马尔可夫决策过程(三)
来源:互联网 发布:帝国cms整站字符替换 编辑:程序博客网 时间:2024/05/04 01:36
马尔可夫决策过程(三)
最近学习了MDP,查看一些资料,本文翻译了维基百科http://en.wikipedia.org/wiki/Markov_decision_process。有许多地方翻译的不好,有翻译错的地方请多多谅解!欢迎给我留下意见,我会尽快更改!
解决方法 假设我们知道状态转移函数 P 和奖励函数 R ,而且我们希望计算最大化期望折扣奖励的策略。 标准的算法族(the standard family of algorithms)来计算此类最佳策略需要两个数组,它们分别被包含实际值的值 V 和包含动作的策略 π 索引。在算法的结束,π 将包含此解决方案,V(s)将包含在状态s 下(平均起来)采取上面所说的解决方案所获得的回报折扣总和。 该算法具有下述的两种步骤,针对所有状态按照某种次序重复执行它们,直到没有进一步的变化发生为止。它们是 它们的顺序取决于该算法的变体;针对所有状态一个步骤也许就可以一次完成,或者一个状态接着一个状态,往往针对某些状态比其他一些要更多。只要没有状态是永久排除的此两个步骤之外的,那么该算法将最终找到正确的解答。 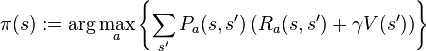
![]()
- 马尔可夫决策过程(三)
- 马尔可夫决策过程(一)
- 马尔可夫决策过程(二)
- 马尔可夫决策过程(四)
- 马尔可夫决策过程(五)
- 马尔可夫决策过程
- 马尔可夫决策过程
- 马尔可夫决策过程
- 马尔可夫决策过程MDP
- 马尔可夫决策过程MDP
- 马尔可夫决策过程
- 马尔可夫决策过程MDP
- 马尔可夫决策过程(MDP)
- 马尔科夫决策过程(MDP)
- 贝叶斯决策理论(三)
- 增强学习(二)----- 马尔可夫决策过程MDP
- 增强学习(二)----- 马尔可夫决策过程MDP
- 学习小记 之 马尔可夫决策过程(Markov Decision Processes)
- linux开机自动运行命令
- poj1860——Currency Exchange
- 使用当前目录作为编译目标/可执行文件名称
- 各种数据类型的转换
- 马尔可夫决策过程(二)
- 马尔可夫决策过程(三)
- ESXvswith虚拟交换机vlan模式
- 马尔可夫决策过程(四)
- PreTranslateMessage作用和使用方法
- 马尔可夫决策过程(五)
- php 中的数组(笔记)
- 基于IAP和Keil MDK的远程升级设计
- 程序员的编程经验分享
- ECSHOP 模板系统文件结构


