use_concat导致not in时临时表不动态采样进而导致的性能问题
来源:互联网 发布:知牛财经做主播赚钱吗 编辑:程序博客网 时间:2024/04/29 16:52
数据库版本:10.2.0.4
一个系统上cpu使用偏高,awr报表表现为逻辑读偏高和大量的hash latch争用,最后得到是因为一些类似的sql语句引发的,这个系统里的sql是拼装起来的,没有使用绑定变量(当然这里有没有使用绑定变量不是引发性能问题的根源,这里就不说了),所以sql并不完全相同,但大致形式是一样的,我测定了一下一个捕捉到的sql语句,为了标识到底是哪里消耗了过多的逻辑io,我在执行sql语句前,在会话中设置statistics_level=all,然后使用SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(null,null,'ALL IOSTATS LAST'));查看真实的执行计划和执行时的统计信息如下:
只保留必要的信息之后,执行计划和统计信息是这样的:(执行计划A)
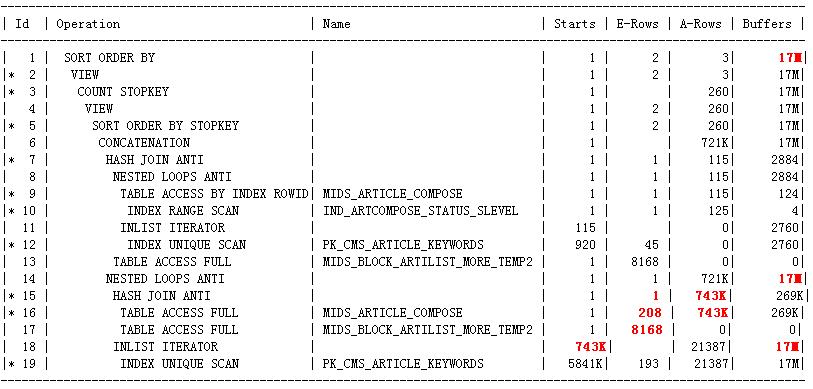
这里给出的执行计划和awrsqrpt.sql生成的执行计划是完全一样的.
从执行统计信息可以看到,这里的逻辑读高达1700W多,本质上是因为18,19步的高逻辑IO导致的,而这里逻辑IO这么高是因为作为nl_aj的内层循环,这里执行的次数太多了:74.3W次,为什么这么高代价的执行计划还要被选择上,是因为优化器估算的时候,认为nl_aj的内层循环只会执行一次,也就是说优化器估算步骤14执行的nl_aj的驱动结果集(也就是步骤15返回的结果集)只有1行,但实际上它却返回了74.3W行导致的.所以这里需要调查步骤15为什么实际返回了74.3W行,但却估算只返回了1行?实际上步骤16,17的card估算都存在问题.
把执行计划中步骤16的filter谓词单独的应用于MIDS_ARTICLE_COMPOSE后,它估算返回335K,和实际执行时返回743K是一个数量级上的了,远不像现在这样同样的filter子句却只估算返回208行这样偏离实际情况,这个需要调查一下.还有步骤17中MIDS_BLOCK_ARTILIST_MORE_TEMP2这个temporary table上没有收集优化器统计信息,但在optimizer_dynamic_sampling=2时应该使用动态采样发现实际上它是一个空表,所以这里的card应该是1的呀,为什么却是临时表的默认的card 8168呢,所以这里应该是没有使用动态采样的,可执行计划的note部分明明提示:- dynamic sampling used for this statement的呀,这里为什么没有使用动态采样也需要调查一下. 200多行的数据不在8000多行的数据里,得出1行的结果集,似乎是合理的,但也要调查一下.
于是做了一个10053事件.
先说步骤16只估算返回208行数据的问题:
Table: MIDS_ARTICLE_COMPOSE Alias: A
Card: Original: 2626 Rounded: 208 Computed: 207.58 Non Adjusted: 207.58
从表统计信息部分看,这个表的统计信息没有问题,是200多W行数据,可到了这里,原始估算却只有2626行数据了,这应该是导致最终这里只估算返回208行数据的根源.可为什么是这个2626行数据呢?!似乎又和这里的rownum<=n这个有关.在这个card内容的上面就是SINGLE TABLE ACCESS PATH (First K Rows).
sql语句最后部分是这样的:
order by a.DISPLAY_TIME desc nulls last) a
where rownum <= 260)
where r >= 258
order by r;
(这里不去说为什么这里使用了nulls last)
我这里修改where rownum<=n 这里的n值,步骤16估算的card是随这里n值的增大或者是减小而同步变化的.
我在最外层的select中添加了/*+ all_rows*/的提示后,执行计划变了(sql中有两部分的or,一个or部分是字段A上的一个or,另一个or部分是字段B上的两个or,执行计划由原来的一个or的use_concat变成了两个or的use_concat)(在里面任何一层的select部分添加/*+ all_rows*/这样的提示都不改变现有的执行计划的),但是现在的执行计划B和原来的执行计划A还是有相似之处的,只保留必要的信息之后,执行计划和统计信息是这样的:(执行计划B)
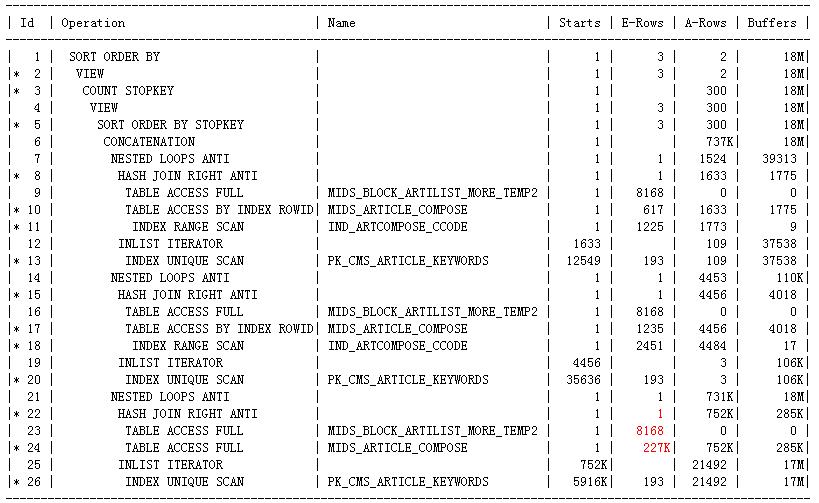
我这里再改变rownum<=n 这里的n值,无论改变程度有多大,步骤10,17,24估算的card都不再改变了,而且我这里select * from MIDS_ARTICLE_COMPOSE a where 只单独应用步骤24的filter谓词之后,估算返回的card和这里估算的card是完全相同的,远不像执行计划A中同样的应用却是完全不同的.这说明执行计划A中rownum<=n确实在一定程度上触发了first_rows(n)这样的优化器模式.但这里有两个疑问:1.除了rownum<n 这样的谓词之外,还需要什么样的条件才会触发first_rows(n)这样的优化器模式,因为你会发现并不是查询中含有rownum<=n这样的谓词就一定会触发first_rows(n)优化器模式的,我想要在自己的模拟测试中再现这一点,可就是再现不了,这说明除了rownum<n这样的谓词之外应该还需要其它的一些必要条件才会触发first_rows(n),但这样的触发条件是什么呢?这样的触发条件是否总是合适的?就像我下面要说的一样,如果它是在一定的条件下触发的,那它可能就不是完全基于代价的,那么就可能选择糟糕的执行计划,就像这里一样,虽然这里实际是分页取某个页面的数据,但实际上它必须得到整个候选结果集之后才可以取这个页面的数据的,所以它应该是all_rows,而不应该是first_rows(n)的 2.first_rows(n)(当然也包括all_rows)这些优化器模式是什么阶段确定下来的,它们是否是完全基于代价的?我的意思是说:明显你可以看到first_rows(n)下,计算出的card会很小,相应的执行计划的cost也会很小,这样all_rows下的执行计划和这些first_rows(n)下的执行计划明显是不具有可比性的,因为all_rows下的执行计划很可能cost要比它高,注定是要被淘汰掉的.这样它们就不是完全基于代价的了,那first_rows(n)还是all_rows这样的优化器模式是什么时候确定下来的呢?如果说first_rows(n)得到一批执行计划,all_rows下得到一批执行计划,然后选择cost最低的,可就像我前面说的那样,这样的情况下,first_rows(n)的cost显然是要比同等情况下的all_rows的cost要低,几乎是注定要被选择的,所以我感觉似乎是在硬分析一开始的某个阶段在比较执行计划的cost之前就确定了要使用某种优化器模式的,然后才开始比较各个可行的执行计划的cost的.那它就不是完全基于代价的了,就是某些规则下使用first_row_n,某些规则下使用all_rows了,在这样的基调下才去比较各个执行计划了,是这样吗?(虽说first_row_n下的执行计划和all_rows下的执行计划的可选集合是完全一样的,不同模式下的执行计划不具有可比性了,但同一模式下的执行计划还是具有可比性的嘛)还有就是first_rows(n)这里的n是如何确定的呢? 不知道我这里表达清楚没有,其实这种想法在以前的博文中记录rownum引发的类似的问题时就产生这样的想法了.
再说连接的结果集估算为1的情况:
从执行计划B中步骤22,23,24比对执行计划A,你会感觉其实执行计划A中因为rownum的问题导致步骤16估算只返回208行还不是步骤15估算只返回1行数据的根源,因为你发现执行计划B中步骤24估算返回22.7W行数据了,可最终步骤22还是估算返回1行数据,实际上它返回了75.2W行数据.如果说208行数据不在8168行数据里估算返回1行数据还算正常的话,那么22.7W行数据(关键是这里的id是有主键约束的)不在8168行数据里仍然估算返回1行数据,总觉得就有点儿说不过去了吧.所以这里还是需要调查一下了,这里的相应的sql部分是这样的:
from mids_article_compose a where a.id not in (select id from mids_block_artilist_more_temp2 t)
其中id是表mids_article_compose的主键,mids_block_artilist_more_temp2中的id没有主键约束(其实也是不重复的),但要求是非空的.
执行计划A的步骤15只估算返回1行数据,从10053文件来看是这样得来的:
Anti Join Card: 0.00 = outer (207.58) * (1 - sel (1)) --为什么是这样一个结果呢?sel(1)是如何得来的呢?这里当然没有给出sel(1)是如何得来的
Join Card - Rounded: 1 Computed: 0.00
Best:: JoinMethod: HashAnti
Cost: 79.16 Degree: 1 Resp: 79.16 Card: 0.00 Bytes: 840
同时需要引起注意的一点是:
>>> adjusting AJ/SJ sel based on min/max ranges: jsel=min(0.93269, 0.23308)
Anti Join Card: 159.20 = outer (207.58) * (1 - sel (0.23308)) --这个为什么被抛弃了呀?
Best:: JoinMethod: HashAnti
Cost: 69.99 Degree: 1 Resp: 69.99 Card: 159.20 Bytes: 842 --为什么被抛弃了呀?显然不是因为cost,因为它的cost更小
执行计划B的步骤22只估算返回1行数据,从10053文件来看是这样得来的:
Anti Join Card: 0.00 = outer (227642.69) * (1 - sel (1))
Join Card - Rounded: 1 Computed: 0.00
Best:: JoinMethod: HashAnti
Cost: 49905.19 Degree: 1 Resp: 49905.19 Card: 0.00 Bytes: 881
同样需要引起注意的一点是:
Anti Join Card: 227448.68 = outer (227642.69) * (1 - sel (8.5225e-04))
Join Card - Rounded: 227449 Computed: 227448.68 --这个为什么被抛弃了呀?
Best:: JoinMethod: HashAnti
Cost: 49895.99 Degree: 1 Resp: 49895.99 Card: 227448.68 Bytes: 883 --这个为什么被抛弃了呀?显然不是因为cost,因为它的cost更低的
(这里有个无关紧要的细节是explain plan和10053 trace文件在一些数字表现形式上的不一致,比如说执行计划B中步骤24实际估算返回227643行数据,explain plan时直接表述为227K,而10053 trace文件的执行计划中却显示为222K,实际上是一回事儿,因为round(227643/1024,2)=222.31K)
仿照这里的情况,构建了一个测试案例:
这里optimizer_dynamic_sampling是默认的2
create table zsj_objs as
select 100000 id,owner,object_name,object_type,created,last_ddl_time,status
from dba_objects
where object_id is not null and rownum<=50000;
insert /*+ append*/into zsj_objs select * from zsj_objs;
commit;
insert /*+ append*/into zsj_objs select * from zsj_objs;
commit;
insert /*+ append*/into zsj_objs select * from zsj_objs where rownum<=20000;
commit;
update zsj_objs set id=rownum;
commit;
alter table zsj_objs add constraint pk_zsj_objs primary key(id);
--22W行数据,id是主键
exec dbms_stats.gather_table_stats(user,'ZSJ_OBJS',estimate_percent => 100,method_opt => 'FOR ALL COLUMNS SIZE 1');
create global temporary table zsj_temp
(
id number not null,
owner varchar2(30),
OBJECT_NAME VARCHAR2(128),
OBJECT_TYPE VARCHAR2(19),
CREATED DATE,
LAST_DDL_TIME DATE,
STATUS VARCHAR2(7)
)
on commit preserve rows;
语句1:
explain plan for select * from zsj_objs where id not in(select id from zsj_temp t);
---------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 219K| 16M| 380 (2)| 00:00:05 |
|* 1 | HASH JOIN RIGHT ANTI| | 219K| 16M| 380 (2)| 00:00:05 |
| 2 | TABLE ACCESS FULL | ZSJ_TEMP | 1 | 13 | 2 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL | ZSJ_OBJS | 220K| 13M| 376 (2)| 00:00:05 |
---------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("ID"="ID")
Note
-----
- dynamic sampling used for this statement
--注意这里的219K,实际上就是219999,下同
--这里使用了动态采样,得到了正确的估算card=22W
语句2:
explain plan for select * from zsj_objs where id not in(select /*+ cardinality(t 8168) */id from zsj_temp t);
---------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 219K| 16M| 380 (2)| 00:00:05 |
|* 1 | HASH JOIN RIGHT ANTI| | 219K| 16M| 380 (2)| 00:00:05 |
| 2 | TABLE ACCESS FULL | ZSJ_TEMP | 8168 | 103K| 2 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL | ZSJ_OBJS | 220K| 13M| 376 (2)| 00:00:05 |
---------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("ID"="ID")
Note
-----
- dynamic sampling used for this statement
--这里也使用了动态采样,虽然我这里使用cardinality提示子查询返回8168行数据,和不使用动态采样的默认值是一样的,可整体的card估算仍然是219K,和语句1的执行计划估算是一样的,和语句3的执行计划的估算是不一样的,使用提示opt_estimate(table,t,rows=8168)替换cardinality提示一样的结果的.所以这里可能给人的感觉这里的动态采样似乎不是针对zsj_temp这个表的,而是针对整个查询结果集的,所以才得到了正确的估算.其实不是这样的,下面再说这个问题.
语句3:
explain plan for select * from zsj_objs where id not in(select /*+ dynamic_sampling(t 0) */id from zsj_temp t);
---------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 78 | 397 (2)| 00:00:05 |
|* 1 | HASH JOIN RIGHT ANTI| | 1 | 78 | 397 (2)| 00:00:05 |
| 2 | TABLE ACCESS FULL | ZSJ_TEMP | 8168 | 103K| 19 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL | ZSJ_OBJS | 220K| 13M| 376 (2)| 00:00:05 |
---------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("ID"="ID")
--这里通过提示强制不使用动态采样,所以这里的临时表使用了默认的8168,106184(103k),最终的card估算也变成了1.
--当然这里zsj_temp的id是不是主键对于最终的card估算没有任何的影响(影响就是个别的执行计划中zsj_temp的全表扫描变成了主键对应索引的索引快速全扫描而已)
针对这3个语句生成一个10053事件文件,发现:
语句1使用了动态采样,估算返回219999,是这样得到的: 219999.00 = outer (220000.00) * (1 - sel (4.5455e-06))
语句2也使用了动态采样,10053文件是这样表述的:
** Using dynamic sampling card. : 0
** Dynamic sampling updated table card.
Table: ZSJ_TEMP Alias: T
Card: Original: 0 >> Single Tab Card adjusted from: 0.00 to: 8168.00
Rounded: 8168 Computed: 8168.00 Non Adjusted: 0.00
使用了动态采样,发现返回为0,本来是要表现为1的,可因为我这里的cardinality提示,所以更改为了8168
可最终估算呢?
Anti Join Card: 219999.00 = outer (220000.00) * (1 - sel (4.5455e-06))
Join Card - Rounded: 219999 Computed: 219999.00
--最终结果集的card的估算的计算表达式和语句1是完全一样的,cardinality提示对这里的card估算没有产生任何的影响
实际上你把提示改为cardinality(t 8168000000)或者是cardinality(t 1),cardinality(t 0),最终还是估算返回219999行记录,这个不会因为cardinality提示而有任何的改变的.
语句3强制不使用动态采样,确实没有使用动态采样,而使用了对于临时表的一系列默认值
Table Stats::
Table: ZSJ_TEMP Alias: T (NOT ANALYZED)
#Rows: 8168 #Blks: 100 AvgRowLen: 100.00
Column (#1): ID(NUMBER) NO STATISTICS (using defaults)
AvgLen: 13.00 NDV: 255 Nulls: 0 Density: 0.0039177
** Not using dynamic sampling since sampling disabled or level equals 0.
Table: ZSJ_TEMP Alias: T
Card: Original: 8168 Rounded: 8168 Computed: 8168.00 Non Adjusted: 8168.00
最终结果集的card如何估算出1的呢?
Anti Join Card: 0.00 = outer (220000.00) * (1 - sel (1))
Join Card - Rounded: 1 Computed: 0.00
我发现这里只要not in后部的表(和这个表是不是临时表没有关系)上没有收集优化器统计信息,且不使用动态采样,似乎not in估算结果集就是0行,也就是说card=1.但使用动态采样时可以得到大致正确的估算值(我这里都是使用默认的optimizer_dynamic_sampling=2的).当然这只是针对我观察的结果而言.从后面的实验,我们可以知道not in后半部表是普通表,没有收集统计信息,不使用动态采样的话,not in结果集的估算并不总是0的,但not in后半部是临时表,没有收集统计信息,不使用动态采样的话,not in结果集估算似乎就是0行,也就是说card=1.
create table zsj_objs2 as select * from zsj_objs where id<=10000;
alter table zsj_objs2 modify(id not null);
select count(1) cnt from zsj_objs2;
CNT
----------
10000
--注意这里并没有收集zsj_objs2上的优化器统计信息
explain plan for select * from zsj_objs where id not in ( select id from zsj_objs2 t);
----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 210K| 15M| 396 (2)| 00:00:05 |
|* 1 | HASH JOIN RIGHT ANTI| | 210K| 15M| 396 (2)| 00:00:05 |
| 2 | TABLE ACCESS FULL | ZSJ_OBJS2 | 9926 | 126K| 18 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL | ZSJ_OBJS | 220K| 13M| 376 (2)| 00:00:05 |
----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("ID"="ID")
Note
-----
- dynamic sampling used for this statement
使用了动态采样,这里估算返回21W行数据,是准确的
explain plan for select * from zsj_objs where id not in ( select /*+ dynamic_sampling(t 0)*/id from zsj_objs2 t);
----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 78 | 396 (2)| 00:00:05 |
|* 1 | HASH JOIN RIGHT ANTI| | 1 | 78 | 396 (2)| 00:00:05 |
| 2 | TABLE ACCESS FULL | ZSJ_OBJS2 | 7597 | 98761 | 18 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL | ZSJ_OBJS | 220K| 13M| 376 (2)| 00:00:05 |
----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("ID"="ID")
禁止使用动态采样,得到了card=1的结果,实际上这里1可能就是0.
对这个禁止使用动态采样的sql语句做了一个10053事件,发现同样的结果:
Anti Join Card: 0.00 = outer (220000.00) * (1 - sel (1))
Join Card - Rounded: 1 Computed: 0.00
而且这里也与not in后部的表的实际大小没有什么关系:
create table zsj_objs3 as select * from zsj_objs where rownum<=10;
alter table zsj_objs3 modify(id not null);
explain plan for select * from zsj_objs where id not in(select /*+ dynamic_sampling(t 0)*/id from zsj_objs3 t);
----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 78 | 380 (2)| 00:00:05 |
|* 1 | HASH JOIN RIGHT ANTI| | 1 | 78 | 380 (2)| 00:00:05 |
| 2 | TABLE ACCESS FULL | ZSJ_OBJS3 | 327 | 4251 | 2 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL | ZSJ_OBJS | 220K| 13M| 376 (2)| 00:00:05 |
----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("ID"="ID")
10053文件中还是:
Anti Join Card: 0.00 = outer (220000.00) * (1 - sel (1))
Join Card - Rounded: 1 Computed: 0.00
表的实际大小影响的只是这个表的card所使用的默认值(估计这个默认值是根据段头记录的信息计算后得到的),根本就不影响not in的结果集的card估算的计算公式的,总是0.
好,我们可以认为我们已经搞明白了为什么not in结果集估算为1(0),进而得到了一个糟糕的执行计划,那就是因为not in后部的表没有收集优化器统计信息,并且没有使用动态采样造成的(虽然说我们还是没有搞明白这里的sel(1)是如何得到的吧,但我们没有收集统计信息,也没有使用动态采样,所以它使用了默认的sel(1),这个也是可以理解的).所以我们需要调查一下这里对临时表为什么没有使用动态采样:
我们在执行计划A,执行计划B的10053文件中都看到了:
Optimizer environment:
optimizer_dynamic_sampling=2
执行计划的Content of other_xml column:
dynamic_sampling: yes
似乎来说,使用动态采样是确信无疑的,在它们的10053文件的开始部分确实看到了:
Table Stats::
Table: MIDS_BLOCK_ARTILIST_MORE_TEMP2 Alias: T (NOT ANALYZED)
#Rows: 8168 #Blks: 100 AvgRowLen: 100.00
Column (#1): ID(NUMBER) NO STATISTICS (using defaults)
AvgLen: 13.00 NDV: 255 Nulls: 0 Density: 0.0039177
***************************************
SINGLE TABLE ACCESS PATH
-----------------------------------------
BEGIN Single Table Cardinality Estimation
-----------------------------------------
*** 2010-12-03 20:18:20.334
** Performing dynamic sampling initial checks. **
** Dynamic sampling initial checks returning TRUE (level = 2).
** Dynamic sampling updated table stats.: blocks=0
** Using dynamic sampling: block count = 0.
** Using dynamic sampling card. : 0
** Dynamic sampling updated table card.
Table: MIDS_BLOCK_ARTILIST_MORE_TEMP2 Alias: T
Card: Original: 0 Rounded: 1 Computed: 0.00 Non Adjusted: 0.00
-----------------------------------------
END Single Table Cardinality Estimation
-----------------------------------------
Access Path: TableScan
Cost: 2.00 Resp: 2.00 Degree: 0
Cost_io: 2.00 Cost_cpu: 0
Resp_io: 2.00 Resp_cpu: 0
Best:: AccessPath: TableScan
Cost: 2.00 Degree: 1 Resp: 2.00 Card: 0.00 Bytes: 0
***************************************
明显使用了动态采样,没有使用默认值.并没有出现下面的文字:
** Not using dynamic sampling for single table sel. or cardinality.
说不使用动态采样信息了,并没有出现这样的文字。到这里看确实是采用了动态采样的.
可从之后的某个地方开始,就很突兀的变成下面这样了,没有任何的说明:
***********************
Table Stats::
Table: MIDS_BLOCK_ARTILIST_MORE_TEMP2 Alias: T (NOT ANALYZED)
#Rows: 8168 #Blks: 100 AvgRowLen: 100.00
Column (#1): ID(NUMBER) NO STATISTICS (using defaults)
AvgLen: 13.00 NDV: 255 Nulls: 0 Density: 0.0039177
***************************************
SINGLE TABLE ACCESS PATH
-----------------------------------------
BEGIN Single Table Cardinality Estimation
-----------------------------------------
Table: MIDS_BLOCK_ARTILIST_MORE_TEMP2 Alias: T
Card: Original: 8168 Rounded: 8168 Computed: 8168.00 Non Adjusted: 8168.00
-----------------------------------------
END Single Table Cardinality Estimation
-----------------------------------------
Access Path: TableScan
Cost: 19.13 Resp: 19.13 Degree: 0
Cost_io: 19.00 Cost_cpu: 1937344
Resp_io: 19.00 Resp_cpu: 1937344
Best:: AccessPath: TableScan
Cost: 19.13 Degree: 1 Resp: 19.13 Card: 8168.00 Bytes: 0
***************************************
很突兀的开始使用默认值了,不再使用动态采样信息了.两个10053文件里都是这样的.
我在将原来的sql语句尽量的精简,反复的实验之后,似乎发现了些问题,这似乎是和use_concat特性相关的一个问题:

--虽说这里也出现了动态采样的note,但从card估算为8168,我们还是可以认定这里没有使用动态采样,所以use_concat的每一部分都估算返回1行数据,特别要注意的是步骤12估算返回了45W行数据,可步骤10还是估算返回1行数据(其实是0行数据).这个use_concat也是在拥有其它谓词的情况下,执行计划A,B的默认选择.
我通过提示no_expand强制不使用use_concat特性,这里确实是使用了动态采样,所以临时表的card估算为1。最终结果集的card估算为80W(这里的card估算是准确的,实际执行返回83.7W行数据).完全相同的sql语句,只不过选择了不同的执行计划(通过使用不同的提示达到这个目的),结果card的估算是天壤之别.这个no_expand的执行计划也是这个sql语句的默认执行计划.
我在这两个sql语句中实际注释掉的部分其实是使用use_concat时要作为nl_aj的内表要循环执行的部分(因为它估算nl_aj的驱动结果集不返回数据的,其实根本就不是这样的),这是真正消耗资源的执行部分.
我们可以看到同样的sql语句,使用use_concat特性时,对临时表不使用动态采样,每个部分都估算不返回数据行(card表现为1),和实际情况根本不符;不使用use_concat特性时,对临时表使用动态采样,得到了一个符合实际情况的card估算值.
这个也是可以通过实验模拟得到的:
我们在上面22W行数据的zsj_objs表的基础上继续实验,原来执行了exec dbms_stats.gather_table_stats(user,'ZSJ_OBJS',estimate_percent => 100,method_opt => 'FOR ALL COLUMNS SIZE 1');id为主键,继续实验:
create index ind1_zsj_objs on zsj_objs(owner);
create index ind2_zsj_objs on zsj_objs(object_type);
exec dbms_stats.gather_table_stats(user,'ZSJ_OBJS',estimate_percent => 100,method_opt => 'FOR COLUMNS SIZE 254 owner,object_type',no_invalidate=>false);
owner,object_type上的不同值个数都少于254,这样我就可以得到这两个列上的频度直方图,也就可以得到它们的准确数据行数了.
对于zsj_objs2,zsj_objs3这两个普通表,使用
EXEC DBMS_STATS.delete_table_stats(USER,'ZSJ_OBJS2',cascade_columns => TRUE,cascade_indexes => TRUE,no_invalidate => FALSE);
EXEC DBMS_STATS.delete_table_stats(USER,'ZSJ_OBJS3',cascade_columns => TRUE,cascade_indexes => TRUE,no_invalidate => FALSE);
删除gather_stats_job 22点收集的优化器统计信息.它们就也变成没有收集统计信息的了.
将上面语句中的zsj_temp换成这里的zsj_objs2,zsj_objs3后,观察发现使用use_concat时也同样没有使用动态采样(由zsj_objs2,zsj_objs3的card估算值和上面使用提示明确禁止动态采样时的card值完全一样确定这里没有使用动态采样),但use_concat的各个部分的card估算(就是not in的结果集行数估算)却没有出现都为1的情况.这里就不继续深究这个问题了,毕竟优化器这个东西实在是太深不可测了.
现在基本上可以确定的是使用use_concat特性时,not in后半部为临时表时,不使用动态采样,not in时各个部分card估算都为1.
我设置optimizer_dynamic_sampling为4,10也是这样的结果.如果说和动态采样级别设置有关的话,在更高的级别上开始使用动态采样了,我可以理解为这个级别上存在某种限制条件,它不满足这些条件,使得它不能使用动态采样,可optimizer_dynamic_sampling=10时仍然不能使用动态采样,且不使用use_concat时在2的级别上就开始可以使用动态采样,所以我觉得这是一个和use_concat特性相关的bug的可能性还是很大的.
进一步实验,还可以发现,use_concat时不仅对于not in后半部没有收集统计信息的对象不使用动态采样,in后半部没有收集统计信息的对象也同样不使用动态采样,这两个都和这个对象是不是临时表没有关系,只要没有收集对象统计信息,就都不使用动态采样.但临时表和常规表的处理还是不太一样的,not in后半部是临时表的话,这个not in结果集估算似乎永远是0行,也就是card=1,但如果是普通表的话,并不是这样的,not in结果集行数的估算还是有点靠谱的.in的时候,后半部是临时表的话,in的结果集行数估算似乎永远是前半部的结果集行数的估算值的,不会有任何的减少(特别是我这里是id in,我这里的id可是主键呀,我22W的数据in8168行的数据后还是22W行数据,应用谓词返回10W行记录,in后还是返回10W行记录,一点儿也没减少),而后半部是普通表的话,in结果集的估算就不那么不靠谱了,10W行的数据in 7597行数据之后估算返回了9925行数据,至少不是10W行数据一点儿也没变少了.这个东西也不深究下去了.
最后,简单的总结一下这个问题就是:因为动态采样的限制也好,或者是bug也好(我觉得bug的可能性还是很大的),使用use_concat时,对于not in后半部是临时表时,不使用动态采样,如果这个临时表又没有收集统计信息的话,会导致use_concat的各个部分的not in结果集估算返回0行,进而导致其它的性能上的问题.
到了这一步,其实解决方案已经很明显了,那就是不使用动态采样这个方案,直接收集临时表的统计信息就可以了(默认是不收集临时表的统计信息的,gather_temp 默认是false的).
exec dbms_stats.gather_table_stats(user,'ZSJ_TEMP',estimate_percent => 100,method_opt => 'FOR ALL COLUMNS SIZE 1',no_invalidate => FALSE);
因为从实际的应用逻辑来看,MIDS_BLOCK_ARTILIST_MORE_TEMP2这个临时表要么是没有任何数据的,要么是有极少数的数据行的(一般就是几行数据),于是我新开启了一个会话,在这个会话中调用一个调用这个sql的典型过程,传入典型输入值参数(这个过程可能要往这个临时表中插入极少的数据的),然后在这个会话中收集这个临时表的优化器统计信息(实际上随便开启一个会话,直接收集这个临时表的优化器统计信息,也是没有什么问题的,因为这个临时表基本上要么就是没有数据,要么就是几行数据而已,按没有数据去收集优化器统计信息也是没有什么问题的,但我总担心这个0行数据可能会在某些场合下触发MERGE JOIN CARTESIAN这个绝大多数实际情况下可能很糟糕的执行计划,所以按插入几行数据后收集优化器统计信息处理的).如果应用逻辑没有大的变化,这个临时表始终不会有多少数据的话,这样一次性收集完统计信息就可以了,不需要为它设置单独的优化器统计信息收集策略来定时收集的.当然,因为这是一个on commit preserve rows的临时表,插入典型数据后在同一个会话中收集统计信息就可以了.如果这是一个on commit delete rows的临时表的话,因为dbms_stats.gather_*前会有一个commit动作,所以对于这种临时表还不能这样收集统计信息,只能手工的设置优化器统计信息了.当然,实际处理这个问题的时候,我远没有花费这么长的时间,在看到8168这个临时表的card估算值的时候,我就意识到没有动态采样了,所以直接就采用了这里的解决方案了.
从这个案例,你可以看到无论是限制也好,还是说bug也好,我们并不是总能使用动态采样这个特性的,而且动态采样在硬分析时是有代价的,它会执行带有/* OPT_DYN_SAMP */这样注释的sql语句来执行动态采样数据动作的,而且如果它硬分析时动态采样到的刚好是非典型值的话,可能会生成糟糕的执行计划的.所以随意的使用动态采样,其实也是一种不负责任的行为,对于临时表,还是在插入代表性数据之后手工收集统计信息的好,对于新建的普通表,在加载完数据后,立即手工收集统计信息为好.
其实这个sql是一个过程里调用的,这个数据库的这个过程是在另一个数据库的过程的基础上修改而来的,原来的过程不好的地方都被它给继承过来了。半年前我对那个过程做过一些优化调整,效果还是很好的,年前的事情还是多一些,打算年后整理一下。
- use_concat导致not in时临时表不动态采样进而导致的性能问题
- 解决 ORACLE 11.2 动态采样导致的性能问题
- Db2性能问题:临时表空间太大,导致连不上数据库
- 头文件和.a(库文件不匹配)导致虚函数错位,进而导致的bug
- 动态内存分配导致Javascript性能的问题
- 数据分布不均衡导致性能问题
- decodeURIComponent导致的性能问题
- NL驱动表错误导致的性能问题
- 网卡配置导致的网络性能问题
- 异常的错误使用导致性能问题
- resmgr:cpu quantum导致的性能问题
- 导致性能问题的常见情况
- 一个监控软件导致的性能问题
- 自定义函数导致的sql性能问题
- maven/plugin开发:插件版本不匹配导致的报错:Method: ‘name’ not found in class in ParameterAnnotationContent
- session不及时释放导致内存溢出的性能问题分析
- session不及时释放导致内存溢出的性能问题分析
- Tomcat Session机制,不及时释放导致内存溢出的性能问题分析
- qt qt/e configure
- AJAX的跨域访问-两种有效的解决方案
- c语言 #define 中的UL
- 插入flash(swf)代码,及flash常用的参数设置
- Asp.net MVC 3实例学习之ExtShop(四)——完成产品列表页
- use_concat导致not in时临时表不动态采样进而导致的性能问题
- 对特征值 特征向量的理解
- Python悖论
- repeater pageDataSource 分页
- Airodump-ng_for_Windows_使用方法
- 修改android mac地址
- 找工作 选大公司还是小公司
- NDK学习历程
- 一个可以记住上一次的选择的选择目录的对话框的实现代码段


