全文检索----新手入门(四)
来源:互联网 发布:阿里云切换按流量收费 编辑:程序博客网 时间:2024/05/05 15:20
搜索主要分为以下几步
第一步:用户输入查询语句
查询语句同我们普通的语言一样,也是有一定语法的。
不同的查询语句有不同的语法,如SQL语句就有一定的语法。
查询语句的语法根据全文检索系统的实现而不同。最基本的有比如:And,Or,Not等。
举个例子,用户输入语句:lucene and learned not hadoop
说明用户想找一个包含lucene 和learned 然而不包括 hadoop的文档
第二步:对查询语句进行词法分析,语法分析,及语言处理。
由于查询有语法,因而也要进行词法分析,语法分析,及语言处理。
1.词法分析主要用来识别单词和关键字。
如上述例子中,经过词法分析,得到有lucene,learned,hadoop,关键字有 and,not。
如果在词法分析中发现不合法的关键字,则会出现错误。如lucene amd learned ,其中由于 and拼错,导致amd作为一个普通的单词参
与查询。
2.语法分析主要是根据查询语句的语法规则来形成一颗语法树
如果发现查询语句不满足语法规则,则会报错。如 lucene not and learned ,则会出错。
如上述例子,lucene and learned not hadoop 形成的语法树如下:
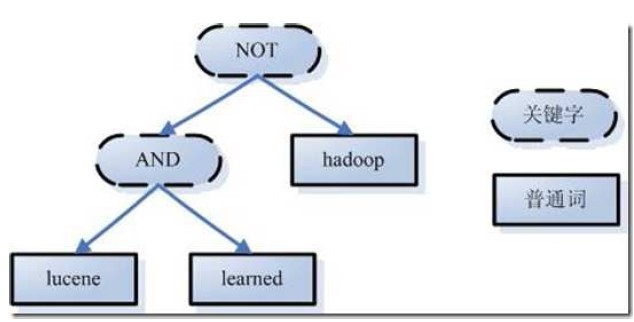
第三步:搜索索引,得到符合语法树的文档
此步骤分几小步:
1.首先,在反向索引表中,分别找出包含lucene,learn,hadoop的文档链表
2.其次,对包含lucene,learn的链表进行合并操作,得到既包含lucene又包含learn的文档链表。
3.然后,将此链表与hadoop的文档链表进行差操作,去除包含hadoop的文档,从而得到既包含lucene又包含learn而且不包含hadoop
的文档链表。
4.此文档链表就是我们要找的文档。
第四步:根据得到的文档和查询语句的相关性,对结果进行排序
虽然在上一步,我们得到了想要的文档,然而对于查询结果应该按照与查询语句的相关性进行排序,越相关者越靠前。
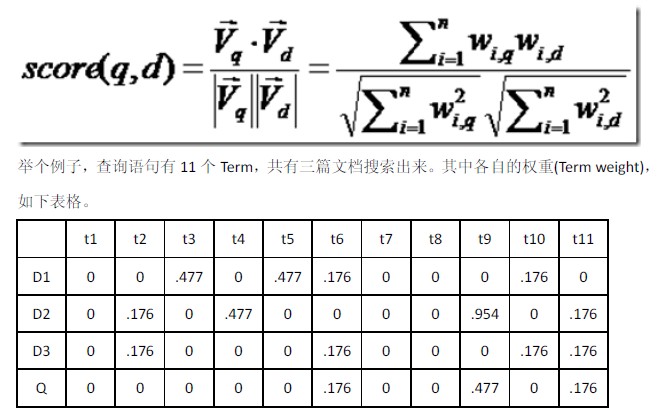
如何计算文档和查询语句的相关性呢?
不如我们把查询语句看做是一篇短小的文档,对文档与文档之间的相关性进行打分,分数越高的相关性越好,就应该排在前面。
贴上一篇讲的比较好的文章



分析了两种关系,下面看一下如何判断文档之间的关系了。
首先,一个文档有很多词(Term)组成,如search,lucene,full-text,this,a,what等。
其次对于文档之间的关系,不同的Term重要性不同,比如search,lucene,full-text就相对重要一些,this,a,what可能相对不重要一
些
因而判断文档之间的关系,首先找出那些词(Term)对文档之间的关系最重要,如search,lucene,full-text。然后判断这些词
(Term)之间的关系。
找出词(Term)对文档的重要性的过程称为计算词的权重(Term weight)的过程。
计算词的权重(term weight)有两个参数,第一个词(Term),第二个是文档(Document)。词的权重(Term weight)表示此词
(Term)在此文档中的重要程度,越重要的词(Term)有越大的权重(Term weight),因而在计算文档之间的相关性中将发挥更大的作
用.
判断词(Term)之间的关系从而得到文档相关性的过程应用一种叫做向量空间模型的算法(Vector Space Model)
也是贴上一篇比较好的文档.









- 全文检索----新手入门(四)
- 全文检索----新手入门(一)
- 全文检索Lucene(四)---Compass框架
- 全文检索(四)
- Lucene 全文检索实践四
- 千万级数据的全文检索搜索引擎(四)
- 全文索引------新手入门(二)
- 全文索引---新手入门(三)
- 全文检索(lucene)
- 全文检索lucene学习笔记(四)
- 全文检索lucene学习笔记(四)
- Pomelo 新手入门(四)
- python新手入门(四)
- 全文检索(lucene)开发
- Hibernate search(全文检索)
- 使用Solr构建企业级的全文检索(四)---------写入文档
- 全文检索
- 全文检索
- 最近在做EDA设计,犯了一个错误,不知何原因,大家看后避免之。。。
- inux C 正则表达式
- customvalidator控件的使用
- asp 开发部署问题两则
- NET使用一般处理程序生成验证码!
- 全文检索----新手入门(四)
- POJ-1503-大整数加法
- SQL分页语句,.NET中获取字符串的MD5码
- 使用keepalive+lvs实现mysql master-master自动故障转移
- 设置DB_CREATE_FILE_DEST初始化参数
- GB2312简体中文编码表
- 第一次开始自己的blog
- 电脑如何通过GPRS手机上网
- java helloworld的一点自我解释


