SequenceFile 解决hadoop小文件问题
来源:互联网 发布:淘宝贷款逾期四个月了 编辑:程序博客网 时间:2024/04/29 20:13
Overview
SequenceFile is a flat file consisting of binary key/value pairs. It is extensively used in MapReduce as input/output formats. It is also worth noting that, internally, the temporary outputs of maps are stored using SequenceFile.
The SequenceFile provides a Writer, Reader and Sorter classes for writing, reading and sorting respectively.
There are 3 different SequenceFile formats:
- Uncompressed key/value records.
- Record compressed key/value records - only 'values' are compressed here.
- Block compressed key/value records - both keys and values are collected in 'blocks' separately and compressed. The size of the 'block' is configurable.
The recommended way is to use the SequenceFile.createWriter methods to construct the 'preferred' writer implementation.
The SequenceFile.Reader acts as a bridge and can read any of the above SequenceFile formats.
SequenceFile Formats
This section describes the format for the latest 'version 6' of SequenceFiles.
Essentially there are 3 different file formats for SequenceFiles depending on whether compression and block compression are active.
However all of the above formats share a common header (which is used by the SequenceFile.Reader to return the appropriate key/value pairs). The next section summarises the header:
SequenceFile Common Header
version - A byte array: 3 bytes of magic header 'SEQ', followed by 1 byte of actual version no. (e.g. SEQ4 or SEQ6)
- keyClassName - String
- valueClassName - String
compression - A boolean which specifies if compression is turned on for keys/values in this file.
blockCompression - A boolean which specifies if block compression is turned on for keys/values in this file.
compressor class - The classname of the CompressionCodec which is used to compress/decompress keys and/or values in this SequenceFile (if compression is enabled).
metadata - SequenceFile.Metadata for this file (key/value pairs)
- sync - A sync marker to denote end of the header.
All strings are serialized using Text.writeString api.
The formats for Uncompressed and RecordCompressed Writers are very similar:
Uncompressed & RecordCompressed Writer Format
Header
- Record
- Record length
- Key length
- Key
- (Compressed?) Value
- A sync-marker every few k bytes or so.
The sync marker permits seeking to a random point in a file and then re-synchronizing input with record boundaries. This is required to be able to efficiently split large files for MapReduce processing.
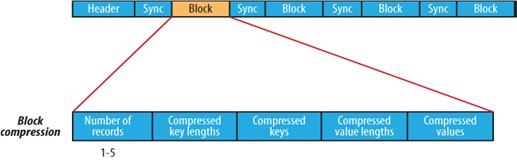
The format for the BlockCompressedWriter is as follows:
BlockCompressed Writer Format
Header
Record Block
A sync-marker to help in seeking to a random point in the file and then seeking to next record block.
CompressedKeyLengthsBlockSize
CompressedKeyLengthsBlock
CompressedKeysBlockSize
CompressedKeysBlock
CompressedValueLengthsBlockSize
CompressedValueLengthsBlock
CompressedValuesBlockSize
CompressedValuesBlock
The compressed blocks of key lengths and value lengths consist of the actual lengths of individual keys/values encoded in ZeroCompressedInteger format.
SequenceFile 是一个由二进制序列化过的key/value的字节流组成的文本存储文件,它可以在map/reduce过程中的input/output 的format时被使用。在map/reduce过程中,map处理文件的临时输出就是使用SequenceFile处理过的。
SequenceFile分别提供了读、写、排序的操作类。
SequenceFile的操作中有三种处理方式:
1) 不压缩数据直接存储。 //enum.NONE
2) 压缩value值不压缩key值存储的存储方式。//enum.RECORD
3) key/value值都压缩的方式存储。//enum.BLOCK
SequenceFile提供了若干Writer的构造静态获取。
//SequenceFile.createWriter();
SequenceFile.Reader使用了桥接模式,可以读取SequenceFile.Writer中的任何方式的压缩数据。
三种不同的压缩方式是共用一个数据头,流方式的读取会先读取头字节去判断是哪种方式的压缩,然后根据压缩方式去解压缩并反序列化字节流数据,得到可识别的数据。
流的存储头字节格式:
Header:
*字节头”SEQ”, 后跟一个字节表示版本”SEQ4”,”SEQ6”.//这里有点忘了 不记得是怎么处理的了,回头补上做详细解释
*keyClass name
*valueClass name
*compression boolean型的存储标示压缩值是否转变为keys/values值了
*blockcompression boolean型的存储标示是否全压缩的方式转变为keys/values值了
*compressor 压缩处理的类型,比如我用Gzip压缩的Hadoop提供的是GzipCodec什么的..
*元数据 这个大家可看可不看的
所有的String类型的写操作被封装为Hadoop的IO API,Text类型writeString()搞定。
未压缩的和只压缩values值的方式的字节流头部是类似的:
*Header
*RecordLength记录长度
*key Length key值长度
*key 值
*是否压缩标志 boolean
*values
前天项目组里遇到由于sequenceFile 的压缩参数设置为record 而造成存储空间的紧张,后来设置为block 压缩方式的压缩方式,存储空间占用率为record 方式的1/5 。问题虽解决了,但是还不是很清楚这两种方式是如何工作以及他们的区别是啥。昨天和今天利用空闲时间,细细的看了一遍sequenceFile 这个类和一些相关类的源码。
sequenceFile 文件存储有三种方式:可以通过在程序调用 enum CompressionType { NONE , RECORD , BLOCK } 指定,或通过配置文件io.seqfile.compression.type 指定,这三种存储方式如下图:
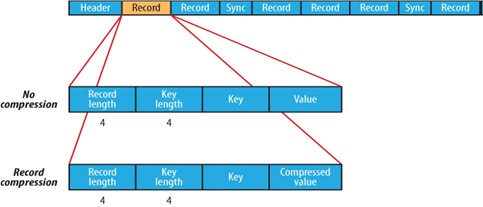
对于Record 压缩这种存储方式,RecordLen 表示的是key 和value 的占用的byte 之和,Record 压缩方式中 key 是不压缩 ,value 是压缩后的值,在record 和非压缩这两种方式,都会隔几条记录插入一个特殊的标号来作为一个同步点Sync ,作用是当指定读取的位置不是记录首部的时候,会读取一个同步点的记录,不至于读取数据的reader “迷失”。 每两千个byte 就插入一个同步点,这个同步点占16 byte ,包括同步点标示符:4byte ,一个同步点的开销是20byte 。
对于block 这种压缩方式, key 和value 都是压缩的 ,通过设置io.seqfile.compress.blocksize 这个参数决定每一个记录块压缩的数据量,默认大小是1000000 byte ,这个值具体指的是key 和value 缓存所占的空间,每要往文件写一条key/value 时,都是将key 和value 的长度以及key 和value 的值缓存在keyLenBuffer keyBuffer valLenBuffer valBuffer 这四个DataOutputStream 中,当keyBuffer.getLength() + valBuffer.getLength() 大于或等于io.seqfile.compress.blocksize 时,将这些数据当做一个block 写入sequence 文件,如上图所示 每个block 之间都会插入一个同步点。
- SequenceFile 解决hadoop小文件问题
- Hadoop 上传小文件 合成sequencefile 记录
- hadoop下将大量小文件生成一个sequenceFile文件
- Hadoop下将大量小文件生成一个sequenceFile文件
- Hadoop下将大量小文件生成一个sequenceFile文件
- hadoop处理sequenceFile文件
- Hadoop序列化文件SequenceFile
- Hadoop序列化文件SequenceFile
- Hadoop 写SequenceFile文件 源代码
- Hadoop的SequenceFile文件<转>
- sequencefile处理小文件实例
- sequencefile处理小文件实例
- Hadoop读取sequencefile和textfile文件内容
- Hadoop SequenceFile 文件写入及格式分析
- hadoop中的文件接口类-- SequenceFile
- Hadoop SequenceFile
- Hadoop SequenceFile
- hadoop SequenceFile
- linux定时任务的设置
- ffmpeg中sws_scale()用法实例
- 定义typedef struct 重定义错误解决办法
- as3碰撞检测(两图重叠区)(例子)
- core文件生成时代进程号
- SequenceFile 解决hadoop小文件问题
- opencv学习
- opencv学习
- opencv学习
- OSS中心服务器集群方案
- 基于SOAP协议的WEB服务研究
- 【数据库】导致“mysql has gone away”的两种情况
- Firefox3中使用XMLHttpRequest(Ajax)发送二进制POST数据的简易调试法
- 动态映射bean 的内部赋值


