PE文件导入表
来源:互联网 发布:美元指数软件 编辑:程序博客网 时间:2024/04/30 07:10
在上一篇文章里,我使用一个 TreeList 控件,展示了 PE 文件的内容。在那里可充分了解PE的文件头的信息,但是对 section(备注:常见译文为节,段,块)的一些信息我们还没有涉及。比如全局变量等数据,代码,资源,导入表等信息都位于相应的 section 中,有些 section 通常具有特定的名字,例如资源通常位于 .rsrc,代码通常位于 .text,导入表通常位于 .idata 段,等等。文本讲述的是把一个PE文件的导入表打印出来。我注意到 MS 提供了一个比较有用的函数,ImageRvaToVa,我们稍后主要借助这个函数去从RVA定位我们的目标数据。
在开始之前,我们先做一些概念的定义和说明。
Image: PE格式镜像文件,这通常就是我们的exe,dll文件。
下面我们定义一些地址相关的概念,因为PE文件位于磁盘上,同时文件又可以被映射到虚拟内存中,在运行PE文件时它也被系统的Loader加载到内存中。所以这里就有了三个空间,如果我们不做一个清楚的说明,在后面我们很容易混淆。
(1)磁盘空间:这里我们使用的地址叫做文件地址(距离文件头部的偏移)。在PE头的相关属性名称中,文件中的数据称为原始数据 (rawData),文件中的数据使用的对齐称为 FileAlignment。
(2)虚拟内存空间:在这里的地址称为虚拟地址(Virtual Address)。同时PE文件的数据装载/映射到内存中后又分以下两种情况:
(a)PE文件的内存视图,即PE文件被映射到内存(MapViewOfFile):
BaseAddress:内存映射文件的基础地址,从这里看过去,就和从编辑器打开看到的文件内容完全一致。
内存映射通常是处理大文件的一种有效方式。映射后我们在内存中看到的内容就是磁盘文件的一个视图。
因此我们吧PE文件映射到内存以后,通过某个数据的RVA,调用 ImageRvaToVa 可得到某个数据的VA,再减去映射文件的起始地址,就是文件地址。
(b) 进程空间,即在被调度之前,被loader装载到内存的时刻(例如双击执行一个exe)。
这里和前者的视图方式不同,属于一种地址映射关系,文件中的节内容根据NT文件头的信息被加载到进程空间的相应位置。
ImageBase:映射到进程空间的基础地址。
RVA:相对ImageOfBase的偏移。它加上ImageBase就是进程空间的VA。
在PE文件中的DataEntry,Section表中的VirutalAddress基本都属于RVA。
下面介绍以下这个函数:ImageRvaToVa:(注意这个函数要求XP和win2000系统以上,在VC6自带的SDK中没有。。。)
PVOID ImageRvaToVa(
PIMAGE_NT_HEADERS NtHeaders,
PVOID Base,
ULONG Rva,
PIMAGE_SECTION_HEADER* LastRvaSection
);
这个函数在(2).(a)即内存映射文件后使用,它把RVA根据NT头的信息,换算成内存映射文件中的实际VA。看起来不是在进程空间使用的,因为在进程空间中,ImageBase + Rva 就是VA了,装载后NT头等信息也不再重要了。最后一个参数是可选的,或许是因为如果调用方主动提供,此 API 可提高一定效率(可以直接在节中的地址信息去判断)。第二个参数也可以提供一个假的地址给这个函数,这个函数也能计算。即这个函数不去校验Base是否是一个有效地址,因此实际上我们可以读取出NtHeader的信息后,用一个假地址传给这个函数,再把结果减去这个假地址,即可换算出文件地址。
好了,下面介绍下导入表的定位,这方面的资料和文章在看雪论坛的文集里面有很多。我再这里只做一个比较简洁的介绍。导入表本质上就是位于某个节中的一些数据,这些数据主要是一些C字符串(以0字符为结尾的dll和函数名称)以及一些指针(RVA地址),所以我们主要是需要了解如何定位到导入表,从而打印出导入表的信息。
首先导入表的RVA地址,就在optional Header的DataDirectory的第二个元素中。通过它我们定位到导入表。
导入表类似一个二级索引。一级是一个模块目录(IMAGE_IMPORT_DESCRIPTOR数组,这里把目录理解为一个以全0字节为结束的数组),它的每个元素代表了一个DLL。二级是导入地址表IAT(即 IMAGE_THUNK_DATA 数组,一个指针数组),每个元素指向一个 IMAGE_IMPORT_BY_NAME结构(该结构含有一个函数序号和一个函数名称字符串)。
总结一下,我们的定位过程:
(1)通过 NtHeaders.OptionalHeader.DataDirectory[1].VirtualBase --> 定位到导入表(IID Table)。
(2)遍历每个 IID,直到遇到全0为止。
通过 IID.Name -> 定位到 DLL 名字。
通过 IID.OriginalFirstThunk 或者 FirstThunk -> 定位到IAT ( image_thunk_data32[] );
遍历指针目录,知道遇到NULL为止。
通过 thunk_data.AddressOfData -> 定位到一个 IMAGE_IMPORT_BY_NAME 的地址,再根据它寻址到真正的函数序号和函数名称。
为什么存在二级指针呢,这是很容易解释的。所以我们需要一个DLL目录,由于DLL名称的长度和函数个数不固定,所以向下扩展了一级,而每个函数的函数名称又是不固定的,所以又要向下扩展一级,这样要找到真正的函数名称必须经过这样两级定向。
因此这个二级索引的导入表就是这样的定位方式(每个数组都是一个高地址方向半开口的样子, C字符串也是这样的字符数组),如下图所示(注意每个数组的元素的size是固定的,但由于数组是半开口,所以数组本身属于size不固定):
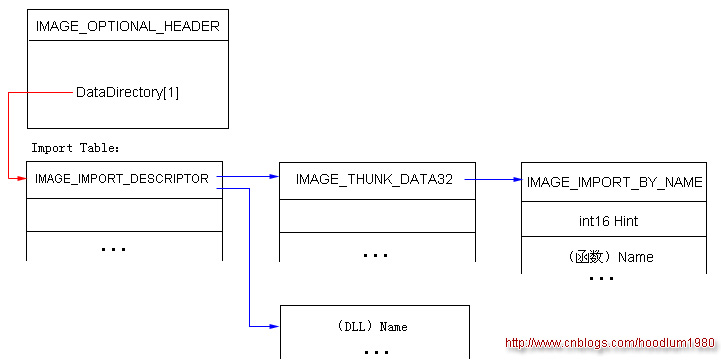
特点就是,每次遇到长度无法预测的成员,就用指针把它从元素中扩展出去(用一个指针指向它),这样我们就保证每个数组的元素都是固定的size,这样它才能成为线性表结构(满足用指针的加减或者[]操作符进行元素读取)。例如DLL的名称是可变长度的,因此它被扔到元素定义的外面去,在元素中保留为一个指针。每个DLL的函数目录也是可变长度的(函数个数是不确定的),因此它在元素中也是一个指针。而函数目录中函数信息又被扔出去,用指针指向它。
- PE文件导入表
- PE文件结构详解-PE导入表
- PE文件,导入表定位
- PE文件结构详解(四)PE导入表
- PE文件结构详解(四)PE导入表
- PE文件结构详解(四)PE导入表
- PE文件结构详解(四)PE导入表
- PE文件结构详解(四)PE导入表
- PE文件结构详解(四)PE导入表
- PE总结11--PE文件结构之 解析导入表
- PE文件结构详解(四)PE导入表
- PE文件结构详解(四)PE导入表
- PE文件结构详解(四)PE导入表
- PE文件导入表的代码注入
- 读取PE文件的导入表
- PE 文件格之导入导出表
- PE文件导入表的代码注入
- 读取PE文件的导入表
- B树与B+树
- What Is UTF-8 And Why Is It Important?
- strcpy 和 strncpy的区别
- StarWest 2010 - Day 0 - Travel
- MFC(Visual C++ 6.0)中使用文件流fstream的相关问题
- PE文件导入表
- 修正版本的磁盘监控.. 整合到一个脚本算了.方便
- Java中的数字问题
- el表达式和jstl标签
- 第二章(契约 双向操作)
- DBI接口与DPI接口与DSI接口
- SD卡家族
- resources在“Resources”参数中指定了多次。“Resources”参数不支持重复项。
- RFC1334——PPP Authentication Protocols中文版


