在之前的一篇文章 中,介绍了assembleResponse函数(位于instance.cpp第224行),它会根据op操作枚举类型来调用相应的crud操作,枚举类型定义如下:
view plaincopy to clipboardprint?
- enum Operations {
- opReply = 1,
- dbMsg = 1000,
- dbUpdate = 2001,
- dbInsert = 2002,
-
- dbQuery = 2004,
- dbGetMore = 2005,
- dbDelete = 2006,
- dbKillCursors = 2007
- };
可以看到dbDelete = 2002 为删除操作枚举值。当客户端将要删除的记录(或条件的document)发到服务端之后,mongodb通过消息封装方式将数据包中的字节流解析转成 message类型,并进一步转换成dbmessage之后,mongodb就会根据消息类型进行判断,以决定接下来执行的操作),下面我们看一下 assembleResponse在确定是删除操作时调用的方法,如下:
view plaincopy to clipboardprint?
- assembleResponse( Message &m, DbResponse &dbresponse, const SockAddr &client ) {
- .....
- try {
- if ( op == dbInsert ) {
- receivedInsert(m, currentOp);
- }
- else if ( op == dbUpdate ) {
- receivedUpdate(m, currentOp);
- }
- else if ( op == dbDelete ) {
- receivedDelete(m, currentOp);
- }
- else if ( op == dbKillCursors ) {
- currentOp.ensureStarted();
- logThreshold = 10;
- ss << "killcursors ";
- receivedKillCursors(m);
- }
- else {
- mongo::log() << " operation isn't supported: " << op << endl;
- currentOp.done();
- log = true;
- }
- }
- .....
- }
- }
从上面代码可以看出,系统在确定dbDelete操作时,调用了receivedDelete()方法(位于instance.cpp文件第323行),下面是该方法的定义:
view plaincopy to clipboardprint?
- void receivedDelete(Message & m, CurOp & op) {
- DbMessage d(m);
- const char * ns = d.getns();
- assert( * ns);
- uassert( 10056 , " not master " , isMasterNs( ns ) );
- op.debug().str <<
- ns << ' ' ;
-
-
- int flags = d.pullInt();
- bool justOne = flags & RemoveOption_JustOne;
- bool broadcast = flags & RemoveOption_Broadcast;
- assert( d.moreJSObjs() );
- BSONObj pattern = d.nextJsObj();
- {
- string s = pattern.toString();
- op.debug().str << " query: " << s;
- op.setQuery(pattern);
- }
- writelock lk(ns);
-
- if ( ! broadcast & handlePossibleShardedMessage( m , 0 ) )
- return ;
-
- Client::Context ctx(ns);
- long long n = deleteObjects(ns, pattern, justOne, true );
- lastError.getSafe() -> recordDelete( n );
- }
上面方法主要是对消息中的flag信息进行解析,以获取消息中的删除条件等信息,并最终调用 deleteObjects方法,该方法位于query.cpp文件中,如下:
view plaincopy to clipboardprint?
-
-
-
-
-
-
- long long deleteObjects( const char * ns, BSONObj pattern, bool justOneOrig, bool logop, bool god, RemoveSaver * rs ) {
- if ( ! god ) {
- if ( strstr(ns, " .system. " ) ) {
-
-
- uassert( 12050 , " cannot delete from system namespace " , legalClientSystemNS( ns , true ) );
- }
- if ( strchr( ns , ' $ ' ) ) {
- log() << " cannot delete from collection with reserved $ in name: " << ns << endl;
- uassert( 10100 , " cannot delete from collection with reserved $ in name " , strchr(ns, ' $ ' ) == 0 );
- }
- }
- NamespaceDetails * d = nsdetails( ns );
- if ( ! d )
- return 0 ;
- uassert( 10101 , " can't remove from a capped collection " , ! d -> capped );
- long long nDeleted = 0 ;
- int best = 0 ;
- shared_ptr < MultiCursor::CursorOp > opPtr( new DeleteOp( justOneOrig, best ) );
- shared_ptr < MultiCursor > creal( new MultiCursor( ns, pattern, BSONObj(), opPtr, ! god ) );
- if ( ! creal -> ok() )
- return nDeleted;
- shared_ptr < Cursor > cPtr = creal;
- auto_ptr < ClientCursor > cc( new ClientCursor( QueryOption_NoCursorTimeout, cPtr, ns) );
- cc -> setDoingDeletes( true );
- CursorId id = cc -> cursorid();
- bool justOne = justOneOrig;
- bool canYield = ! god && ! creal -> matcher() -> docMatcher().atomic();
- do {
- if ( canYield && ! cc -> yieldSometimes() ) {
- cc.release();
-
- break ;
- }
- if ( ! cc -> ok() ) {
- break ;
- }
-
-
- cc -> setDoingDeletes( true );
- DiskLoc rloc = cc -> currLoc();
- BSONObj key = cc -> currKey();
-
-
- bool match = creal -> matcher() -> matches( key , rloc );
- if ( ! cc -> advance() )
- justOne = true ;
- if ( ! match )
- continue ;
- assert( ! cc -> c() -> getsetdup(rloc) );
- if ( ! justOne ) {
-
-
-
- cc -> c() -> noteLocation();
- }
- if ( logop ) {
- BSONElement e;
- if ( BSONObj( rloc.rec() ).getObjectID( e ) ) {
- BSONObjBuilder b;
- b.append( e );
- bool replJustOne = true ;
- logOp( " d " , ns, b.done(), 0 , & replJustOne );
- }
- else {
- problem() << " deleted object without id, not logging " << endl;
- }
- }
- if ( rs )
- rs -> goingToDelete( rloc.obj() );
- theDataFileMgr.deleteRecord(ns, rloc.rec(), rloc);
- nDeleted ++ ;
- if ( justOne ) {
- break ;
- }
- cc -> c() -> checkLocation();
-
- if ( ! god )
- getDur().commitIfNeeded();
- if ( debug && god && nDeleted == 100 )
- log() << " warning high number of deletes with god=true which could use significant memory " << endl;
- }
- while ( cc -> ok() );
- if ( cc. get () && ClientCursor::find( id , false ) == 0 ) {
- cc.release();
- }
- return nDeleted;
- }
上面的代码主要执行构造查询游标,并将游标指向地址的记录取出来与查询条件进行匹配,如果匹配命中,则进行删除。这里考虑到如果记录在内存时,如果删除 记录后,内存中的b树结构会有影响,所以在删除记录前/后分别执行noteLocation/checkLocation方法以校正 查询cursor的当前位置。因为这里是一个while循环,它会找到所有满足条件的记录,依次删除它们。因为这里使用了MultiCursor,该游标在我看来就是一个复合游标 ,它不仅包括了cursor 中所有功能,还支持or条件操作。而有关游标的构造和继承实现体系,mongodb做的有些复杂,很难几句说清,我会在本系列后面另用篇幅进行说明,敬请期待 。
注意上面代码段中的这行代码:
view plaincopy to clipboardprint?
- theDataFileMgr.deleteRecord(ns, rloc.rec(), rloc);
- 该行代码执行了最终的删除记录操作,其定义如下:
-
-
- void DataFileMgr::deleteRecord( const char * ns, Record * todelete, const DiskLoc & dl, bool cappedOK, bool noWarn) {
- dassert( todelete == dl.rec() );
- NamespaceDetails * d = nsdetails(ns);
- if ( d -> capped && ! cappedOK ) {
- out () << " failing remove on a capped ns " << ns << endl;
- uassert( 10089 , " can't remove from a capped collection " , 0 );
- return ;
- }
-
- ClientCursor::aboutToDelete(dl);
-
- unindexRecord(d, todelete, dl, noWarn);
-
- _deleteRecord(d, ns, todelete, dl);
- NamespaceDetailsTransient::get_w( ns ).notifyOfWriteOp();
- }
上面删除记录方法deleteRecord中,执行的删除顺序与我之前写的那篇插入记录方式正好相反(那篇文章中是选在内存中分配记录然后将地址放到b树 中),这里是先将要删除记录的索引信息删除,然后再删除指定记录(更新内存中的记录信息而不是真的删除,稍后会进行解释)。
首先我们先看一下上面代码段的unindexRecord方法:
view plaincopy to clipboardprint?
-
-
- static void unindexRecord(NamespaceDetails * d, Record * todelete, const DiskLoc & dl, bool noWarn = false ) {
- BSONObj obj(todelete);
- int n = d -> nIndexes;
- for ( int i = 0 ; i < n; i ++ )
- _unindexRecord(d -> idx(i), obj, dl, ! noWarn);
- if ( d -> indexBuildInProgress ) {
-
- _unindexRecord(d -> idx(n), obj, dl, false );
- }
- }
-
-
- static void _unindexRecord(IndexDetails & id, BSONObj & obj, const DiskLoc & dl, bool logMissing = true ) {
- BSONObjSetDefaultOrder keys;
- id.getKeysFromObject(obj, keys);
- for ( BSONObjSetDefaultOrder::iterator i = keys.begin(); i != keys.end(); i ++ ) {
- BSONObj j = * i;
- if ( otherTraceLevel >= 5 ) {
- out () << " _unindexRecord() " << obj.toString();
- out () << " /n unindex: " << j.toString() << endl;
- }
- nUnindexes ++ ;
- bool ok = false ;
- try {
- ok = id.head.btree() -> unindex(id.head, id, j, dl);
- }
- catch (AssertionException & e) {
- problem() << " Assertion failure: _unindex failed " << id.indexNamespace() << endl;
- out () << " Assertion failure: _unindex failed: " << e.what() << ' /n ' ;
- out () << " obj: " << obj.toString() << ' /n ' ;
- out () << " key: " << j.toString() << ' /n ' ;
- out () << " dl: " << dl.toString() << endl;
- sayDbContext();
- }
- if ( ! ok && logMissing ) {
- out () << " unindex failed (key too big?) " << id.indexNamespace() << ' /n ' ;
- }
- }
- }
上面代码主要是把要删除的记录的B树键值信息取出,然后通过循环(可能存在多键索引,具体参见我之前插入记录那篇文章中B树索引构造的相关内容)删除相应B树索引信息,下面代码段就是在B树中查找(locate)并最终删除(delKeyAtPos)的逻辑:
view plaincopy to clipboardprint?
-
-
- bool BtreeBucket::unindex( const DiskLoc thisLoc, IndexDetails & id, const BSONObj & key, const DiskLoc recordLoc ) const {
- if ( key.objsize() > KeyMax ) {
- OCCASIONALLY problem() << " unindex: key too large to index, skipping " << id.indexNamespace() << endl;
- return false ;
- }
- int pos;
- bool found;
- DiskLoc loc = locate(id, thisLoc, key, Ordering::make(id.keyPattern()), pos, found, recordLoc, 1 );
- if ( found ) {
- loc.btreemod() -> delKeyAtPos(loc, id, pos, Ordering::make(id.keyPattern()));
- return true ;
- }
- return false ;
- }
在删除b树索引之后,接着就是“删除内存(或磁盘,因为mmap机制)中的记录”了,也就是之前DataFileMgr::deleteRecord()方法的下面代码:
view plaincopy to clipboardprint?
- _deleteRecord(d, ns, todelete, dl)
其定义如下:
view plaincopy to clipboardprint?
-
-
-
-
- void DataFileMgr::_deleteRecord(NamespaceDetails *d, const char *ns, Record *todelete, const DiskLoc& dl) {
-
- {
- if ( todelete->prevOfs != DiskLoc::NullOfs )
- getDur().writingInt( todelete->getPrev(dl).rec()->nextOfs ) = todelete->nextOfs;
- if ( todelete->nextOfs != DiskLoc::NullOfs )
- getDur().writingInt( todelete->getNext(dl).rec()->prevOfs ) = todelete->prevOfs;
- }
-
-
- {
- Extent *e = getDur().writing( todelete->myExtent(dl) );
- if ( e->firstRecord == dl ) {
- if ( todelete->nextOfs == DiskLoc::NullOfs )
- e->firstRecord.Null();
- else
- e->firstRecord.set(dl.a(), todelete->nextOfs);
- }
- if ( e->lastRecord == dl ) {
- if ( todelete->prevOfs == DiskLoc::NullOfs )
- e->lastRecord.Null();
- else
- e->lastRecord.set(dl.a(), todelete->prevOfs);
- }
- }
-
- {
- {
- NamespaceDetails::Stats *s = getDur().writing(&d->stats);
- s->datasize -= todelete->netLength();
- s->nrecords--;
- }
- if ( strstr(ns, ".system.indexes") ) {
-
-
-
-
-
- memset(getDur().writingPtr(todelete, todelete->lengthWithHeaders), 0, todelete->lengthWithHeaders);
- }
- else {
- DEV {
- unsigned long long *p = (unsigned long long *) todelete->data;
- *getDur().writing(p) = 0;
-
- }
- d->addDeletedRec((DeletedRecord*)todelete, dl);
- }
- }
- }
这里有一个数据结构要先解析一下,因为mongodb在删除记录时并不是真把记录从内存中remove出来,而是将该删除记录数据置空(写0或特殊数字加 以标识)同时将该记录所在地址放到一个list列表中,也就是上面代码注释中所说的“释放列表”,这样做的好就是就是如果有用户要执行插入记录操作 时,mongodb会首先从该“释放列表”中获取size合适的“已删除记录”地址返回,这种废物利用 的 方法会提升性能(避免了malloc内存操作),同时mongodb也使用了bucket size数组来定义多个大小size不同的列表,用于将要删除的记录根据其size大小放到合适的“释放列表”中(deletedList),有关该 deletedList内容,详见namespace.h文件中的注释内容。
上面代码中如果记录的ns 在索引中则进行使用memset方法重置该记录数据,否则才执行将记录添加到“释放列表”操作,如下:
view plaincopy to clipboardprint?
- void NamespaceDetails::addDeletedRec(DeletedRecord * d, DiskLoc dloc) {
- BOOST_STATIC_ASSERT( sizeof (NamespaceDetails::Extra) <= sizeof (NamespaceDetails) );
- {
- Record * r = (Record * ) getDur().writingPtr(d, sizeof (Record));
- d = & r -> asDeleted();
-
- (unsigned & ) (r -> data) = 0xeeeeeeee ;
- }
- DEBUGGING log() << " TEMP: add deleted rec " << dloc.toString() << ' ' << hex << d -> extentOfs << endl;
- if ( capped ) {
- if ( ! cappedLastDelRecLastExtent().isValid() ) {
-
- d -> nextDeleted = DiskLoc();
- if ( cappedListOfAllDeletedRecords().isNull() )
- getDur().writingDiskLoc( cappedListOfAllDeletedRecords() ) = dloc;
- else {
- DiskLoc i = cappedListOfAllDeletedRecords();
- for (; ! i.drec() -> nextDeleted.isNull(); i = i.drec() -> nextDeleted )
- ;
- i.drec() -> nextDeleted.writing() = dloc;
- }
- }
- else {
- d -> nextDeleted = cappedFirstDeletedInCurExtent();
- getDur().writingDiskLoc( cappedFirstDeletedInCurExtent() ) = dloc;
-
- }
- }
- else {
- int b = bucket(d -> lengthWithHeaders);
- DiskLoc & list = deletedList[b];
- DiskLoc oldHead = list;
- getDur().writingDiskLoc(list) = dloc;
- d -> nextDeleted = oldHead;
- }
- }
这样,就完成了将记录放到“释放列表”中的操作,上面的bucket中提供的大小款式 如下:
view plaincopy to clipboardprint?
-
-
-
-
- int bucketSizes[] = {
- 32 , 64 , 128 , 256 , 0x200 , 0x400 , 0x800 , 0x1000 , 0x2000 , 0x4000 ,
- 0x8000 , 0x10000 , 0x20000 , 0x40000 , 0x80000 , 0x100000 , 0x200000 ,
- 0x400000 , 0x800000
- };
最后,用一张时序图回顾一下删除记录时mongodb服务端代码的执行流程:
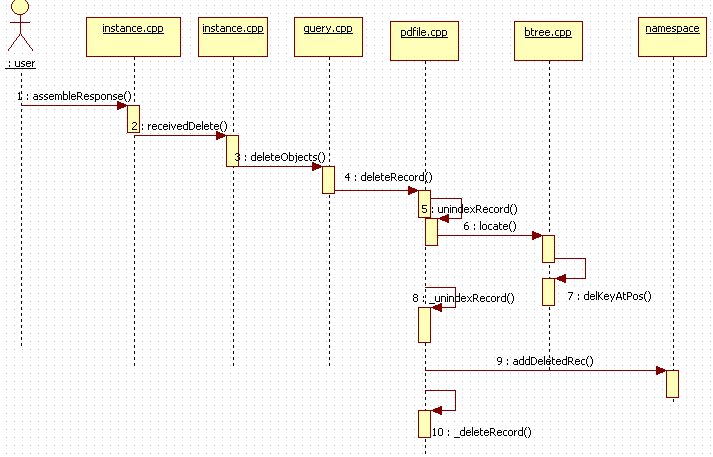
好了,今天的内容到这里就告一段落了,在接下来的文章中,将会介绍客户端发起Update操作时,Mongodb的执行流程和相应实现部分。
原文链接:http://www.cnblogs.com/daizhj/archive/2011/04/06/2006740.html
作者: daizhj, 代震军
微博: http://t.sina.com.cn/daizhj
Tags: mongodb,c++,source code


