Nutch 评分机制分析
来源:互联网 发布:淘宝买家等级有什么用 编辑:程序博客网 时间:2024/06/05 01:54
Nutch构建于Lucene之上,可以通过学习Lucene的评分机制来了解Nutch评分。
Lucene的打分公式可以在Lucene的Similarity类中看到。详见文档Lucene Similarity Javadoc.
大体上:
查询结果集中一个特定文档的得分score(q,d),是查询中每一个词项的得分之和(t in q);
一个词项对于一个文档的得分,是该词项在文档不同的域field(url、title、content)的得分之和;
对于每一个域,词项得分是下列因素的乘积:tf、idf、index-time boost、lengthNorm、queyrNorm
我怎么影响Nutch评分?
评分用过滤插件实现,比如一个评分过滤类:OPIC Scoring。
然而,最简单的影响评分的方式是修改查询时boosts的值(通过修改nutch-site.xml实现)。这些boosts的默认值保存在nutch-default.xml文件中,为
query.url.boost, 4.0f
query.anchor.boost, 2.0f
query.title.boost, 1.5f
query.host.boost, 2.0f
query.phrase.boost, 1.0f
由此看出,URL中的词项有着最高的权重,锚文本、标题、主机、短语依次降低。
译自Nutch维基
***************************************************************************************
Lucene的文档得分计算
在Lucene的Similarity类中,详见文档Lucene Similarity Javadoc.
文档的得分是在用户进行检索时实时计算出来的。
Lucene的打分公式: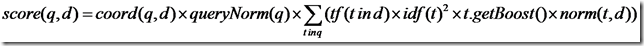
在推导之前,先逐个介绍每部分的意义:
- q: 查询
- d: 文档
- t: Term,一个查询包含1个或多个词项,这里的Term是指包含域信息的Term,也即title:hello和content:hello是不同的Term
- coord(q,d):一次搜索可能包含多个词项,而一篇文档中也可能包含多个搜索词。此项表示,当一篇文档中包含的搜索词越多,则此文档则打分越高。
- queryNorm(q):计算每个查询条目的方差和,此值并不影响排序,而仅仅使得不同的query之间的分数可以比较。其公式如下:
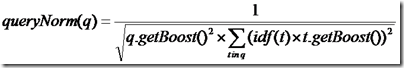
- tf(t in d):Term t在文档d中出现的词频
- idf(t):Term t在几篇文档中出现过
- norm(t, d):标准化因子,它包括三个参数:
- Document boost:此值越大,说明此文档越重要。
- Field boost:此域越大,说明此域越重要。
- lengthNorm(field) = (1.0 / Math.sqrt(numTerms)):一个域中包含的Term总数越多,也即文档越长,此值越小,文档越短,此值越大。

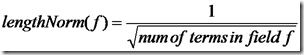
各类Boost值
- t.getBoost():查询语句中每个词的权重,可以在查询中设定某个词更加重要,common^4 hello
- d.getBoost():文档权重,在索引阶段写入nrm文件,表明某些文档比其他文档更重要。 (PageRank值设置?)
- f.getBoost():域的权重,在索引阶段写入nrm文件,表明某些域比其他的域更重要。
以上在Lucene的文档中已经详细提到,并在很多文章中也被阐述过,如何调整上面的各部分,以影响文档的打分,请参考有关Lucene的问题(4):影响Lucene对文档打分的四种方式一文。
Lucene评分机制的数学推导
*********************************************************************************
通过Searcher.explain(Query query, int doc)方法可以查看某个文档的得分的具体构成。
在Lucene中score简单说是由 tf * idf * boost * lengthNorm计算得出的。
tf:是查询的词在文档中出现的次数的平方根
idf:表示反转文档频率,观察了一下所有的文档都一样,所以那就没什么用处,不会起什么决定作用。
boost:激励因子,可以通过setBoost方法设置,需要说明的通过field和doc都可以设置,所设置的值会同时起作用
lengthNorm:是由搜索的field的长度决定了,越长文档的分值越低。
所以我们编程能够控制score的就是设置boost值。
还有个问题,为什么一次查询后最大的分值总是1.0呢?
因为Lucene会把计算后,最大分值超过1.0的分值作为分母,其他的文档的分值都除以这个最大值,计算出最终的得分。
Lucene的评分(score)机制的简单解释
*********************************************************************************
文档的得分是在用户进行检索时实时计算出来的,与查询相关。
Lucene用于计算某个关键字在对应于某文档的得分公式:

初始化Document后,使用了Document的setBoost方法来改变一下文档的boost因子。根据文档Lucene评分机制的数学推导 中norm(t,d)的计算公式可知,最终的得分将会乘以这个因子。
Lucene评分算法
*********************************************************************************
参考资料:
Nutch维基
Lucene评分机制的数学推导 该文档还有对向量空间模型的介绍,各个公式的推导很不错
Lucene的评分(score)机制的简单解释 有个程序例子, Searcher.explain(Query query, int doc)方法输出得分计算过程
Lucene评分算法 有个程序例子,利用setBoost方法,改变boost值
Lucene Similarity Javadoc 官方相似度计算公式的介绍
- Nutch 评分机制分析
- Nutch插件机制分析
- Nutch插件机制分析
- Nutch 1.3 学习笔记 11-1 页面评分机制 OPIC
- Nutch 1.3 学习笔记 11-1 页面评分机制 OPIC
- Nutch 1.3 学习笔记 11-2 页面评分机制 LinkRank 介绍
- Nutch 1.3 学习笔记 11-2 页面评分机制 LinkRank 介绍
- Nutch/Lucene的存取机制与结构分析
- Nutch/Lucene的存取机制与结构分析(收藏)
- Nutch 1.3 学习笔记 10-3 插件机制分析
- Nutch 1.3 学习笔记 10-3 插件机制分析
- [Nutch]Nutch抓取过程分析
- Lucene:评分机制
- Lucene的评分机制
- Lucene Scoring 评分机制
- Lucene Scoring 评分机制
- Lucene Scoring 评分机制
- Lucene的评分机制
- 一个IT人的奋斗历程 (和迷茫的朋友共勉) !!!
- Linux源码安装mysql 5.5.13 (cmake编译)
- myeclipse5.5添加webservice客户端报错 error generating services myeclipse5.5 tomcat6 jdk1.5
- 今天很累,根本不想写代码
- C#正则表达式整理
- Nutch 评分机制分析
- 在MTK项目中试用分布式编译系统IncrediBuild
- VC 创建拨号连接A
- T树的C++源码实现
- windows下eclipse中,涉及源码编译的apk开发使用系统签名机制
- 关于MFC Sockets编程
- 区分Activity的四种加载模式
- 隐马尔科夫模型C#类库调用示例
- 如何选择开源许可证


