机图形学之光线跟踪算法的研究与实现2017年我的优秀毕业论文
- oracle的管理工具OEM以及重建索引
- 软件工程——第八章 用户界面设计(一)
- (myls)模拟" ls "命令
- linux root 密码忘了怎么办?
- 脱机安装Silverlight Tools(2.0)
- 基于CUDA的光线跟踪算法
- 使用客户端脚本(RegisterClientScriptBlock ,RegisterStartupScript )
- MOSS2007支持AJAX的配置
- 面向对象总结(1)--------面向对象的基础
- 32行演绎16种设计模式
- 获取指定日期的两位的小时和分钟
- 软件工程——第十章 软件工程管理
- 容易被忽略的JAVA赋值操作
- 软件工程——第十一章 软件项目管理


