BW基本概念及术语
来源:互联网 发布:编辑linux启动顺序 编辑:程序博客网 时间:2024/06/06 19:26
标准星型模型(Classic Star Schema)
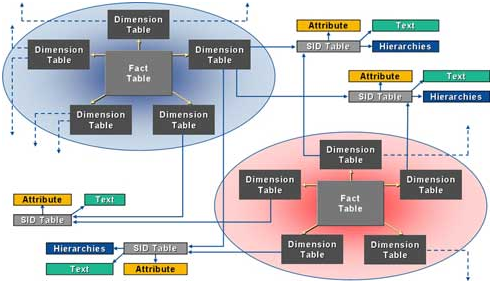
标准星型模型是数据仓库中一种常用的组织信息和数据的多维数据模型。它由中心的一个事实表(Fact Table)和一些围绕它的维度表(Dimensional Table)组成。
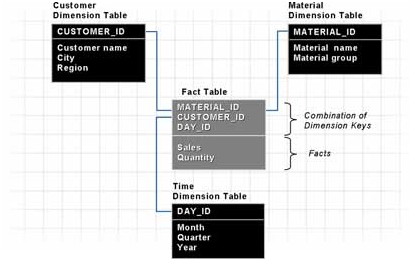
事实(Fact)着眼于商业活动中的分析数据,通常回答诸如这个产品多贵?卖了多少?之类的问题。事实数据存储在事实表里面。事实表可以分为两部分:一部分是指向所有维度表主键的外键字段,另一部分是度量字段(通常叫做Measure,BW中叫做Key Figure)。
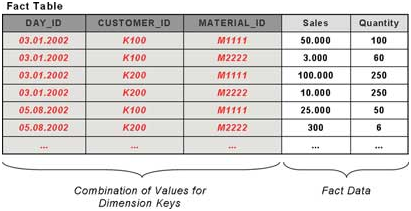
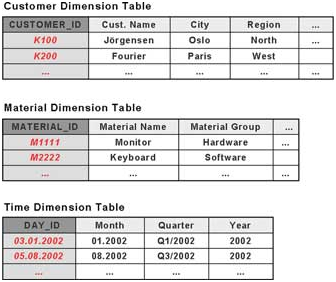
维度(Dimension)是对商业活动某个考察角度的文字性描述,通常回答诸如谁?买了什么东西?什么时候?在哪里?之类的问题。维度数据存储在维度表里面。维度表也可以分为两部分:一部分是作为主键的ID,另一部分是该维度的一组特征字段(Characteristics)。例如顾客维度包含了唯一的顾客ID,顾客的姓名,居住城市,所在区域等。
SAP BW星型模型
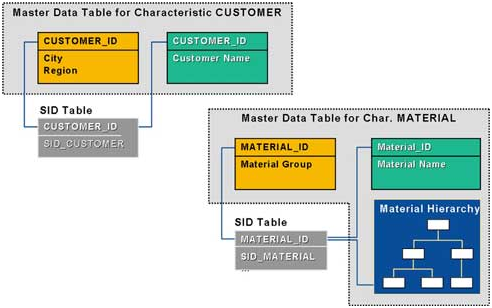
SAP在标准星型模型基础上做了一些改进,将维度表中的主数据(Master Data)分离出去,独立建表,并通过SID Table和维度表关联起来。SAP将主数据分为3类:属性(Attributes),文字描述(Text),层级结构(Hierarchy)。以Material维度为例,材料的名字放入text 表中,材料所属的类别放入attributes表中,材料的层级信息放入hierarchy表中。
事实表和与之相关联的维度表构建了BW分析的核心模型InfoCube. InfoCube是一个独立完整的数据集,从多个维度描述了一个商业应用。
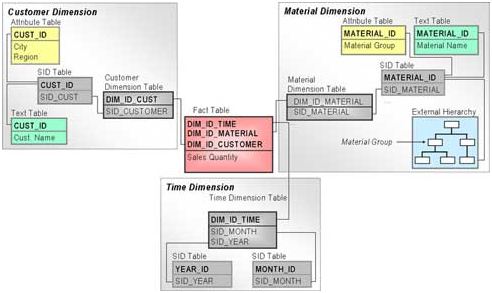
这里需要注意的是Master Data 并不是InfoCube的一部分,因此Master Data可以在多个InfoCube中共享。这是BW将Master Data从维度表分离出来的主要原因之一。我们知道MOLAP数据仓库为了提高Aggregation的效率,需要事先把这些Aggregation的值计算好,而不是在每次请求的时候才计算。这些预先计算好的Aggregation值当然也需要以cube的形式保存起来。如果是用标准星型模型,那么有两种方法来存储:一种是将Aggregation值和facts一起保存在原始cube的事实表中,这样事实表就会更加庞大,查询效率肯定不高。另一种是为不同的Aggregation建立独立的aggregation cube,存在这些写新的cube中,但这样会造成维度表的冗余,每个aggregation cube都会重复一份它所需要的维度表中的所有信息。现在BW将Master Data从维度表分离出来使得维度表变成一张简单的关系表,就解决了Master Data的冗余问题。同时由于Master Data不是和维度表绑在一起而是通过SID Table查询得到,使得多语言支持非常方便。可以为每种语言建立独立的主数据表并根据查询时的语言信息动态绑定到不同语言的主数据表。
- BW基本概念及术语
- Ice基本概念及术语
- 3--oracle基本概念及术语
- zigbee基本概念及协议术语
- 常见的术语及基本概念
- SAP BW 术语
- BW术语表
- SAP BW 术语表
- 集群的基本概念及相关术语
- SAP BW中的基本概念
- 数据库跟丽军学 之一 数据库的基本概念及术语
- LVM 学习总结(一)——基本概念及术语
- 数据结构-基本概念和术语
- oracle基本概念和术语
- oracle基本概念和术语
- oracle基本概念和术语
- Oracle基本概念和术语
- Oracle基本概念/术语
- 一个压力测试U盘读写的一个bat档案
- 编写ATL工程实现ActiveX控件调用cryptoAPI接口(一)------------签名与验证
- 表驱动分为三种,分别是:直接索引、索引表、阶梯索引
- 解题笔记(1)——子数组之和的最大值
- C++内联函数(Inline)
- BW基本概念及术语
- 单例模式
- 囧,安装版的android SDK出现的找不到JRE的bug……
- var_dump
- 简单的PWM定时器驱动
- dbcplugin.conf
- 第一次自己回家..
- 第一次开门
- 用ftp一直put文件到ftp server的压力测试的bat档案的编写


