html解析模型(dlmu2001)
来源:互联网 发布:淘宝纸盒飞机盒 编辑:程序博客网 时间:2024/04/28 01:35
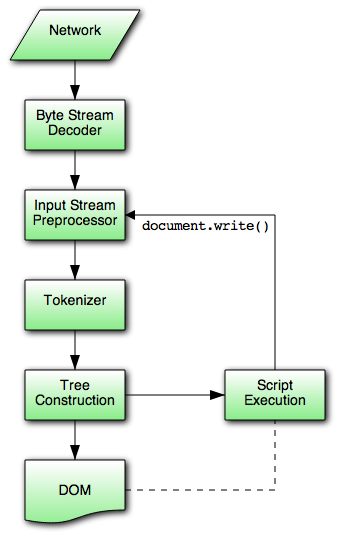
如上是html解析模型图,如图所示,html解析模型的输入是unicode字符流,经过tokenization和tree construction两个阶段,输出Document对象。
一般情况下,Tokenization阶段处理的数据来自网络,但它也可以来自于运行在用户代理上的脚本,比如,使用document.wrinte()这样的API。
Tokenizer和tree construction状态都只有一套,但是tree construction是可重入的,tree construction阶段在处理一个token的时候,tokenizer可能得以继续,导致在第一个token没有完成之前,其它的token被释放并处理。
…
<script>
Document.write(‘<p>’);
</script>
…
比如,如上的代码,tree construction阶段在处理”script”结束标签的时候,会被要求处理”p”起始标签。
- html解析模型(dlmu2001)
- WebKit中的html词法解析(dlmu2001)
- html解析模型
- RFC791中文翻译一(dlmu2001)
- RFC791中文翻译二(dlmu2001)
- RFC791中文翻译三(dlmu2001)
- RFC793中文翻译一(dlmu2001)
- RFC793中文翻译二(dlmu2001)
- RFC793中文翻译三(dlmu2001)
- 浏览器背景知识(dlmu2001)
- HTML 解析
- html 解析
- 解析HTML
- html 解析
- 解析HTML
- 解析 HTML
- html解析
- 解析html
- spring属性编辑器(PropertyEditorSupport)
- HTML5 WebSockets 基础使用教程
- Tomcat配置集锦
- CSS offsetLeft、clientHeight、scrollLeft、clientLeft(转)
- 单位给我出了个小难题
- html解析模型(dlmu2001)
- eclipse 安装 jetty
- 门禁的几点应用
- zoj 1019 Illusive chase
- VC 界面库收集
- 程序员:开始编程生涯的5个建议
- 路由器测试的性能测试
- 同样是人,不可能一天就能修炼成功!
- Yマット


