写了个幷查集的模板类...
来源:互联网 发布:德尔菲神谕 知乎 编辑:程序博客网 时间:2024/05/18 05:40
下面的概念介绍主要参考了:http://www.cnblogs.com/cherish_yimi/archive/2009/10/11/1580839.html,根据这个介绍,自己写了个稍微通用一点的模板,是否完全正确还有待验证:
l 并查集:(union-find sets)
一种简单的用途广泛的集合. 并查集是若干个不相交集合,能够实现较快的合并和判断元素所在集合的操作,应用很多,如其求无向图的连通分量个数等。最完美的应用当属:实现Kruskar算法求最小生成树。
l 并查集的精髓(即它的三种操作,结合实现代码模板进行理解):
1、Make_Set(x) 把每一个元素初始化为一个集合
初始化后每一个元素的父亲节点是它本身,每一个元素的祖先节点也是它本身(也可以根据情况而变)。
2、Find_Set(x) 查找一个元素所在的集合
查找一个元素所在的集合,其精髓是找到这个元素所在集合的祖先!这个才是并查集判断和合并的最终依据。
判断两个元素是否属于同一集合,只要看他们所在集合的祖先是否相同即可。
合并两个集合,也是使一个集合的祖先成为另一个集合的祖先,具体见示意图
3、Union(x,y) 合并x,y所在的两个集合
合并两个不相交集合操作很简单:
利用Find_Set找到其中两个集合的祖先,将一个集合的祖先指向另一个集合的祖先。如图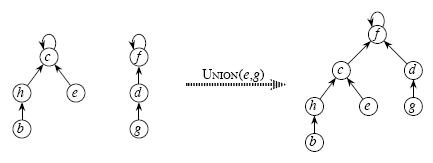
l 并查集的优化
1、Find_Set(x)时 路径压缩
寻找祖先时我们一般采用递归查找,但是当元素很多亦或是整棵树变为一条链时,每次Find_Set(x)都是O(n)的复杂度,有没有办法减小这个复杂度呢?
答案是肯定的,这就是路径压缩,即当我们经过"递推"找到祖先节点后,"回溯"的时候顺便将它的子孙节点都直接指向祖先,这样以后再次Find_Set(x)时复杂度就变成O(1)了,如下图所示;可见,路径压缩方便了以后的查找。
2、Union(x,y)时 按秩合并
即合并的时候将元素少的集合合并到元素多的集合中,这样合并之后树的高度会相对较小。
代码:
#include"iostream"
#include"vector"
using namespace std;
template<class T>
class Element
{
public:
T m_Value; //节点的值
Element* m_Father; //节点的父亲
int m_Degree; //该节点为集合的根时,它下面有多少层子节点
};
template<class T>
class UnionFindSet
{
public:
vector<Element<T>*> m_Data;
void AddElement(Element<T>* a);
void MakeSet(); //initial:let every element's ancestor equal to itself
Element<T>* FindSet(Element<T>* x); //Find x's ancestor
void Union(Element<T>* x,Element<T>* y); //Union x and y to one set
};
template<class T>
void UnionFindSet<T>::AddElement(Element<T>* a)
{
if(a!=NULL)
{
this->m_Data.push_back(a);
}
}
template<class T>
void UnionFindSet<T>::MakeSet()
{
int size = this->m_Data.size();
for (int i =0;i<size;++i)
{
Element<T>* p = this->m_Data[i];
p->m_Father = p; //on initial time,p's father is itself!
}
}
/**//* 查找x元素所在的集合,回溯时压缩路径*/
template<class T>
Element<T>* UnionFindSet<T>::FindSet(Element<T>* x)
{
if (x!=x->m_Father)
{
x->m_Father = FindSet(x->m_Father); //寻找并且压缩路径
}
return x->m_Father;
}
template<class T>
void UnionFindSet<T>::Union(Element<T>* x,Element<T>* y)
{
Element<T>* xAncestor = FindSet(x);
Element<T>* yAncestor = FindSet(y);
if (xAncestor == yAncestor)
{
return;
}
else
{
if (xAncestor->m_Degree > yAncestor->m_Degree)
{
yAncestor->m_Father = xAncestor;
}
else
{
if (xAncestor->m_Degree == yAncestor->m_Degree)
{
yAncestor->m_Degree ++;
}
xAncestor->m_Father = yAncestor;
}
}
}
int main(void)
{
int j;
UnionFindSet<int> ufs;
Element<int>* elem[10];
for (int i = 0;i<10; ++i)
{
elem[i] = new Element<int>;
elem[i]->m_Value = i;
ufs.AddElement(elem[i]);
}
ufs.MakeSet();
ufs.Union(elem[0],elem[1]);
ufs.Union(elem[1],elem[2]);
ufs.Union(elem[2],elem[3]);
ufs.Union(elem[0],elem[4]);
ufs.Union(elem[6],elem[5]);
ufs.Union(elem[9],elem[7]);
ufs.Union(elem[6],elem[8]);
for (j = 0;j<10;j++)
{
cout<<elem[j]->m_Father->m_Value<<endl;
}
return 0;
}
- 写了个幷查集的模板类...
- 蛙蛙推荐:写了个一个vbs类的模板
- 再读C++ Primer 写了个小例子——模板类的操作
- 写模板类的时候,目录突然出现了.gch文件~~~学习学习
- 自己写了一个可变参数的泛型模板
- 写了一个简单实用的PHP模板引擎
- 自己写的求最大值实现,用到了模板函数。
- 用模板写的堆栈类
- 自己写的链表模板类
- 写模板--Smarty类的编译功能仿写
- 写好自己的模板方法,以后要做的就是对于模板方法进行具体化了
- 一个简单的绿色模板 但值得学习~!!! (我写了很好的注释)
- 要辞职了,收集一些如何写辞职信的模板
- 自己写的一个模板队列(修改了2月3号新版本)
- 用ruby写了一个生成xpcom组件模板的小工具
- javascript模板技术 界面显示可以用另外的方法来写了
- 使用了模板页的内容页 写js函…
- 写了一个最简单的 js 模板引擎,直接贴代码
- 刚开的,博客功能都不全呢
- C#快捷键大全
- RPG游戏攻防公式设计探讨
- 论文阅读报告:Spyglass : Fast Scalable Metadata Search for Large-Scale Storage Systems
- C#语言中怎么使用ActiveX控件
- 写了个幷查集的模板类...
- java.net.bindexception: address already in use: jvm_bind:8080
- 正式转入NLP行业
- 声道
- NVelocity 介绍
- XML的增删改 其人 上篇文章 文章分页 值得一看
- 正则表达式
- 当前几个主要的Lucene中文分词器的比较
- Good develpmental prospect of rechargeable battery wholesale


