High Performance Post-Processing
来源:互联网 发布:racemenu男性捏脸数据 编辑:程序博客网 时间:2024/04/29 02:50

link:
http://www.gdcvault.com/play/1014304/Advanced-Visual-Effects-with-DirectX
主要介绍computer shader硬件结构特性,以及在DOF系列feature上的引用。
这是一个比较hardcore的ppt,nice。
dx11和compute shader牛逼太多了,希望业界能够快速进入这个时代。
ThreadGroup
显卡里的多核架构和cpu端多核架构很多地方是重复的,重复部分跳过,看下特别的:thread group。
thread group是一组thread,他们有一个shared memory,这个是其强力的核心,其中的thread可以彼此共享资源,比如说做一个blur,传统pixel shader就是每一个fragment读取13个点来做blur,这样12个fragment就是12*13的读取量。
如果变成thread group的方式就是大家彼此之间有共享,大量的重复读取可以省略了。
Divergence
理论上thread是独立运行的,实际上在硬件里是一组组的(这个一组和thread group不是一个东西),叫做wavefront,在nv里目前是32个一组,amd里面是64.
于是有一个现象就是针对branch,如果一个wavefront里的thread在branch中走同一个分支,那么另一个分支会被跳过,否则就会都被都执行。
下图可以看见,性能差距还是比较大的。
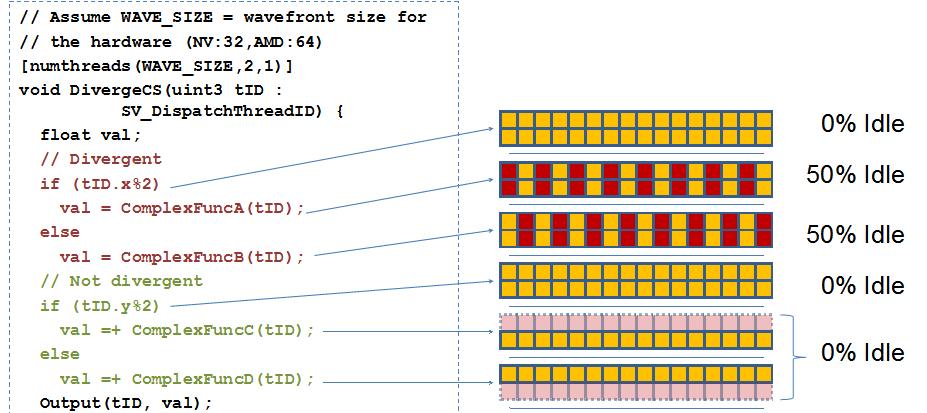
实际应用中,是一个具体情况具体分析,在走同一个branch的情况下是很赚的,否则就亏,那么对于pixel shader可以看出两种情况下的选择优劣:

compute shader
dx11以及direct compute在显卡日益强劲的今天,即便只是针对于graphics,相对于dx9可以说革命性的。
计算模型从原先的vs,ps,texture unit, rasterizer进一步的解放出来,tessellation只是小试牛刀,更大的自由度给hardcore programmer更大的发挥空间。
在这片算法蓝海里,在相当长时间里,可以创造出更多的利用这些硬件的pipeline和solution。
硬件能力的提升是一步步走的,而且相对于所有人是一样的。
算法的提升则可以获得更快的速度,正是这些让同一个时代的工作室创造出不同时代的游戏。
就像ps3上的spu带来的东西一样,强力并且长期积累的工作室在一段时间之后会取得压倒性优势。
compute shader可以让程序员更好的控制计算资源的分配。
其他
shader model 5.0里面的unordered access view很不错,pixel shader可以输出到任意地方,而不是像sm4里面只能是固定的一个地方。这个对象近景depth of field都是非常有好处的。
说到这里之后其他的就顺理成章,比如加法就要用多线程思维来做prefix sum的算法,同理DOF也方便多了。
在做Bokeh效果,就是第一个图里面背景亮的点是一个“亮片”的效果,使用unorded access view,一个brightpass输出亮的点到一个buffer,再用这个buffer当新的顶点用,生成一个个亮片,效果现在很流行。
- High Performance Post-Processing
- High Performance Parallel Database Processing and Grid Databases
- High performance
- Sector/Sphere:High Performance Distributed File System and Parallel Data Processing Engine
- Install _ zimg - A lightweight and high performance image storage and processing system.
- High Performance MySQL
- Leading High-Performance Projects
- High performance network programming
- High Performance Computer Architecture
- Build High performance Server
- High performance MySQL-- 笔记
- High-Performance Server Architecture
- high-performance server architecture
- High Performance Computing Training
- High Performance Computing Training
- High performance Web Sites
- High performance IOCP
- High-Performance Server Architecture
- 基于.NET平台的分层架构实战(七-外一篇)——对数据访问层第一种实现(Access+SQL)的重构
- 3094
- 基于.NET平台的分层架构实战(八)——数据访问层的第二种实现:SQLServer+存储过程
- 一个简单的Java信号量例子
- Linux常用命令
- High Performance Post-Processing
- 测试代码插入插件
- FTP用户权限
- VS2010 的版本
- 基于.NET平台的分层架构实战(九)——数据访问层的第三种实现:基于NBear框架的ORM实现
- asp.net页面指令和事件(转自:http://my.oschina.net/dxf/blog/269)
- 基于.NET平台的分层架构实战(十)——业务逻辑层的实现
- 基于.NET平台的分层架构实战(十一)——表示层的实现
- PHP操作mysql数据库的函数集合


