java读写应用(为了舒适的阅读小说,将一个2Mtxt文档中的小说的每个章节抽取出来分别放在html文件中)
来源:互联网 发布:淘宝详情分割线素材 编辑:程序博客网 时间:2024/04/26 18:43
最近喜欢上了看小说,到网上下载了一部《神墓》来看,但是其全部内容都放在一个文本文档
中,有2M大,仅仅打开这个文本文档就要花费不短的时间,因此我实现了下面的小程序,其功能
是:
将这部小说的内容按照章节抽出出来,分别放在一个html文件中,这样一来我就可以将背景颜色
调为柔和型的,不伤眼。
如:
第二部 第六章 终将一战 这章节的内容将被放置在 "第二部 第六章 终将一战.html"的html文件
中,同时这个页面生成“上一页”,“目录”,“下一页”的超链接,最后将为所有的章节生成一个
目录。
当然下面的小程序有一些不足,但是我相信在大家的帮助下,它会越来越完善的。
package com.yj.generate;
/*
* 用来将只放在一个文件中的小说切隔成
* 一个章节的html页面,其中每个页面还包括上一页,下一页,目录 的超链接
* 同时还生成一个目录文件contents.html
*====================
*注意源码的编码是:utf-8
*文件读取的来源文件的编码也需是utf-8
*===================
*这里的神墓的切隔的原理是:
*根据第一个章节的标题都包含:"章 "
*
*/
import java.io.*;
import java.util.ArrayList;
import java.util.Scanner;
public class GeneraeHtml {
private ArrayList<String> fileNames;
public GeneraeHtml()
{
fileNames=new ArrayList<String>();
}
public void generateHtmlByFile(File file)throws Exception
{
generate(file);
generateContent();
}
//Create all chapters's html file
private void generate(File file)throws Exception
{
boolean isFirstTitle=true;
Scanner sca=new Scanner(file);
String currentContent="";
String currentLineStr="";
String currentPageFileName="";
String nextPageFileName="";
int currentPageIndex=-1;
sca.useDelimiter("/n");
while(sca.hasNext())
{
currentLineStr=sca.next();
if(currentLineStr.indexOf("章 ")!=-1)
{
if(!isFirstTitle)
{
System.out.println("Current output title:"+currentPageFileName);
nextPageFileName=(currentPageIndex+1)+currentLineStr.trim()+".html";
fileNames.add(nextPageFileName);
writeContent(currentContent,currentPageFileName,currentPageIndex);
currentPageFileName=nextPageFileName;
currentContent="";
}else
{
currentPageFileName=(currentPageIndex+1)+currentLineStr.trim()+".html";
fileNames.add(currentPageFileName);
isFirstTitle=false;
}
currentPageIndex++;
}
currentContent+=currentLineStr+"</br>";
}
sca.close();
}
//It will write the current chapter into a html file
private void writeContent(String bodyContent,String currentFileName,int currentPageIndex)throws Exception
{
int previousPageIndex=0;
int nextPageIndex=currentPageIndex+1;
if(currentPageIndex!=0)
{
previousPageIndex=currentPageIndex-1;
}
String pageContent="<html>/n<head>/n"
+"<meta http-equiv='content-type' content='text/html;charset=utf-8'>/n"
+"</head>/n<body bgcolor='#e6f3ff'>/n"
+bodyContent
+"</br>"
+"<table align='center'>"
+"<tr>"
+"<td><a href='./"+fileNames.get(previousPageIndex)+"'>上一页</a></td>"
+"<td><a href='./contents.html'>目录</a></td>"
+"<td><a href='./"+fileNames.get(nextPageIndex)+"'>下一页</a></td>"
+"</tr>"
+"</table>"
+"</body>/n</html>";
String filePath="神墓/"+currentFileName;
PrintWriter out=new PrintWriter(new BufferedWriter(new FileWriter(filePath)));
out.print(pageContent);
out.flush();
out.close();
}
//Create a html file contain chapter's reference.
private void generateContent()throws Exception
{
String pageContent="<html>/n<head>/n"
+"<meta http-equiv='content-type' content='text/html;charset=utf-8'>/n"
+"</head>/n<body bgcolor='#e6f3ff'>/n"
+"<table align='center' width='80%' border=1>"
+"<tr align='center'>";
for(int i=0;i<fileNames.size();i++)
{
String item=fileNames.get(i);
pageContent+="<td width=33% color='green'><a href='./"+item+"'>"+item+"</a></td>";
if((i+1)%3==0)
{
pageContent+="</tr>/n<tr align='center'>";
}
}
pageContent+="</table>/n</body>/n</html>";
PrintWriter out=new PrintWriter(new BufferedWriter(new FileWriter("神墓/contents.html")));
out.print(pageContent);
out.flush();
out.close();
}
public static void main(String[] args) {
GeneraeHtml generaeHtml=new GeneraeHtml();
try
{
File file=new File("G:/神墓.TXT");
generaeHtml.generateHtmlByFile(file);
}catch(Exception e)
{
e.printStackTrace();
}
}
}
对应的流程图:

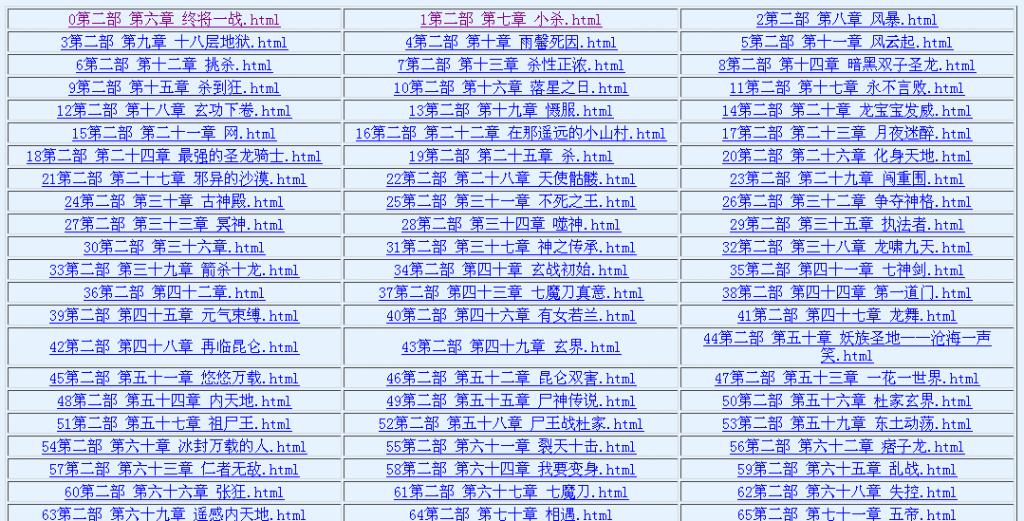
全部抽取成功后的部分html文件:
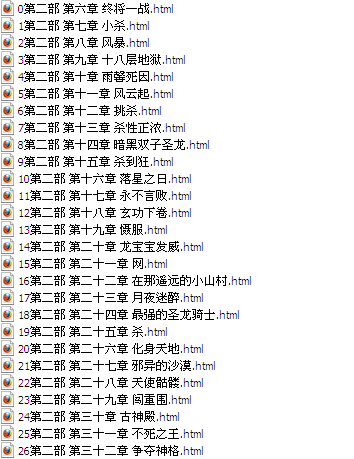
这是处理前的一个章节:

一个html文档显示一个章节:

这是生成的目录:

- java读写应用(为了舒适的阅读小说,将一个2Mtxt文档中的小说的每个章节抽取出来分别放在html文件中)
- 将任务4的解决用一个项目多个文件的方式实现,其中两个类的声明放在一个.h文件中,每个类的成员函数分别放一个文件,main()函数用一个文件。
- c++将一个文件夹下的所有文件读取出来放在一个文件中
- TXT阅读工具(为了解决广大网友的内燃之极,特做了一个专看H小说的工具)
- 小说章节解析 language-Java
- java的小说展示,下载在查看所有(文件路径找不到,可以修改)
- 将一个5*5的矩阵中最大的元素放在中心,4个角分别放4个最小的元素(对比两个程序)
- 将一个5*5 矩阵中最大的放在中间,四个角分别放最小的数据,顺序分别是左右上下,通过函数完成。
- 基于lucene的案例开发:纵横小说章节列表采集
- 读书的作用--引用《儒道至圣》小说章节
- 阅读小说
- 小说阅读
- java之上传文件的细节(都可以在源码体现,抽取出来讲呗)
- 将一个5*5的矩阵中最大的元素放在中心,4个角分别放在4个最小的元素
- (小说)疯狂的程序员
- 怎么让一个html文件在另一个html文件中适当的位置直接显示出来
- C++第六周任务5:解决用一个项目多个文件的方式实现,其中两个类的声明放在一个.h文件中,每个类的成员函数分别放一个文件,main()函数用一个文件。体会这样安排的优点。
- 将一个5*5的矩阵中最大的元素放在中心,4个角分别放4个最小的元素
- 重构,走出重构误区
- CV_IMAGE_ELEM参数赋值时注意的问题
- 【转】protel四层板及内电层分割入门
- 让Vim打印到纸上时显示行号
- 启动NFS
- java读写应用(为了舒适的阅读小说,将一个2Mtxt文档中的小说的每个章节抽取出来分别放在html文件中)
- 基于ASP.NET4.0、ExtJs技术构建酒店管理系统(送源码)
- Plugin 'InnoDB' init function returned error
- 反汇编代码分析--函数调用
- Struts1简单登陆详解
- POJ2181强连通分量
- ie的js测试接口
- 资源共享
- J2EE标准(转)


