数据仓库中两种数据模型的分析比较
来源:互联网 发布:最好的监控软件 编辑:程序博客网 时间:2024/05/18 01:34
来源:http://articles.e-works.net.cn/bi/article73172.htm
发表时间:2009-11-7 何秉姣 来源:万方数据
数据仓库(DH)和联机分析处理(OLAP)是商业数据处理领域中的2个重大的新技术。OLAP为用户向数据仓库中的数据提出复杂查询、提供快速、稳定的响应。DH是支持决策的分析型的数据库,它采集、组织和存储来自地理分布、构造各异的信息源数据。数据模型是数据库系统的核心和基础。本文针对支持OLAP的数据仓库的数据模型进行研究。 1 几个重要的概念 被数据仓库组织的数据是非常复杂的,除少数通用的结构规整的基本数据外,大多数数据具有多维本质特性。例如,A销售系统在B地区的C产品年总销售量Q,就是一个基于时间、地点和产品等多个因素有关的数据,有的数据可能涉及更多的因素。这里的时间、地区和产品就是数据仓库中的维,维是一个物理特性,是访问和表达商务信息的一个基本途径,维一般作为识别数据的索引。属性是在一个维内为了提供详细分类系统而定义的,是为了判别和区分特定数据而定义的,如在时间维内有年、月、日等属性。度是在维空间衡量商务信息的一种方法,它一般包括:以一个标准为基准,通过比较所得到的数量、容量或资金,如销售量Q,这些数据用于对商务行为进行定量衡量。 1.1 维 (1)维的种类 在数据仓库中根据维在各层次的取值中是否包含空间对象,可以将维分为3种:①非空间维,只包含非空间数据的维,其泛化值也是非空间的。例如时间维,它在每个层次上(年、月、日等)的取值都只包含非空间的数据。②空间——非空间维。在原始概念层次上是空间数据,但其泛化值在较高的层次上就变成非空间的数据。例如,在某大型零售送奶公司中,各个客户在地图上的分布是用空间数据来表达的,而这些客户数据可以被泛化为一些非空间的值,比如泛化为某个子送奶公司的客户,其更高层次的泛化值则全部变为非空间的数据。这种类型的维与非空间维所起的作用类似。③空间——空间维。原始概念层次及其所有高层次的泛化数据都是空间数据。例如,各个客户的详细分布情况及其泛化数据,如各个客户在小区的分布、在邮政编码区域的分布,以及在各个行政区的分布等都是空间数据。 (2)生成维的方式 ①根据属性间的关系或特定数据值之间的关系,由专家或用户指定。②利用数据分析技术(诸如聚类、分类或统计分析等)自动生成。③将经过计算的度量作为数据仓库中的一维使用,即将销售奶量度转化为销售奶量维。 1.2 度 在数据仓库中可建立两种类型的度量:第一种是数值型度量,它仅包含数值型数据的度量。例如,在送奶数据仓库中,某个城区的月收入就可作为一个度最。第二种是空间度量,它包含空间数据的度量,是指向空间对象的指针集合。例如在送奶数据仓库中,月收入相同的城区可以作为一个度量。信息世界中的概念模型就是由维和度组成的,在数据世界中的数据模型的就是如何很好地描述概念模型中的维和度。 2 数据仓库中的数据模型 立方体数据模型(cube)和星型数据模型都能组织数据仓库的维和度数据,为OLAP提供支持,但它们各有一定的局限性,在数据库开发中应该有机结合两种数据模型,合理使用。 2.1 立方体数据模型和星型数据模型 (1)立方体数据模型 立方体模型是数据仓库的基本结构。在该模型中,一部分是数字测量值(如销售量、投资额、收入等),它们依赖于一组维,而所有维提供了全部测量值的上下文关系。例如销售量Q与销售地区、销售产品和销售时间等有关,这些相关的“维”惟一决定了销售量Q这个测量值。因此,多数数据视图就可以表示为在这些由不同层次的维构成的多维空间中存放数字测量值。如图1中的小立方体格(即cube单元格)内存储的数据,就是可口可乐等产品的销售量Q数据。 (2)星型数据模型 大多数数据仓库都采用“星型架构”来表示多维概念模型。采用星型模型的数据库中至少包括一张“事实表”。“事实表”中的每条记录都包含有指向各个“维表”的外键和一些相应的测量数据,即数据值。对于每一维都有一张“维素”。“维表”中记录的是有关这一维的属性,如图2所示。 2.2 比较立方体数据模型和星型数据模型 (1)星型架构中有2个基本类型的表:维表和事实表。维表的主关键字是事实表中的外部关键字、每一个表都很好地包括了多维概念数据模型中的维、度及属性。维表是立方体数据模型的维,事实表的数据值是立方体数据模型中的单元。 (2)对OLAP的支持能力,其对比解释见表1。从表1可知,2种模型都能支持OLAP的一般操作。 (4)从Cube的定义和图1可知道Cube和Cube单元的结构很规整。它是在数据仓库中概念化数据的一种公共模型,通常被作为主要的逻辑层结构用来描述多维数据库,为决策者提供了一个理想的环境。也正是Cube的规整性,使Cube存在致命的缺陷,即在Cube中无论是否包含数据,都会形成单元,结果产生很多单元都是空单元,造成大量的空间浪费,如特定的月份,经销商并没有销售其经营的商品,则就不会产生相应的记录、对于稀疏的立方体数据模型,要求有一些数据结构方面的知识,来预测将在哪些单元内产生数据。星型架构则克服了立方体数据模型中存在的许多不足之处。在相同的维数下,星型架构占据的空间明显少于立方体数据模型占据的空间,即星型数据模型只在需要记录事实的时候才产生一个事实记录。对稀疏的星型架构就没有预测的要求。 星型模型是扩展了的关系表格结构,该模型通过包含主题的事实表和多个包含事实的非正规化的维度表来执行典型的决策支持查询。一旦创建了事实表,就可以使用OLAP工具预先分析常用的访问信息。星型架构能很好地支持OLAP组织汇总数据的立方体,再现数据的多维特性,高效率地执行分析性查询语句。从图3可以看出,每张维度表是各不相同的,其好处是能量体裁衣地为不同的维分配空间,从而节省空间,但也同时大大增加了开发和维护数据仓库的负担,没有充分考虑实体的规整性。 另外,为了能够使系统更好地工作,在采用星型数据模型时,应该考虑下列因素:尽可能地使用星型架构、为用户设计维度表、维度表的设计一定要符合通常意义上的范式约束、同一种数据尽可能地使用一个事实表、对每一个关键字段创建一个索引,这样可以提高查询语句的性能,对每一个维度表,在其关键字列上创建一个索引、对于每一个事实表,在其包含维度表的外键列的组合列上创建一个索引,系统使用这些索引加载多维数据结构和汇总数据,可以显著提高立方体查询处理的性能,确保数据的参考完整性。 通过分析可见,立方体数据模型运用表达结构有规整性的实体或维数较少的系统,构造数据仓库的基本数据结构,这限制了Cube在许多应用环境中的推广使用,否则就采用星型数据模型给予设计。 Cube模型和星型模型的优缺点正好互补。基于此,在实际开发数据仓库时,应该成分发挥两者的优势,即用星型模型描述数据仓库中的复杂多维数据,而Cube模型描述简单通用规整的数据。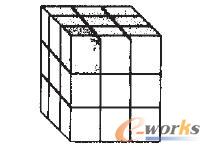
图1 一个销售立方体数据模型
图1表示了一个销售立方体模型,图中阴影部分就是2001年广州市销售可口可乐的销售量Q。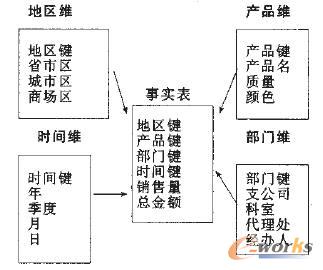
图2 销售数据仓库的星型数据模型
图2表示了销售数据仓库的星型数据模型,它包含4个维:地区维、时间维、产品维和部门维。它们各由相关的属性组成,这些属性有时也被认为是维的层次。如图3表示了销售数据仓库各个维的概念层次结构。中间是事实表,它由各维度的主键和数据仓库的度构成。度数据在事实表中维护,维度数据在维度表中维护。
图3 销售数据仓库中各个维的概念层次结构
在星型架构中,将单维的维表与另一个维表联接,这样就构成了关系数据库中的多维分析空间。这些平面的表被叠加到一起,构成了一个多维空间。叠加的核心是事实表。维表关键字是事实表关键字的一个组成部分,数据仓库中的关键字应使用系统生成的代理关键字,而不是直接使用操作型数据库的关键字,这是由数据仓库的稳定性所决定的。虽然看起来使用操作环境的关键字作为数据仓库的关键字显得简单、易懂,但实际上它会使数据仓库管理复杂化。首先,操作环境里的关键字的任何变化都会导致数据仓库里相应的变化,这违反了数据仓库稳定的特性。同时,数据仓库的扩展,必须保证在不破坏关键字的前提下,来自其他系统的数据能够顺利合并到数据仓库中去。
表1 2种数据模型的比较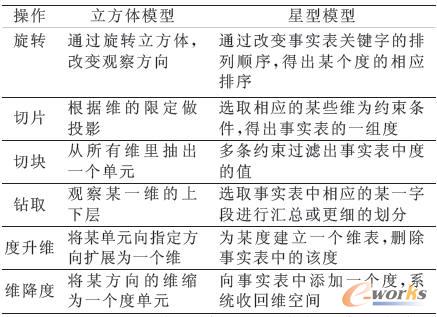
(3)对业务决策者来说,星型数据模型中令人感兴趣的部分是事实表,这就是数据所处的区域。为了访问事实表中的数据值,必须通过维,必须通过确定维才能实现。立方体数据模型和星型数据模型的维是进入点、当进行立方体数据模型的处理时,通过详细说明维的数据(坐标)访问单元。类似的,通过维#我们定义了事实表中令人感兴趣的一些字段。事实表记录业务的行为,而任何处理均从维开始。一个人可以将维表想象为大门,业务决策者由此进入一个包含了事实的房间,也就是事实表。
- 数据仓库中两种数据模型的分析比较
- Java中比较常用的两种数据转化
- 两种数据文件offline的比较
- 数据仓库中的三种数据库模型
- 数据仓库中的几种数据模型
- Ajax中XML和json两种数据格式的使用和比较
- XML和JSON两种数据交换格式的比较
- XML和JSON两种数据交换格式的比较
- XML和JSON两种数据交换格式的比较
- XML和JSON两种数据交换格式的比较
- XML和JSON两种数据交换格式的比较
- XML和JSON两种数据交换格式的比较
- XML和JSON两种数据交换格式的比较
- XML和JSON两种数据交换格式的比较
- XML和JSON两种数据交换格式的比较
- XML和JSON两种数据交换格式的比较
- XML和JSON两种数据交换格式的比较
- XML和JSON两种数据交换格式的比较
- VC++ MFC DLL动态链接库编写详解
- C# winform 第三方播放器COM组件,可播放任意格式视频....
- 网络重启
- asp.net常用指南
- C++拷贝构造函数(深拷贝,浅拷贝)
- 数据仓库中两种数据模型的分析比较
- 在驱动和应用程序间共享内存
- 为什么要选用开发平台
- 远程连接sql server 2000服务器的解决方案
- 检索COM 类工厂中CLSID 为 {00024500-0000-0000-C000-000000000046}的组件时失败
- 通过mod_deflate进行HTTP文本压缩
- webconfig 数据库连接方式
- 常见的十四种Java开发工具的特点
- AS2.0解析XML


