N元语言模型的解码算法
来源:互联网 发布:python 接收get请求 编辑:程序博客网 时间:2024/05/08 13:31
------------------------------------------------------------------
大家好,我是Bright,微软拼音的软件开发工程师。我之前介绍了N元语言模型的训练方法,本文继续介绍N元语言模型的解码算法。
------------------------------------------------------------------
N元语言模型的解码(Decoding)算法是微软拼音输入法的核心算法,也是当年哈工大王晓龙教授提出的语句级输入法的精髓。那么为什么需要解码算法呢?先举个拼音输入的例子:
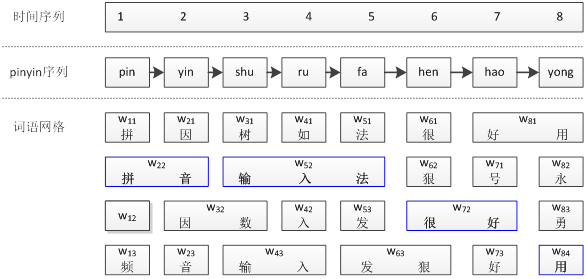
对于拼音序列:pin yin shu ru fa hen hao yong
它有很多种转换结果,如pin可以转换成“拼”、“品”、“频”、“聘”等,yin可以转换成“音”、“因”、“引”、“印”等,shu可以转换成“输”、“树”、“属”、“数”等。
[背景知识]:简体中文大约有400个合法的拼音,GBK汉字大约有18000个汉字,那么平均每个拼音对应45个汉字。
由于每个拼音都有很多个转换结果,那么对于上面的拼音序列(8个拼音)约有45^8种转换结果,我们希望给出一个对用户来说最好的转换结果。
说到“最好”,可能有些歧义,因为对用户A好的转换结果可能对用户B就不好。这里说的最好是说最符合语言规律、最符号语言现象的结果。在N元语言模型的理论框架下,“最好”的结果就是具有最大概率的转换结果。
如果语言模型是以词语为基本语言单位,那么N元语言模型的概率为:
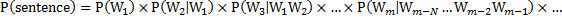
上面的公式中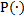 的就是通过N元语言模型训练算法得到的参数。
的就是通过N元语言模型训练算法得到的参数。
对于二元语言模型(bigram),上面的概率简化为:
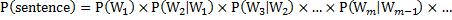
对于一元语言模型(unigram),上面的概率还可以简化为:
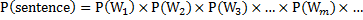
我们可以从诸多转换结果中找出上面概率最大的句子(sentence),对应的算法就是N元语言模型的解码算法。
下面以最常用的二元语言模型为例,介绍一下解码算法。首先根据上面的拼音输入序列,构建词语网格(如下图)。该图对词语网格做了简化,只画出了少量的词语。
-------------------------------------------------------
输入:
M = 每列最多词语数;
T= 拼音序列中的拼音数;
w[1:T,1:M]=词网格;
Bigram(x,y) = 任意两个词语对应的Bigram概率;
输出:
概率最大词语序列TARGET[1:T];
初始化:
w[0,0] = “”;
Prob[0,0] = 1
TARGET[1:T]={“”};
解码:
For t = 1 : T Do
For i = 1 : M Do
MaxProb = 0;
Index = 0;
For j = 1 : M Do
ThisProb = Prob[t-1,j]*Bigram(w[t-1,j],w[t,i]);
If ThisProb > MaxProb
MaxProb = ThisProb;
Index = j;
End If
End For
Prob[t,i] = MaxProb;
Ptr[t,i] = j;
End For
End For
终止:
Prob = 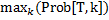 ; // 最后一列中最大的概率
; // 最后一列中最大的概率
TARGET [T]= 最后一列取得最大概率的那个词语w[T,k];
回溯:
t = T;
While t > 0 Do
s = t – Len(TARGET [T]);
TARGET[s] = w[s,Ptr[t, TARGET[t]]]
t = s;
End While
-------------------------------------------------------
上面是最基本的解码算法,实际工程中,需要考虑的因素还有很多,比如音节切分歧义、大规模解码算法的剪枝、更高阶N元模型的解码算法等。
- N元语言模型的解码算法
- N元语言模型的解码算法
- N元语言模型
- N元语言模型
- N元语言模型的训练方法
- N元语言模型的训练方法
- 分词学习(3),基于ngram语言模型的n元分词
- 分词学习(3),基于ngram语言模型的n元分词
- 基于n元语言模型整句拼音汉字转换
- N元模型
- 隐马尔可夫模型的Viterbi解码算法
- 隐马尔可夫模型的Viterbi解码算法
- N元分词算法
- 隐马尔科夫模型的解码算法和前向算法
- ARPA的n-gram语言模型格式
- ARPA的n-gram语言模型格式
- 语言模型/N-Gram模型
- 语言模型n-gram
- mvc 用户控件 Html.RenderAction() 与 Html.RenderPartial() 区别
- Log4j——JAVA系统日志
- qt slider scroll bar 进度条 自定义(通过style sheet)
- 泛型(Generic)小结
- Windows窗体类消息处理
- N元语言模型的解码算法
- vb 读取文件属性
- 网络服务器编程入门
- [ZZ] VC++6.0调试篇:内存断点
- AIX下安装bash
- 虚拟学习社区建设的一些见解
- Javascript传奇
- gdb
- 虚拟学习社区建设的一些见解


