Nutch 中文分词 庖丁分词组件
来源:互联网 发布:淘宝货到付款交易成功 编辑:程序博客网 时间:2024/05/01 05:13
1 中文分词介绍
目前,Nutch中文分词方式大致有两种方式:
一是修改源代码。这种方式是直接对Nutch分词处理类进行修改,调用已写好的一些分词组件进行分词。
二是编写分词插件。这种方式是按照Nutch定义的插件编写规则重新编写或者添加中文分词插件。
以上两种方式都是可取的。目前,由于开源社区的活跃,已经有很多种分词组件的出现,无论是修改源代码的方式还是编写分词插件的方式,都是依赖于这些分词组件的。下面列出了主要的一些分词组件:
1、CJKAnalyzer
Lucene自带的一种中日韩分词器。
2、ChineseAnalyzer
Lucene自带的对中文的分词器
3、IK_CAnalyzer(MIK_CAnalyzer)
一种基于词典的分词器,Lucene自带,相对而言较简单。
4、Paoding分词
比较有名的庖丁解牛分词组件,效率高分词速度快,分词准确度高。
5、JE分词
网友编写的分词组件,性能也不错。
6、ICTCLAS
中科院的一组分词工具,其中有开源的也有收费版本,他基于HMM模型。主要的几个如下:
ICTCLAS_OpenSrc_C_windows、ICTCLAS_OpenSrc_C_Linux为中科院计算所张华平和刘群老师研制。
SharpICTCLAS为.net平台下的ICTCLAS,是由河北理工大学经管学院吕震宇根据Free版ICTCLAS改编而成,并对原有代码做了部分重写与调整。
ictclas4j中文分词系统是sinboy在中科院张华平和刘群老师的研制的FreeICTCLAS的基础上完成的一个java开源分词项目,简化了原分词程序的复杂度,旨在为广大的中文分词爱好者一个更好的学习机会。
imdict-chinese-analyzer是 imdict智能词典的智能中文分词模块,作者高小平,算法基于隐马尔科夫模型(Hidden Markov Model, HMM),是中国科学院计算技术研究所的ictclas中文分词程序的重新实现(基于Java),可以直接为lucene搜索引擎提供中文分词支持。
2 分词结构分析
在进行实验之前需要对Nutch分词结构进行分析。本文仔细研究了一下Nutch的org.apache.nutch.anlysis包,其中大多的类都是与Nutch在爬行网页时候对网页中的文本分词解析相关的。
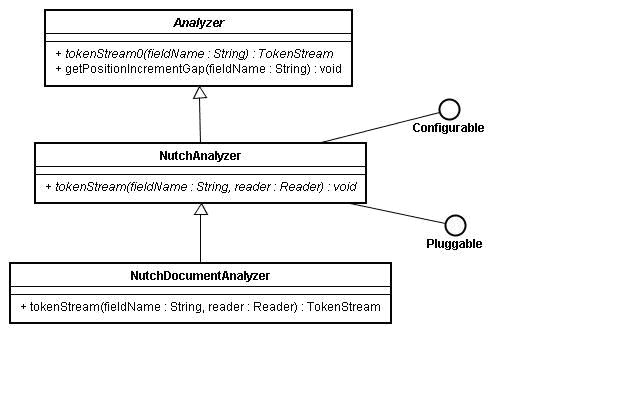
Nutch分词的最底层使用的是lucene的Analyzer抽象类,它位于org.apache.lucene.analysis包中,NutchAnalyzer继承了Analyzer类、实现了Configurable、Pluggable接口,该抽象类中定义了一个公有的抽象方法tokenStream(String fieldName, Reader reader)返回的类型是TokenStream。该方法是用于分析文本,其后的具体类中在这个方法中实现了从文本中提取索引词组的策略、算法。而返回的TokenStream类是即可以从文本或者从查询词组中枚举token序列的抽象类,在Lucene中继承了它的具体类有Tokenizer、TokenFilter。
NutchAnalyzer类是Nutch中扩展分析文本的扩展点,所有用于解析文本的插件都得实现这个扩展点。对于Analyzer一个典型的扩展就是首先建立一个Tokenizer(org.apache.lucene.analysis.Tokenizer),它是用于将Reader中读入的Stream分解成最原始的词组(Token---org.apache.lucene.analysis.Token),在Tokenzier分解Stream之后,一个或多个TokenFilter会用于过滤这些词组中无意义的词组。
NutchDocumentAnalyzer类继承了NutchAnalyzer,其中有三个静态私有内部类ContentAnalyzer、AnchorFilter、AnchorAnalyzer 它们分别继承了Analyzer(org.apache.lucene.analysis.Analyzer)、 TokenFilter(org.apache.lucene.analysis.TokenFilter)、Analyzer(org.apache.lucene.analysis.Analyzer)。在ContentAnalyzer中调用了CommonGrams类(org.apache.nutch.analysis),该类构建了一个n-grams的分词方案,因为需要在索引中考虑词组的出现频率,并且实现了对n-grams方案词组查询的优化措施。在n-grams方案中单个的词组同样会被该方案索引,索引期间大量使用了Token(org.apache.lucene.analysis.Token)的各种方法,并且还会调用nutch/conf/nutch-default.xml中analysis.common.terms.file的配置属性。
其上各个类与接口的uml图如下:
3 实验过程
本次实验选择了paoding分词组件和imdict-chinese-analyzer作为实验工具。
3.1 paoding plugin
以下是paoding分词组件的实验:
1、实验准备
下载paoding分词组件(下载地址:http://code.google.com/p/paoding/)将下载下的文件paoding-analysis-2.0.4-beta.zip解压,得到paoding-analysis.jar。
本次实验假设Nutch已配置好。
2、在./src/plugin下面新建一个目录:analysis-zh作为分词组件包;新建一个目录lib-paoding-analyzers存放paoding-analysis.jar。
3、在analysis-zh包中建立两个文件一个文件夹,分别为:
(1)build.xml
(2)plugin.xml
(3)src/java文件夹,里面新建一个包:org/apache/nutch/analysis/zh(依次逐层建立这些文件夹),在该包内新建文件PaodingAnalyzer.java:
4. 在lib-paoding-analyzers文件夹下建立如下文件:
(1)build.xml:
(2)plugin.xml:
(3)新建一个lib文件夹,将paoding-analysis.jar放入其中。
5.修改nutch/conf/nutch-site.xml,加上如下内容,作用是让nutch能加载到我们即将生成的analysis-zh.jar包。
<property>
<name>plugin.includes</name>
<value>protocol-http|urlfilter-regex|parse-(text|html|js)|analysis-(zh)|index-basic|query-(basic|site|url)|summary-basic|scoring-opic|urlnormalizer-(pass|regex|basic)</value>
<description>
</description>
</property>
6.修改org.apache.nutch.analysis.NutchDocumentAnalyzer,在目录src/java/org/apache/nutch/analysis/目录下
(1)在 private static Analyzer CONTENT_ANALYZER; 后加上 private static Analyzer PAODING_ANALYZER;
(2)把下面代码
改为
(3)把代码
改为:
(4)在该文件顶部的import区域加上下面语句导入paoding包
import net.paoding.analysis.analyzer.PaodingAnalyzer;
7.修改NutchAnalysis.jj
把130行的|<SIGRAM: <CJK> >修改成|<SIGRAM: (<CJK>)+ >
8.修改org.apache.nutch.indexer.lucene.LuceneWriter,在目录nutch/src/java/org/apache/nutch/indexer/lucene
把代码
修改为
上面的代码只是设置了默认的语言为ch,加了几行代码,对其它代码没有修改
9.修改org.apache.nutch.analysis.NutchAnalysis,添加如下方法:
修改55行的public static Query parseQuery(){}方法
public static Query parseQuery(String queryString, Configuration conf) throws IOException {
return parseQuery(queryString, null, conf);
}
为:
10.修改Nutch的build.xml文件,在 <target name="war" depends="jar,compile,generate-docs"></target>的<lib></lib>里加上<include name="paoding-analysis.jar"/>;
修改150行处的<targe tname="job" depends="compile">,改为<target name="job" depends="compile,war">这样编译后能自动在bulid文件夹下生成nutch-1.2.job,nutch-1.2.war,nutch-1.2.jar文件了。
11.修改nutch-1.0/src/plugin下的build.xml文件,加上
<targetname="deploy">
<ant dir="analysis-zh" target="deploy"/>
<ant dir="lib-paoding-analyzers" target="deploy"/>
.......
</target>
<targetname="clean">
<ant dir="analysis-zh" target="clean"/>
<ant dir="lib-paoding-analyzers" target="clean"/>
.......
</target>
参考:
1.Nutch 分词 中文分词 paoding 疱丁
http://blog.csdn.net/mutou12456/archive/2010/04/01/5439935.aspx
2.nutch 1.2添加中文分词插件
http://www.mikkoo.info/?p=93
3. Nutch中文分词 JE
http://blog.csdn.net/oprah_7/archive/2011/03/09/6234296.aspx
4.nutch1.2添加中文分词
http://www.hadoopor.com/thread-2805-1-1.html
5.nutch1.2 paoding分词 dic词库路径问题
http://hi.baidu.com/oliverwinner/blog/item/cc8a22f1b0666706b17ec53e.html
- Nutch 中文分词 庖丁分词组件
- nutch中文分词
- nutch +中文分词
- nutch-1.0中文分词
- 庖丁中文分词出现的问题
- Nutch 分词 中文分词 paoding 疱丁
- 让Nutch支持中文分词
- 让Nutch支持中文分词
- nutch中文分词,改源码
- Nutch中文分词(庖丁解牛)
- nutch添加中文分词器
- 中文分词组件
- scws中文分词组件
- scws中文分词组件
- scws中文分词组件
- scws中文分词组件
- scws中文分词组件
- scws中文分词组件
- C#开发读取Geodatabase10的XML值
- 再次回到这儿
- 在决定使用ClickOnce发布你的软件前,应该知道的一些事情(一些常见问题解决方法)
- 浅谈QT中窗口刷新事件
- Lcr-1
- Nutch 中文分词 庖丁分词组件
- struts2在前台通过property获取属性值某些字符转义问题
- asp.net的Request.QueryString乱码
- STM32定时器的输入滤波机制
- XL C/C++ 输入和输出文件
- 英特尔在2011台北国际电脑展
- 用户的$home/.dmrc已被忽略,这将无法保存 默认会话和语言
- ROM ,RAM ,DRAM ,SRAM ,FLASH
- 优秀设计团队必需的四种成员


