空洞文件的感想
来源:互联网 发布:富士通单片机官网 编辑:程序博客网 时间:2024/04/28 09:42
问题源于写一个类似与cp的程序,复制一个具有空洞的文件,但不将字节0写导输出文件中去(APUE 第4章6题)。
我们知道空洞是不占用磁盘空间的,且linux系统自己有cat,cp命令可以复制文件,但是对空洞的处理方式不同:
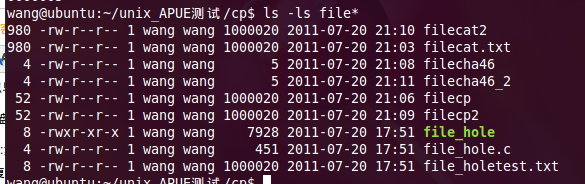
cat file> file _copy :复制输出的文件将使空洞全填为字符0,文件实际大小和原空洞文件大小一致,但是空洞部分化为字符0占用磁盘空间;
cp file file_copy : 复制输出的文件不填平空洞,文件实际大小和原空洞文件大小一致,空洞部分仍是空洞,不占用磁盘空间;
./a.out file file_copy:自己写的要求的程序,文件实际大小为除去空洞‘\0’的大小,带来的问题就是源文件中的有些‘\0’并不是空洞,也被当作空洞跳过;
处理方法为:复制时,增加 “比较文件大小与占用磁盘大小”
同时,在查看磁盘大小时,使用命令du -h file ;它显示的是该文件系统所占的磁盘大小。我们必须知道,在linux的文件系统中,磁盘的最小物理单元为簇,每次创建一个文件则为该文件系统分配一个簇或这簇的倍数(即使文件大小不足以占用满一簇,该簇空余的磁盘存储仍旧是该文件的),在我自己的电脑里,系统为文件分配的簇为4KB.
说明
1.空洞文件(文件的大小要求大于一个block的,),这应该称作sparse file(稀疏文件),对稀疏文件的判断只能是大致的方 法。stat除了看到size外,还可以看到占用的磁盘block数,假如一个block是512字节,block数乘以512得到的结果远小于文件size,大致可以认为是sparse file。
2 标准的C函数不支持对大于2G的文件的读取,要想获得一个(>2G)文件的大小,可以使用stat函数中的st_size;
3 文件状态stat结构中,st_size就是ls看到的文件大小,st_blksize是系统每次read,write等i/o的buff大小,通常和文件系统块大小一致,st_blocks是占用的文件系统的块数,这个块区别以文件系统的块,一般是512字节。Du命令读取st_blocks(du会根据命令参数转换块的大小)。
4 正常来说看到连续的一大堆0可认为是sparse, Linux下的cp命令有参数
--sparse=WHEN
control creation of sparse files
可以看cp的source code详细查看。5 系统调用cp命令的具体执行过程:
cp时,只write了有具体内容的块,空洞没有write,但是lseek是一直在变的,所以cp不会拷贝空洞。
通过看cp的源码,可以看到cp的具体过程:1、 判断目标文件是否存在,如果存在则清空目标文件,如果不存在则创建目标文件
2、根据目标文件的逻辑块大小,创建拷贝缓冲区
3、判断源文件是否有空洞:文件大小/文件块大小 > 块数 ?
4、读取源文件存放到缓冲区,每次读取一块
5、在第3步中判断,如果存在文件空洞,则对缓冲区数据进行判断,如果缓冲区中的数据均为0,则认为该数据快为空洞,否则认为是正常文件数据
6、如果数据块为空洞,则调用lseek,在目标文件中创建一个空洞;否则拷贝缓冲区数据到目标文件
7、判断本次读取是否读到源文件的文件尾,如果是,则判断本次读取的是否是空洞,如果是空洞则在文件的最后写入""
8、重复1 ~ 7
9、关闭目标文件、源文件
- 空洞文件的感想
- 文件空洞引发的思考:空洞与cp
- 文件空洞
- 文件空洞
- 文件空洞产生的原因分析
- 文件空洞产生的原因分析
- Linux文件---文件空洞
- Linux Advance--文件IO--创建一个具有空洞的文件
- 文件lseek操作产生空洞文件的方法
- 嵌入式开发14天(文件IO,空洞文件的生成)
- Linux文件空洞解释
- 空洞文件1
- 空洞文件2
- linux文件空洞
- 创建空洞文件
- 文件空洞测试
- 浅析空洞文件
- 关于"文件空洞"
- C++ new 解析重载 .
- Mesh Genneration Tools For Fluent
- for xml 语句 把查询结果转换成xml格式 以及差查询 暑假第四天
- 狼 与 马
- OI犯2合集!
- 空洞文件的感想
- NULL及DUAL详解
- 3.二进制数的应用、逻辑学及逻辑门
- 一个XBRL应用网站
- 老 狮 子
- Android List列表网络资源异步调用
- Sicily 1197. Hotel
- 比较二个List,将不同的值做为一个新的List返回
- C++中new和delete学习总结


