图的拉普拉斯矩阵学习-Laplacian Matrices of Graphs
来源:互联网 发布:时序数据库 influxdb 编辑:程序博客网 时间:2024/05/16 23:57
We all learn one way of solving linear equations when we first encounter linear
algebra: Gaussian Elimination. In this survey, I will tell the story of some remarkable
connections between algorithms, spectral graph theory, functional analysis
and numerical linear algebra that arise in the search for asymptotically faster algorithms.
I will only consider the problem of solving systems of linear equations
in the Laplacian matrices of graphs. This is a very special case, but it is also a
very interesting case. I begin by introducing the main characters in the story.
1. Laplacian Matrices and Graphs. We will consider weighted, undirected,
simple graphs G given by a triple (V,E,w), where V is a set of vertices, E
is a set of edges, and w is a weight function that assigns a positive weight to
every edge. The Laplacian matrix L of a graph is most naturally defined by
the quadratic form it induces. For a vector x ∈ IRV , the Laplacian quadratic
form of G is:
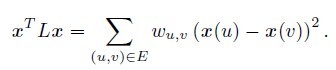
Thus, L provides a measure of the smoothness of x over the edges in G. The
more x jumps over an edge, the larger the quadratic form becomes.
The Laplacian L also has a simple description as a matrix. Define the
weighted degree of a vertex u by:
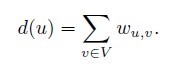
Define D to be the diagonal matrix whose diagonal contains d, and define
the weighted adjacency matrix of G by:
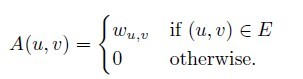
We have
L = D − A.
It is often convenient to consider the normalized Laplacian of a graph instead
of the Laplacian. It is given by D−1/2LD−1/2, and is more closely related to
the behavior of random walks.
Regression on Graphs. Imagine that you have been told the value of a
function f on a subset W of the vertices of G, and wish to estimate the
values of f at the remaining vertices. Of course, this is not possible unless
f respects the graph structure in some way. One reasonable assumption is
that the quadratic form in the Laplacian is small, in which case one may
estimate f by solving for the function f : V → IR minimizing f TLf subject
to f taking the given values on W (see [ZGL03]). Alternatively, one could
assume that the value of f at every vertex v is the weighted average of f at
the neighbors of v, with the weights being proportional to the edge weights.
In this case, one should minimize:
|D-1Lf|
subject to f taking the given values on W. These problems inspire many
uses of graph Laplacians in Machine Learning.

- 图的拉普拉斯矩阵学习-Laplacian Matrices of Graphs
- graph Laplacian 拉普拉斯矩阵
- 图的Laplacian矩阵
- opencv3_java 图形图像的拉普拉斯平滑Laplacian Laplacian
- GANs学习系列(7): 拉普拉斯金字塔生成式对抗网络Laplacian Pyramid of Adversarial Networks
- 基于Eigen库的离散拉普拉斯平滑(Discretized Laplacian Smoothing)的C++非稀疏矩阵实现
- matlab laplacian of gaussian(拉普拉斯高斯) 图像滤波
- 图的拉普拉斯矩阵(Graph Laplacians)
- Laplacian/拉普拉斯算子
- opencv入门学习之六:拉普拉斯Laplacian变换锐化图像
- D3D学习三:矩阵Matrices
- A Pair of Graphs(图的构造) HDU 2464
- Laplacian Eigenmaps 拉普拉斯特征映射
- Laplacian矩阵的半正定性
- 拉普拉斯矩阵
- 拉普拉斯矩阵
- 拉普拉斯矩阵
- 拉普拉斯矩阵
- 淘宝网店的建设!想开淘宝店的朋友欢迎找我!
- UBUNTU中如何修改root密码
- Spring读取数据连接属性文件properties(单个和多个)
- 什么是核心层?汇聚层?接入层?
- MySQL命令集锦
- 图的拉普拉斯矩阵学习-Laplacian Matrices of Graphs
- hkhgkh
- 项目管理学习:信息化知识
- 不重复随机数的产生问题
- 图书管理系统
- 它利用了通用GBIC技术
- Callback Function
- 按键精灵--VS挤房器
- 利用 net use建立网络连接


