学习shell(二)
来源:互联网 发布:偶滴歌神推荐社交软件 编辑:程序博客网 时间:2024/04/29 05:42
符号
内容
*
通配符,代表任意字符(0到多个)
?
通配符,代表一个字符
#
注释,这个最常用在脚本里,视为说明
\
跳转符号,将特殊字符或通配符还原成一般符号
|
分隔两个管线命令的界定
;
连续性命令的界定
~
用户的根目录
$
变量前需要加的变量值
&
将指令编程在背景下工作
!
逻辑运算中的“非”
/
路径分隔符号
>,>>
输出导向,分别为“取代”和“累加”
'
单引号,不具备变量置换功能
"
双引号,具有变量置换功能
``
quote符号,两个``中间为可以先执行的指令
( )
中间为子shell的起始与结束
[ ]
中间为字符组合
{ }
中间为命令区块组合
Ctrl+C
终止当前命令
Ctrl+D
输入结束(EOF),例如邮件结束的时候
Ctrl+M
就是Enter
Ctrl+S
暂停屏幕的输出
Ctrl+Q
恢复屏幕的输出
Ctrl+U
在提示符下,将整行命令删除
Ctrl+Z
暂停当前命令
&&
||
当前一个指令执行成功时,执行后一个指令
当前一个指令执行失败时,执行后一个指令
表格中标为红色部分的特殊字符是我们叫常用的!
2、绝对路径和相对路径
绝对路径:路径的写法一定是从根目录”/“写起的。如:/usr/shar/doc
相对路径:路径的写法不是有”/“写起的,比如从目录/usr/shar/doc 转到/usr/shar/man 下时,可以写成 cd ../man.这个就是相对路径的写法了!相对路径的方法广泛应用于脚本中。
下表是经常用到的目录”符号“代表的意义:
.代表当前的目录..代表上层的目录~代表自己的根目录~user代表到user这个人的根目录linux中系统默认是不主动搜寻当前目录下的可执行文件的,那么该如何执行当前目录下的执行文件呢?---对啦!就是用相对路径的概念。
如你要执行在lpp这个目录下的可执行文件a.out 就应该输入命令 。
[root@lpp lpp]# ./a.out
3、命令重导向--这个是bash中相当重要的概念,要重点学习!
使用命令重定向操作符 (Redirection Operators)可以使用重定向操作符将命令输入和输出数据流从默认位置重定向到不同的位置。输入或输出数据流的位置即为句柄。
下表列出了可用于将命令输入和输出数据流进行重定向的操作符。
1).标准输入的控制
语法:命令< 文件将文件做为命令的输入。
[root@lpp ~]# mail -s "mail test" pplaing_xdu@qq.com < .bashrc
-s 表示标题,后面为接受的邮件地址。上个命令的意思就是:将文件.bashrc当做信件的内容,主题名称为mail test ,送给收信人。
2)标准输出的控制
语法:命令> 文件将命令的执行结果送至指定的文件中。
[root@lpp ~]# ls -l > list
命令是将执行“ls -l ”命令的结果写入文件list中
注意:1、若系统中不存在list这个文件,那么系统会自动建立它。
2、若这个文件存在,系统会先将这个文件内容清空,在写入。也就是,若以>将内容融入到一个已有的文件中,该文件的原有内容会被覆盖!
3、>默认输出正确的信息,即同1>。
语法:命令>&文件将命令执行时屏幕上所产生的任何信息写入指定的文件中
[root@lpp ~]# cc file1.c >& error
将编译file1.c 文件时所产生的任何信息写入文件error中
语法:命令>>文件将命令执行的结果附加到指定的文件中。
语法:命令>>& 文件将命令执行时屏幕上所产生的任何信息附加到指定的文件中
关于输入、输出和错误输出
在字符终端环境中,标准输入/ 标准输出的概念很好理解。输入即指对一个应用程序或命令的输入,无论是从键盘输入还是从别的文件输入;输出即指应用程序或命令产生的一些信息;与 Windows系统下不同的是,Linux 系统下还有一个标准错误输出的概念,这个概念主要是为程序调试和系统维护目的而设置的,错误输出于标准输出分开可以让一些高级的错误信息不干扰正常的输出信息,从而方便一般用户的使用。
在 Linux系统中:标准输入(stdin )默认为键盘输入;标准输出(stdout)默认为屏幕输出;标准错误输出(stderr)默认也是输出到屏幕(上面的 std表示 standard )。在 BASH 中使用这些概念时一般将标准输出表示为 1,将标准错误输出表示为 2. 下面我们举例来说明如何使用他们,特别是标准输出和标准错误输出。
输入、输出及标准错误输出主要用于 I/O的重定向,就是说需要改变他们的默认设置。先看这个例子:
[root@lpp ~]# ls > ls_result[root@lpp ~]# ls >> ls_result
面这两个命令分别将 ls 命令的结果输出重定向到 ls_result文件中和追加到 ls_result文件中,而不是输出到屏幕上。">" 就是输出(标准输出和标准错误输出)重定向的代表符号,连续两个 ">"符号,即 ">>" 则表示不清除原来的而追加输出。下面再来看一个稍微复杂的例子
[root@lpp ~]# find /home -name lost* 2> err_result
这个命令在 ">"符号之前多了一个 "2","2>"表示将标准错误输出重定向。由于 /home目录下有些目录由于权限限制不能访问,因此会产生一些标准错误输出被存放在 err_result 文件中。大家可以设想一下 find /home -name lost*2>>err_result 命令会产生什么结果?
如果直接执行 find /home -name lost* > all_result,其结果是只有标准输出被存入 all_result 文件中,要想让标准错误输出和标准输入一样都被存入到文件中,那该怎么办呢?看下面这个例子:
[root@lpp ~]# find /home -name lost* > all_result 2>&
上面这个例子中将首先将标准错误输出也重定向到标准输出中,再将标准输出重定向到 all_result 这个文件中。这样我们就可以将所有的输出都存储到文件中了。为实现上述功能,还有一种简便的写法如下:
[root@lpp ~]# find /home -name lost* >& all_result
如果那些出错信息并不重要,下面这个命令可以让你避开众多无用出错信息的干扰:
[root@lpp ~]# find /home -name lost* 2> /dev/null
/dev/null 被视为垃圾设备,这是个虚拟的垃圾箱,当你把任何东西导入到这个垃圾箱中后,他就会凭空消失哦!!
4、管线命令(PIPE)
管线命令使用的是“|”界定符号,管线命令“|”仅能处理经由前一个指令传来的正确信息,也就是标准输出(STDOUT),对于标准错误信息并没有直接处理能力。整体的管线命令可以使用下图表示:
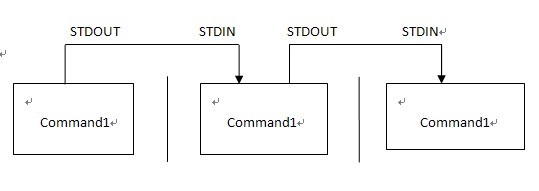
每个管线部分都是指令,而前一个指令的输出是后一个指令的输入!
1)选取指令 cut
注意选取的信息是以行为单位的,即是逐行分析的 .
语法:
[root@lpp ~]# cut -d "分隔字符" [-cf] fields
参数说明:
-d : 后面接的是分隔符,默认是空格符
-c : 后面接的是第几个字符
-f : 后面接的是第几个区块
范例:
[root@lpp ~]# cat /etc/passwd | cut -d ":" -f 1
将passwd文件中的每一行里的”:“用作分行符,列出第一个区块,也就是姓名所在。
[root@lpp ~]# last | cut -c1-20
将last之后的数据,每一行的1~20个字符取出来
cut在分析日志文件中常用。cut的主要用途在于将同一行里的数据进行分解,最常用在分析一些数据或文字书籍的时候,有时候我们需要以一些字符为分割参数,然后将数据分割,以取得我们所需的数据
2)排序命令 sort
注意:sort 帮助我们排序,排序的字符跟语系编码有关系,因此排序前建议使用LC_ALL=C,让语系统一。
语法:
[root@lpp ~]# sort [-t 分隔符] [(+起始)(-结束)][-nru]
参数说明:
-t 分隔符: 使用分隔符隔开不同区块,默认是tab
+start –end: 由第start区块排序到end区块-n: 使用纯数字排序(否则会以字母方式排序)
-r: 反向排序
-u: 相同出现的一行,只列出一次
范例:
[root@lpp ~]# cat /etc/passwd | sort
将列出来的个人帐号排序
3)wc 统计文件中多少字多少行多少字符。
语法:
[root@lpp ~]# wc [-lmw]
参数说明:
-l: 多少行
-m: 多少符号
-w: 多少字
范例:
[root@lpp ~]# cat /etc/passwd | wc -l/w
统计这个文件有多少行或多少字
4)uniq 将重复数据只显示一次
语法:
[root@lpp ~]# uniq
uniq删除重复的行从而只显示一个
范例:
[root@lpp ~]# last| cut -d " " -f1 |sort|uniq
注意:由于这个指令是将重复的东西减少,所以需要配合排序过的文件来处理!
5)tee 命令,双向重定向
语法:
[root@lpp ~]# last | tee last.list | cut -d " " -f1
使用tee,会将数据同时传给下一个命令执行,也会将数据写入last.list文件中
6)字符转换命令 tr
语法:
[root@lpp ~]# tr [-ds] SET1
参数说明:
-d: 删除SET1这个字符串
-s: 取代重复的字符
范例:
[root@lpp ~]# cat /etc/passwd | tr – :
“:”这个符号在/etc/passwd中不见了。
7)split, 可以将大文件分割为小文件,方便复制传送等工作。
语法:
[root@lpp ~]# split [bl] 输入文件 输出文件前导字符
参数说明:
-b: 以文件SIZE来分
-l: 以行数来分
范例:
[root@lpp ~]# split -l 5 /etc/passwd test
会产生testaa,testab,testac等文件。
好了,今天就先学习到这里,明天加油!!FIGHTING !!!!
- 学习shell(二)
- shell学习(二)
- shell学习笔记(二):shell 语法
- Shell学习笔记(二)
- shell学习笔记(二)
- shell 学习 笔记(二)
- shell脚本学习(二)
- Linux Shell学习(二)
- shell 学习笔记 (二)
- shell学习笔记(二)
- Shell命令学习(二)
- Shell学习笔记(二)
- shell学习笔记(二):《Unix Shell编程》学习笔记
- UNIX Shell编程 学习笔记(二)
- learning bash shell 学习笔记(二)
- 《Linux Shell脚本攻略》学习(二)
- Shell学习笔记二(基本语法)
- shell学习笔记之二(变量)
- windows server 2003的驱动
- DOM4j:Content is not allowed in prolog
- Cult3D基础教程——3.出色建模的四个技巧
- AT&T 与Intel 汇编语法比较
- mysql修改初始密码....
- 学习shell(二)
- C++中extern “C”含义深层探索
- 大型高并发高负载网站的系统架构 .
- 人机互动 - 公开课学习笔记(一)设计一致的产品体验
- 关于C6000DSP的堆(heap)和栈(stack)
- 解析XML XStream
- 自定义UITableView的header颜色
- Cult3D基础教程——4.粒子系统
- emacs使用semantic


