PostgreSQL和Slony-I的安装和配置
来源:互联网 发布:域名要备案吗 编辑:程序博客网 时间:2024/05/29 07:58
随着Mysql被Sun收购,不少web开发者和架构师开始关注PostgreSQL。的确,PostgreSQL和Slony-I、PL/Proxy、Pgbouncer已经可以为我们提供一套比较完整的企业级数据库存储解决方案,其web架构如下图所示:
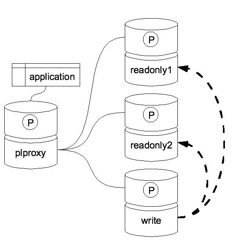
其中,PostgreSQL和PL/Proxy的安装和配置已经在上一篇Blog介绍过,下面是Slony-I 的安装配置简明指南,实现主副数据库的同步。后面我会再介绍Pgbouncer的安装和配置
1. 主副数据库机器
Master:
hostname: M_DB
inet addr:10.0.0.11
OS: Linux 2.6.9-42.ELsmp
CPU:Intel(R) Xeon(R) CPU L5320 @ 1.86GHz
MemTotal: 254772 kB
PgSQL: postgresql-8.3.0Slave:
hostname:S_DB
inet addr:10.0.0.12
OS: Linux 2.6.9-42.ELsmp
CPU:Intel(R) Xeon(R) CPU L5320 @ 1.86GHz
MemTotal: 514440 kB
PgSQL: postgresql-8.3.0#在M_DB和S_DB上安装postgresql-8.3.0, 安装和配置过程参见我的上一篇Blog,确保超级用户是postgres,数据库名是URT。
#检查M_DB和S_DB上的超级用户postgres是否可以访问对方的机器
#分别在M_DB和S_DB上执行
sudo -u postgres /home/y/pgsql/bin/createlang plpgsql URT#分别在M_DB和S_DB上的URT数据库里创建相同的表accounts。
2. 安装Slony-I
#分别在M_DB和S_DB上安装Slony-I
tar xfj slony1-1.2.13.tar.bz2
cd slony1-1.2.13
./configure –with-pgconfigdir=/home/y/pgsql/bin
gmake all
sudo gmake install3. Slony Config
创建urt_replica_init.sh文件:
##############################
#!/bin/shSLONIK=/home/y/pgsql/bin/slonik
#slonik可执行文件位置CLUSTER=URT
#你的集群的名称SET_ID=1
#你的复制集的名称MASTER=1
#主服务器IDHOST1=M_DB
#源库IP或主机名DBNAME1=URT
#需要复制的源数据库SLONY_USER=postgres
#源库数据库超级用户名SLAVE=2
#从服务器IDHOST2=S_DB
#目的库IP或主机名DBNAME2=URT
#需要复制的目的数据库PGBENCH_USER=postgres
#目的库用户名$SLONIK <<_EOF_
#这句是定义集群名
cluster name = $CLUSTER;#这两句是定义复制节点
node $MASTER admin conninfo = 'dbname=$DBNAME1 host=$HOST1 user=$SLONY_USER ';
node $SLAVE admin conninfo = 'dbname=$DBNAME2 host=$HOST2 user=$PGBENCH_USER ';#初始化集群和主节点,id从1开始,如果只有一个集群,那么肯定是1
#comment里可以写一些自己的注释,随意
init cluster ( id = $MASTER, comment = 'Primary Node' );#下面是从节点
store node ( id = $SLAVE, comment = 'Slave Node' );#配置主从两个节点的连接信息,就是告诉Slave服务器如何来访问Master服务器
#下面是主节点的连接参数
store path ( server = $MASTER, client = $SLAVE,
conninfo = 'dbname=$DBNAME1 host=$HOST1 user=$SLONY_USER ');#下面是从节点的连接参数
store path ( server = $SLAVE, client = $MASTER,
conninfo = 'dbname=$DBNAME2 host=$HOST2 user=$PGBENCH_USER ');#设置复制中角色,主节点是原始提供者,从节点是接受者
store listen ( origin = $MASTER, provider = 1, receiver = 2 );
store listen ( origin = $SLAVE, provider = 2, receiver = 1 );#创建一个复制集,id也是从1开始
create set ( id = $SET_ID, origin = $MASTER, comment = 'All pgbench tables' );#向自己的复制集种添加表,每个需要复制的表添加一条set命令,id从1开始,逐次递加,步进为1;
#fully qualified name是表的全称:模式名.表名
#这里的复制集id需要和前面创建的复制集id一致
set add table ( set id = $SET_ID, origin = $MASTER,
id = 1, fully qualified name = 'public.accounts',
comment = 'Table accounts' );_EOF_
#########################在M_DB或者S_DB上执行
./urt_replica_init.sh4. Slony Start
创建Master.slon文件:
########################
cluster_name="URT"
conn_info="dbname=URT host=M_DB user=postgres"
########################创建Slave.slon文件:
########################
cluster_name="URT"
conn_info="dbname=URT host=S_DB user=postgres"
#########################在M_DB上执行
/home/y/pgsql/bin/slon -f master.slon >> master.log &#在S_DB上执行
/home/y/pgsql/bin/slon -f slave.slon >> slave.log &5. Slony Subscribe
创建urt_replica_subscribe.sh文件:
########################
#!/bin/shSLONIK=/home/y/pgsql/bin/slonik
#slonik可执行文件位置CLUSTER=URT
#你的集群的名称SET_ID=1
#你的复制集的名称MASTER=1
#主服务器IDHOST1=M_DB
#源库IP或主机名DBNAME1=URT
#需要复制的源数据库SLONY_USER=postgres
#源库数据库超级用户名SLAVE=2
#从服务器IDHOST2=S_DB
#目的库IP或主机名DBNAME2=URT
#需要复制的目的数据库PGBENCH_USER=postgres
#目的库用户名$SLONIK <<_EOF_
#这句是定义集群名
cluster name = $CLUSTER;#这两句是定义复制节点
node $MASTER admin conninfo = 'dbname=$DBNAME1 host=$HOST1 user=$SLONY_USER';
node $SLAVE admin conninfo = 'dbname=$DBNAME2 host=$HOST2 user=$PGBENCH_USER ';#提交复制集
subscribe set ( id = $SET_ID, provider = $MASTER, receiver = $SLAVE, forward = no);
_EOF_
#########################在M_DB或者S_DB上执行
./urt_replica_subscribe.sh6. 测试
修改M_DB上URT数据里的accounts表,S_DB上的accounts表也会随之改变下图是Slony-I内部架构,可以看到Slony-I用到了很多线程来实现事件和数据的传递和分发。
- PostgreSQL和Slony-I的安装和配置
- PostgreSQL和Slony-I的安装和配置
- [转]PostgreSQL数据库同步Slony-I的安装和配置
- 10分钟搞定,slony的安装和配置
- Linux下的 Postgresql的slony-i的数据同步配置
- PostgreSQL数据库集群:Slony-I
- PostgreSQL数据库集群:Slony-I
- Slony-I for Win2003的配置文档
- Slony-I for Win的配置文档
- PostgreSQL:PostgreSQL的安装和配置
- Postgresql安装和配置
- Slony-I 2.1.0 同步postgreSQL
- pg中slony-i的数据同步配置
- slony I 数据复制工具的安装与应用
- Ubuntu 安装和配置postgresql
- Ubuntu PostgreSQL安装和配置
- Ubuntu PostgreSQL安装和配置
- 利用Slony进行Postgresql集群的研究
- linux_samba服务在RHEL下的配置
- Microsoft Active Directory 常用文档速查指南
- [学习]创建一个Android工程
- 纯粹发牢骚~~
- 虚拟实验室RTEMS开发环境的配置(Windows)
- PostgreSQL和Slony-I的安装和配置
- 关于运行库安全策略的一些资料
- 程序人生--一个程序员对学弟学妹建议
- j2me学习三_LCDui类学习(2)
- MPI通信的启动时间测试
- postgresql高可用方案
- 命令层监视器编写步骤
- BeginPaint和GetDC的区别
- 程序员五大层次,你属于哪一层?


