常见排序算法介绍
来源:互联网 发布:深圳软件大厦邮编 编辑:程序博客网 时间:2024/04/29 02:21
惭愧啊。学了这么久的计算机了。其实到本学期的某天之前连一个基本的排序算法都写不出。直到某天某时的某分某秒YYN跑到偶面前说要我叫她写排序的算法,偶那个时候就晕了。真的写不出来啊,偶当时就想挖个地洞把自己深埋深埋再深埋,不过后来想想,偶要是把自己埋了,到了春天,又不会长出很多很多的帅哥(自恋无罪吧?),还不如用挖洞的时间来研究一下排序算法不就得了?~~~偶以前一直认为,排序算法这些基础的东西不是C++有sort,C有qsort么?干嘛费劲自己去研究库函数里面有的函数呢?其实,这都是借口吧,借口!所以,经过到网上查找资料,自己慢慢理解排序算法,于是,有了这篇博文。在这篇博文中,我打算介绍十种排序算法,额,到现在位置我还只理解了六种排序的算法。其他的,等我理解一种之后就更新一下这篇博文吧。大家先凑合着看吧。
我打算按照算法理解的难度从容易到复杂依次介绍每种排序算法。基本上是按照算法的复杂度从高到底吧。好了,开始我的介绍排序算法之旅了。
-------------------------------------------------------------我是无奈的分割线-------------------------------------------------------------
选择排序(select sort)的思想就是从一个从有n个数中找出一个最小得到或者是最大的数放到前面来,再从剩下的n-1个数中找出一个最小的或者最大的放到第二个,如此反复,经过n次后,数组就会变得有序了。打个很简单的比方吧,如果我们班啥时候要搞个啥选美活动了,要为我们班的MM排个名,偶就会用这种思想,先选出一个偶觉得最漂亮的MM放到第一个,然后再从剩下的MM中再选一个放到第二个……如此反复在剩下的MM中选偶觉得最漂亮的。(额……这个例子总觉得有点牵强附会呢)。好了,例子可能看不懂,偶就举个选择排序的过程吧:
初始关键字 [49 38 65 97 76 13 27 49]
第一趟排序后 13 [38 65 97 76 49 27 49]
第二趟排序后 13 27 [65 97 76 49 38 49]
第三趟排序后 13 27 38 [97 76 49 65 49]
第四趟排序后 13 27 38 49 [76 97 65 49 ]
第五趟排序后 13 27 38 49 49 [97 65 76]
第六趟排序后 13 27 38 49 49 65 [97 76]
第七趟排序后 13 27 38 49 49 65 76 [97]
最后排序结果 13 27 38 49 49 65 76 97
这样应该理解了吧。前面的绿色的数字表示已经排序好了的数字,后面的[]里面的数字表示待选待排序的数字。嗯嗯,我觉得应该能够理解了。那偶就贴代码了。
好了,Code出来了,分析一下复杂度。显然,两个for循环,时间复杂度为O(n2)。
-------------------------------------------------------------我是无奈的分割线-------------------------------------------------------------
OK,接着来介绍一种我应该是学C++语言时候学的一种算法吧。呵呵,其实我学C++的时候打酱油去了,所以,究竟学没学过算法偶也不记得了。不过偶想应该有这个算法吧。因为只要是讲语言(!汇编语言)基础书籍,一般都有这个算法。嗯嗯,是冒泡排序(bubble sort)。为什么叫冒泡排序而不叫泥巴排序呢?这个排序的过程每一趟通过若干次的交换总是把最大的或最小的数字沉到最底下。就像在水中的水泡一样,大的总是会先浮到水面来。额,为什么会先是大的水泡浮到水面来我就不管了。其实我们小学的时候就用到了冒泡的思想了。比如,我们小学排位置的时候,老师先要同学们自己排队,额,当然从矮到高排队。这样,经过我们自己排队,这个队伍基本是从矮到高了,但有些比较高的人想坐到前面一点和MM坐一起,所以他自己也排到前面去了。这个时候,老师就把他和另外一个排在他后面比他矮的同学交换一下位置,于是,他的奸计就没得逞了~~~这就是冒泡思想。遇到相邻的两个数,要是前面的比后面的大,就把他们交换位置,经过这样一趟,最大的数字肯定就沉到后面去了……反复使用这个方法,最终数组中的数字就变成有序的了。要是没有明白,那就不晓得是偶的杯具还是你的杯具了……要是还不懂,偶在下面演示冒泡一次排序的过程,凑合看一下咯。
假设初始关键字 [49 38 65 97 76 13 27 49] 。冒泡一次会变成:

经过一次冒泡,就把最大数97冒泡到最下面了。上面的的第二排数表示冒泡一次的结果。然后,冒泡第二次就会把76冒泡到倒数第二个位置……好了,不再解释过多了,该贴源码的时候了:
OK,冒泡排序到此结束。随便提一下时间复杂度,又是两个for循环,为O(n2)。
-------------------------------------------------------------我是无奈的分割线-------------------------------------------------------------
接下来我要介绍的是插入排序。插入排序我想大家在生活中早就接触过了吧。我们玩牌的时候如果你希望你抓牌的牌在你手上是有序的,那么抓牌过程就是不断的在使用插入排序的思想。每当你抓到一个牌,你就会把这个牌插入到已经排好序的适当的位置。嗯嗯,要是你说你还没玩过牌呢,那么,我就不晓得是应该恭喜你呢,还是……。插入排序的思想就是每次在待排序的数组中选一个插入到已经排好序的数组中的适当位置。嗯,放心,不要额外的辅助数组空间的。嗯嗯,你要是还不明白或者你真的没玩过扑克牌,下面我还是做个插入排序的例子吧,我还是用上面的初始关键字 [49 38 65 97 76 13 27 49]。
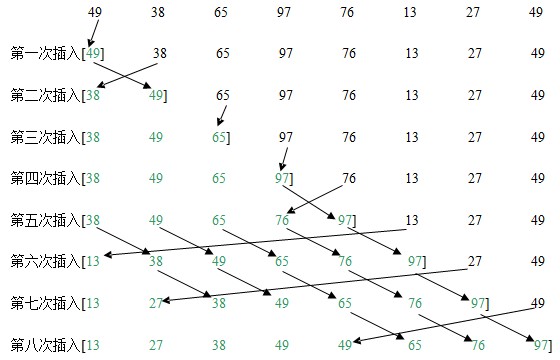
上面的示意图左边[]里面绿色的数字表示已经排好序的数,后面的数表示待排序的数字。好了,偶就贴源码了:
插入排序在实际中如果数据量比较少,还是一个不错的选择。算法复杂度为O(n2)。值得一提的是,插入排序在已排序的数组中找待插入数的位置,可以用二分法加快速度。代码我就不写了。
-------------------------------------------------------------我是无奈的分割线-------------------------------------------------------------
按照算法的复杂度理论,上面介绍的三种算法的复杂度都是O(n2),你可能自然就会想,既然复杂度都是一样的,为什么还要这三种呢,呵呵。简单一点解释就是存在即合理。呵呵,当然,这样解释太不令人信服了。我来稍微说一下我的想法吧。虽然这三个算法的平均复杂度是一样的,但实际使用算法的时候还是有点差别的。比如说吧,数组在基本有序的情况下,你肯定不会傻兮兮的去使用选择排序吧,使用冒泡排序和插入排序就能很快完成,在上面我举的例子中就可以看出,插入排序有的时候只要移动很少一部分元素就能完成一个元素的插入。其实,这三种算法我觉得比较好的是插入排序吧,你可能会说冒泡排序有可能在中间就已经有序了,但我认为冒泡排序需要交换元素太多。至于选择排序嘛,复杂度永远为O(n2)。没有啥好坏之分,插入排序和冒泡排序嘛,看你RP如何吧。
好了,抛开RP不说,上面的复杂度最坏情况都为O(n2)。人们自然会想,能不能把他的复杂度降下来呢?O(n2)的复杂度确实太高了。人们想啊想,想啊想,想啊想……终于出了一个了不起的人物,这个人物的名字不叫lcq,叫DL.Shell。他想出来的算法终于把复杂度降到了nlog2n。不要对复杂度从O(n2)降到O(nlog2n)不以为然。打个很简单的比分,如果你要对220=1048576(不要数它的位数了,大概1百万)个数进行排序,那么,如果O(nlog2n)的复杂度能够在1S内完成,O(n2)则必须足足花14.5天。而且数字越大,相差的倍数越大。既然是他发明的排序,所以我们理所当然就用他的名字命名了,叫希尔排序(shell sort),根据算法的思想,还有一个名字,叫缩小增量排序。如果你理解了插入排序,希尔排序就很自然明白了……
插入排序(Insert Sort)的一个重要的特点是,如果原始数据的大部分元素已经排序,那么插入排序的速度很快(因为需要移动的元素很少)。从这个事实我们可以想到,如果原始数据只有很少元素,那么排序的速度也很快。--希尔排序就是基于这两点对插入排序作出了改进。
例如,有100个整数需要排序。
1.第一趟排序先把它分成50组,每组2个整数,分别排序。
2.第二趟排序再把经过第一趟排序后的100个整数分成25组,每组4个整数,分别排序。
3.第三趟排序再把前一次排序后的数分成12组,第组8个整数,分别排序。
4.照这样子分下去,最后一趟分成100组,每组一个整数,这就相当于一次插入排序。
由于开始时每组只有很少整数,所以排序很快。之后每组含有的整数越来越多,但是由于这些数也越来越有序,所以排序速度也很快。
好了,贴代码:
关于希尔排序的复杂度,分析起来对于我来说比较难,反正我是没有弄懂,等以后懂了之后,再来补充一下吧。反正平均复杂度是nlog2n。好了,开始介绍下面一种排序算法了,它就是我们经常使用的快速排序,简称快排。
-------------------------------------------------------------我是无奈的分割线-------------------------------------------------------------
快速排序(quick sort)是不是真的像它的名字那样,排序速度很快呢?那就先来看快速排序的思想吧。
快速排序主要是使用分治的方法来把一个序列完成排序。它的主要步骤为:
①在待排序的数组中选取一个基准数。(通常我们选取待排序数组的第一个数)。
②把小于或等于基准数的数字放在基准数的左边,把大于或等于基准数的数字放在基准数的右边。
③递归地使用把小于基准数的数列排序和大于基准数列的数字排序。
OK,那就按照这个思想写代码吧:
快速排序的复杂度也是一个比较难分析的问题。它也是一个不稳定的排序,又要看你的RP,你的RP决定了你选的base,进而base决定了快排的速度。记下平均复杂度吧:nlog2n。接下来又介绍一个复杂度稳定为nlog2n的算法。放心,这个算法别看他的代码很长,其实比希尔排序和快速排序容易理解多了,他的名字要是叫泥巴排序就好了,可惜不是,它叫归并排序(merge sort)。
-------------------------------------------------------------我是无奈的分割线-------------------------------------------------------------
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。 嗯嗯,偶在网上找了一个图片,大家看下图片应该就能够懂吧:
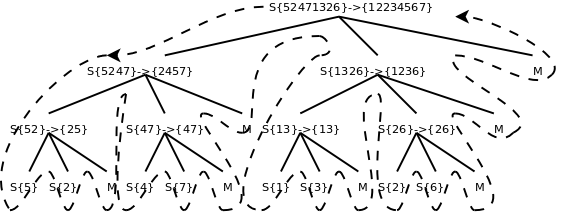
图中S表示mergeSort函数,M表示merge函数,整个控制流程沿虚线所示的方向调用和返回。由于mergeSort函数递归调用了自己两次,所以各函数之间的调用关系呈树状结构。画这个图只是为了清楚地展现归并排序的过程,在理解递归函数时一定不要全部展开来看,而是要抓住递推关系来理解。
归并排序具体工作原理如下(假设序列共有n个元素):
1.将序列每相邻两个数字进行归并操作(merge),形成f l o o r (n / 2) 个序列,排序后每个序列包含两个元素
2.将上述序列再次归并,形成f l o o r (n / 4) 个序列,每个序列包含四个元素
3.重复步骤2,直到所有元素排序完毕
至于归并操作大概过程如下:
1.申请一个能够容纳两个需要归并数组和的空间
2.从两个数组的第一个元素开始,选择最小的元素放到申请的空间
3.经过步骤2要是某个数组还有剩余的元素,把它复制到申请的空间里面
4,把申请空间的元素复制回原数组里面
……我感觉我连自己都不明白我在说了什么,还是自己看下面的代码吧。
归并排序是一种很稳定的排序,时间复杂度nlog2n 。最后还介绍一种堆排序结束这篇博客吧!
-------------------------------------------------------------我是无奈的分割线-------------------------------------------------------------
- 常见排序算法介绍
- 常见hash算法介绍
- 常见的排序算法
- 常见排序算法
- 常见排序算法代码
- 常见排序算法
- 常见排序算法总结
- 常见排序算法
- 常见排序算法学习
- 常见排序算法总结
- 常见的排序算法
- 常见排序算法分析
- 常见排序算法总结
- 常见排序算法
- 常见排序算法
- 常见排序算法小结
- 常见排序算法总结
- 常见经典排序算法
- kmalloc
- 05.05
- Silverlight 2.5D RPG游戏技巧与特效处理:(十四)体感系统
- MySQL数据库备份和还原的常用命令
- 在rhel6下搭建简单Nexus+svn项目管理环境
- 常见排序算法介绍
- 从Twisted谈起异步处理
- DATA abort定位方法
- {电脑救助站}常用知识3
- 我相信
- 使用X.509数字证书加密解密实务(二)-- 使用RSA证书加密敏感数据
- 如何更改在线重做日志文件的大小
- 创建jsp文件
- JavaScript 里面用正则表达式


