信息检索常用的性能评价指标
来源:互联网 发布:greendao查询所有数据 编辑:程序博客网 时间:2024/04/30 11:10
1 查全率与查准率
传统的信息检索评价指标主要是查全率与查准率,
查全率是指返回结果中相关文档数量与系统中总的相关文档数量的比率,主要反映检索系统召回相关结果的完整性。
查准率是指返回结果中相关文档的数量与结果总数的比值,反映检索系统查询结果的准确度。
recall = num(查询结果集中相关文档)/num(系统中总的相关文档)
precision = num(查询结果中相关文档)/num(查询结果总的文档)
查全率与查准率之间是相关的,总的结果数量越多,查全的可能性就越大,查全率就越高,相反误检的数量也越多,查准率也越多。反之亦然。
一个综合查全与查准的指标:F1(recall,precision) = 2recall*precision/(recall+precision)
查全率的计算(来源于互动百科):
衡量某一情报检索系统从特定文献集合中检出相关文献成功度的一项指标。它的数值等于 w/x,式中 w为用户鉴别检出的 m篇文献时,认为实际对口径的文献篇数,x 为特定检索系统中所包括的全部 n篇文献中实际与某一课题相关的文献篇数。这一指标最初是由J.W.佩里与A.肯特等人于1956年提出的。F.W.兰开斯特于1979年在《情报检索系统──特性、试验与评价》一书(第二版)中将上述n篇文献表达为a+b+c+d之和,并采用下列2×2表。
 查全率
查全率上述m篇文献应为a+b,w篇文献应为a,x 篇文献应为a+c。查全率可表述为a/(a+c),式中a 值经过一次检索即可判定,c值一般可用下述4种方法确定:①若n 值不大,逐篇鉴别各篇文献,即可确定c值。②若n值很大,可对未检出文献随机抽样,如抽样为1/100,其中有r篇文献是相关的,则估计c=100r。③由有经验的用户去鉴别检出的文献,若他认为这次检出了2/3 的全部相关文献,则c=1-2/3=1/3。④通过不同途径去检索同一课题的文献,把各次检出的文献加在一起,剔除重复,形成一份较完整的相关文献清单,以此对比每次检出的相关文献,即可知道相应的c值。有了a值与c 值,代入公式a/ (a+c),即可求出查全率。一般来说,检索工具的标引深度越大,查全率也就越高。标引过程的网罗性越好,查全率也就越高。C.W.克莱弗登1963年通过试验揭示查全率与查准率一般呈互逆相关关系,即提高查全率往往要降低查准率,反之亦然。1982、1983年中国已有人用概率论与微积分证明了这一经验定律,并对查全率、查准率相关矩阵边线与隅角的物理意义作出了进一步的科学解释。
2 TSAP(TREC-styleaverage precision)


其中当第i个文档是相关文档时ri = 1/i, 否则i = 0. N代表取前N个文档做为衡量指标。通常来说相关文档应尽量排在前面,前N篇文档中相关文档的数量越多,相关文档的位置越靠前,TSAP@N 会越大,检索系统的精确程度越好。
3MAP(Mean average precision)
MAP用来衡量排序结果的精确率。假定文档只分为相关与不相关两种,P(n)表示前n项结果的精确率。
P(n) = (number of positive instances within n) / n;
基于P(n)的平均查询准确率AP为:
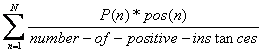
其中N表示检索出文档的总数量,pos(n)表示第n篇文档是否为相关文档,如果是则为1,否则为0。MAP即为对测试集中所有的查询求AP的平均值。
4 NDCG(Normalized discount cumulative gain)
NDCG用来衡量排序结果的准确率,使用文档数值化而非二值化的文档相关性。
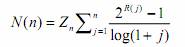
R(j) 表示第j篇文档的相关分值,Zn是关于n的一个标准化因子,NDCG只计算检出的文档即可。
- 信息检索常用的性能评价指标
- 信息检索的评价指标
- 信息检索的评价指标
- 信息检索常用评价指标总结
- 信息检索IR的评价指标综述
- 信息检索IR的评价指标综述
- 信息检索中常用的评价指标:MAP,nDCG,ERR,F-measure
- 信息检索中常用的评价指标:MAP,nDCG,ERR,F-measure
- 信息检索的评价指标:Recall,Precision,AP,MAP,ROC
- 【转载】信息检索IR的评价指标综述
- 信息检索的评价指标(Precision, Recall, F-score, MAP)
- 信息检索的评价指标(Precision, Recall, F-score, MAP)
- 信息检索的评价指标(Precision, Recall, F-score, MAP)
- 信息检索(IR)的评价指标介绍
- 信息检索:对搜索引擎性能的评价指标的小作业---pooling方法以及MAP value的计算
- 信息检索Information Retrieval评价指标
- 信息检索评价指标NDCG、a-NDCG
- 计算机性能的评价指标
- 修复或更改文件关联图标
- Lucene.Net-内存溢出问题解决
- 关于Java的错误:Exception in thread "main" java.lang.NoClassDe...
- device_create分析
- IIS发布网站后,连接Oracle数据库出错解决办法(9i+10g)
- 信息检索常用的性能评价指标
- 表变量与临时表的优缺点
- MLDN JAVA-web培训视频教程
- 进来理一下关系,绕死你!
- SNS
- Linux 下 apache + resin 安装与整合
- MFC CListCtrl 取消选中
- FFmpeg的C++封装:FFmpegWrapper
- Windows下FFmpeg快速入门


