折行算法(word warp)
来源:互联网 发布:mysql数据库分页语句 编辑:程序博客网 时间:2024/05/19 13:18
在英文字处理程序中,由于单词都是由字母序列构成,所以当输入到一行的末尾的时候,就会遇到想要输入的单词长度大于所剩余的空白长度的情况,这就是折行问题。对于手写文本,我们可以用连字符‘-’把单词分割到两行上,但是对于字处理程序而言,其拥有更强的处理能力,可以通过运算来避免单词被分割到两行上。
目前对于文本的折行,比较流行的是贪心算法,也就是尝试在当前行中放下尽可能多的单词,当前行不能再容纳更多单词时,就放到下一行。这样进行折行,对于输入的段落,其折行后的结果,行数最少。对于行宽为6,输入文本"aaa bb cc ddddd",使用贪心算法生成的折行后结果为:
------
aaa bb
cc
ddddd
在第二行的输入中,发现输入单词'cc'之后,后面只有3个空位(单词之间有一个空格作为分隔符),而下一个单词'ddddd'的长度为5,所以只能将'ddddd'输出到第3行,对于行宽比较小的情况下,贪心算法会造成个别行右侧的空白较大,显得不是很协调。但是对于常用的字处理程序来说,行宽一般为几十,且这些程序在执行折行的同时还会动态调整行内各单词的间距,所以美观问题不是很大。
要实现折行算法,首先需要把输入的字符串分割成一系列单词,GetWords()函数负责实现此功能,将文本中的单词逐个分离出来,添加到单词数组中。该函数实现的功能比较简单,他将空白视为单词的分隔符,如果两个单词之间包含多个空白符号,函数会将其忽略。
void GetWords(const string& text, vector<string>& words_array){string::const_iterator word_begin, word_end;word_begin = word_end = text.begin();while (word_begin != text.end()){if (!isgraph(*word_begin)){++word_begin;++word_end;continue;}if (isgraph(*word_end)){++word_end;}else{words_array.push_back(string(word_begin, word_end));word_begin = word_end;}}}贪心折行算法以原始文本作为输入,通过GetWords()函数将文本分割为一系列单词,再利用贪心算法对其进行折行处理,在需要折行的地方,函数会加入'\n'(实际的折行算法会在两行之间插入‘软换行’而不是段落标记),最后将执行折行后的文本返回。这里假设所有单词的长度都小于行宽。
string WordWarpGreedy(const string& text, int line_size){int line_space;vector<string>::iterator it;vector<string> words_array;stringstream outstr;GetWords(text, words_array);for (it = words_array.begin(), line_space = line_size;it != words_array.end(); ++it){if ((line_space -= it->length()) >= 0){outstr << (*it);}else{outstr << '\n' << (*it);line_space = line_size - it->length();}if (line_space){outstr << ' ';--line_space;}}return outstr.str();}这个算法在OpenOffice,Word等字处理软件中被广泛使用。优点就是高效,简单。但是贪心算法也存在不足之处,就是对于一个指定的段落执行折行处理时,贪心算法只会利用当前行的信息,来安排单词,而不会考虑段落内其他行的信息,所以对于某些比较畸形的文本输入,贪心算法产生的某些行,会由于单词安排过少,而出现大量的空白,使文本显得不太协调。
Knuth和Plass提出了一种,更加协调的折行处理算法,这种算法在LaTEX中被使用。
该算法的核心思想是,对于折行后文本的每一行末尾,对由于无法继续安插单词而剩余的空白,计算一个代价值,算法保证,处理后的折行文本的所有行的代价之和最小。以上面的输入文本"aaa bb cc ddddd"为例,第一行剩余的空白为0,第二行剩余的空白为4,第三行剩余的空白为1,如果以空白数的平方作为代价计算公式的话,折行后的总代价和是0^2 + 4^2 + 1^2 = 17。利用Knuth-Plass提出的算法,折行后的输出文本是
------
aaa
bb cc
ddddd
这样,第一行剩余空白是3,第二行的剩余空白是1,第三行的剩余空白是1,折行后总代价值是3^2 + 1^2 + 1^2 = 11,总代价值小于贪心算法的折行结果。
但是对于输入段落,要想求得最小的代价值并不容易,在对段落内容的逐渐扫描中,之前已经安排的单词的位置可能会不断发生变化。如上例,当我们输入完bb时,算法会将bb安排到第1行,此时总代价值为0,当我们输入"cc"之后,如果"bb"还在第一行,则总代价值为4^2 = 16,不是目前的最小代价值,所以算法会将bb移动到第二行,此时的代价总和为3^2 + 1^2 = 10,是当前的最小值。对于行数更多的文本,由于追求最小代价值而导致的级联单词位置调整,可能会很频繁。
Knuth-Plass折行算法,使用了动态规划的思想,当输入单词j的时候,前j个单词所构成的段落的代价最小值f(j),的计算公式为:

语言描述这个递推式的意思是,当输入单词j时,向前搜索词表中的所有单词,找到满足条件的单词k,将单词k~j安排在最后一行,其他单词位置不动(如果之前有某几个单词在倒数第2行,则将这几个单词移动到最后一行,如前例的'bb'),最后计算出这种安排的总代价和,这个总代价在所有的安排方案中最小。其中的c(i, j),是代价计算公式,其意义是,将第i到第j个单词安排在一行时,其末尾的空白数的平方,公式如下:
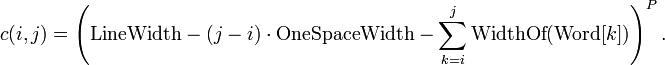
这两个公式均摘自Wiki百科。代价计算公式的P值可以自行决定,一般使用2,3.这个公式有一点需要注意,因为每行的宽度有限,所以如果单词i到j再加上他们之间的分割空白的总长度之和超过行宽时,实际上是无法将这些单词安排在一行的。此时需要返回一组特定的值来表示这种情况。示例为了简单,对于无法将单词i~j安排在一行的情况c(i,j)返回-1,下面是代价计算函数:
inline int CostFunc(const vector<string> words_array, int line_size,unsigned int begin, unsigned int end){unsigned int i;int t, cost;for (i = begin, t = 0; i <= end; ++i){t += words_array[i].length();}cost = line_size - (end - begin) - t;if (cost < 0){return -1;}return cost * cost;}Knuth-Plass折行算法的实现代码如下:
string WordWarpKnuth(const string& text, int line_size){unsigned int i, j, p;int t, min;vector<string> words_array;stringstream outstr;GetWords(text, words_array);int cost[words_array.size()];int lines[words_array.size()];i = 0;//填充初始在第一行的单词,要防止一行可以容納所有所有情況下的越界while(i < words_array.size() && (t = CostFunc(words_array, line_size, 0, i)) >= 0){cost[i] = t;lines[i++] = 0;}for(;i < words_array.size(); ++i){for(j = i - 1, min = INT_MAX; j > 0; --j){t = CostFunc(words_array, line_size, j + 1, i);if(t >= 0){if(t + cost[j] < min){min = t + cost[j];p = j;}}else{break;}}cost[i] = min;//这里lines[i]保存的是当前单词所处行的上一行的最后一个单词的索引lines[i] = p + 1;}i = words_array.size() - 1;//根据计算结果倒推各单词所处的行的情况while(i > 0){j = lines[i];while(i > j){lines[i--] = j;}if(i == 0){lines[i] = j;}else{lines[i--] = j;}}outstr << words_array[0] << ' ';for(i = 1; i < words_array.size(); ++i){if(lines[i] != lines[i - 1]){outstr << '\n';}outstr << words_array[i] << ' ';}return outstr.str();}代码的空间复杂度为O(j),如果提前将段落中所有子单词串的长度和计算出来备用,时间复杂度为O(j^2)。
- 注意程序中的lines数组,记录的是当前单词所在行的上一行的最后一个单词的索引位置,因为在单词不断加入的过程中,折行安排会不断的发生变化,所以用这种方法记录。
- 对于c(i,j)等于-1的情况,说明行宽无法安排Word[i]~Word[j],用这个值计算最小代价无意义,所以直接舍弃。
对于行宽为25,输入文本"I'm a good guy, and Iknow what I should not to do!"为例,贪心算法的折行结果为:
-------------------------
I'm a good guy, and I
know what I should not to
do!
Knuth-Plass算法的折行结果为:
-------------------------
I'm a good guy,
and I know what I
should not to do!
Knuth-Plass算法的折行结果,比贪心算法更加整齐,对于末行的大片空白,可以通过修正代价值计算方法解决。LaTEX号称最强悍的文本处理程序,绝对不是浪得虚名,而是由很多强悍的技术来支撑的。
当然获得更优美的折行结果是需要代价的,Knuth-Plass算法无论是时间复杂度还是空间复杂度都明显要比贪心算法大很多。而且更重要的是,要实现优美的折行处理,Knuth-Plass算法需要获取整个段落的信息,而在像Word这样的所见即所得字处理程序中,在用户输入段落标记之前,你是无法确切知道这个段落究竟是什么情况的,实时调用Knuth-Plass算法进行折行,代价就比较可观了。Knuth-Plass算法在运行过程中,随着用户的输入,会动态调整各行单词的安排,贪心算法则只会影响当前行的内容,如果用户在输入文本的过程中,发现之前输入的单词“上窜下跳”,估计也是一种比较怪异的使用体验。
所以这个算法只有在像LaTEX这样的编译型字处理程序中,才能大展身手。而且为了简单起见,本文的示例程序,是以字符为单位安排折行的,而在实际的应用中,字母'w'和字母'i'的显示宽度显然是不一样的,所以如果使用像素作为折行的依据,无疑Knuth-Plass算法能够达到更高的境界,这是贪心算法所无法比拟的。
- 折行算法(word warp)
- 长字符串间的换行与单词间的换行-(word-break , word-warp)
- warP()
- warp
- GDAL源码剖析(十二)之GDAL Warp API使用说明
- cuda warp
- Warp-CTC
- 基于八叉树快速分类的Shear-Warp交互式体绘制算法
- CUDA术语Warp
- [warp portal] Python Tutorials
- Time Warp in Animation
- CSU1626: Time Warp
- CSU1626 Time Warp
- Thread与Warp
- OpenGL-----Projective Image Warp
- 算法 之 word break
- 算法16 Word Search
- 算法百题006:单词逆序输出(Word Reversal)
- 存储过程(二)
- 高质量C++/C编程指南(林锐)
- joj1018
- 存储过程的定义
- 数组作为函数形参和用指针作为函数形参
- 折行算法(word warp)
- asp.net _2天
- asp.net第二天
- Qt多线程学习-用例子来理解多线程(转)
- 构造函数定义为private,protected
- 对Hadoop源代码中Child类的调试方法
- Ubuntu10.04配置VPN
- 存储过程再续
- (11)JDBC数据库的连接,对数据的增删改查


