Sql Server性能优化——分区表及示例
来源:互联网 发布:清华同方是网络电视吗 编辑:程序博客网 时间:2024/05/02 04:36
Sql Server性能优化——Partition(创建分区)
和压缩(Compression)相比,数据库分区(Partition)的操作更为复杂繁琐。而且与Compression一次操作,终身保持不同,分区是一项需要长期维护周期变更的操作。
分区的意义在于将大数据从物理上切割为几个相互独立的小部分,从而在查询时只取出其中一个或几个分区,减少影响的数据;另外对于置于不同文件组的分区,并行查询的性能也要高于对整个表的查询性能。
事实上,在SQL Server 2005中就已经包含了分区功能,甚至在2005之前,还存在一个叫做“Partitioned Views”的功能,能通过将同样结构的表Union在一个View中,实现类似现在分区表的效果。而在SQL Server 2008中,分区功能得到了显著加强,使得我们不仅能够对表和索引做分区,而且允许对分区上锁,而不是之前的全表上锁。
指定分区列
和Compression一样,在SQL Server 2008中也提供了分区的向导界面。在企业管理器中,需要分区的表上右键选择Storage-》Create Partition:
")
这里会列出该表所有的字段,包括字段类型、长度、精度及小数位数的信息,可以选择其中的任意一一列作为分区列(Patitioning Column),不仅仅是数字或者日期类型,即使是字符串类型的列,也可以按照字母顺序进行分区。而以下类型的列不可用于分区:text、ntext、image、xml、timestamp、varchar(max)、nvarchar(max)、varbinary(max)、别名、hierarchyid、空间索引或 CLR 用户定义的数据类型。此外,如果使用计算列作为分区列,则必须将该列设为持久化列(Persisit)。
在列表下方,提供了两个选项:
- 分配到可用分区表:
这要求在同一数据库下有另一张已分好区的表,同时该表的分区列和当前选中的列的类型完全一致。
这样的好处是当两张表在查询中有关联时,并且其关联列就是分区列时,使用同样的分区策略会更有效率。 - 将非唯一索引和唯一索引的存储空间调整为与索引分区列一致:
这样会将表中的所有索引也一同分区,实现“对齐”。这是一个重要而麻烦的选项,具体需求请参阅MSDN(已分区索引的特殊指导原则)。
这样的好处是表和索引的分区一致,一方面查询时利用索引更为高效,而且在下文提到的移入移出分区也会更为高效。
注意:这里建议使用聚集索引列作为分区列。一方面索引结构本身就应与查询相关,那么分区列与索引一致会保证查询的最大效率;另一方面,保证索引对齐而且是聚集索引对齐是保证分区的移入移出操作顺畅的前提,否则可能会出现无法移入移出的情况,而分区的移入移出又是管理大数据的重要策略——滑动窗口(SlideWindow)策略的基础操作。另外,如果要进行索引对齐,需要所有索引和表的压缩模式一致。
分区函数与分区方案
选好分区列后,如果没有应用“分配到可用分区表”选项,接下来则会进入选择\创建分区函数以及分区方案的界面。其中分区函数会指定分区边界,而分区方案则规划了每个分区所存储的文件组。
向导操作界面如下:
")
其中Left boundary说明每个分区的边界值被包含在边界值左侧的分区中,也就是每个分区内的数据约束是<=指定的边界值,相应的,Right boundary则说明每个分区的边界值被包含在边界值右侧的分区中,每个分区内的数据约束是<指定的边界值。
在下方的列表中,列出了当前分区方案下现有的分区。其中文件组(Filegroup)指定了每个分区存放的位置,如果将分区放置于位于不同磁盘中的不同文件组中,由于不同磁盘的读写互不干扰,这将提高分区表并行处理的效率。一般情况下,将所有分区放置在同一个文件组是比较稳妥的做法。关于文件组的展开阅读可以参阅:SQL Server Filegroups。
注意,在这里最后一个分区是没有指定边界的,用于保存所有>(Left Boundary)或>=(Right boundary)最后一个分区边界的数据。
如果选择时间类型的字段作为分区列,可以通过Set按钮实现按条件分组:
")
这样可以很方便得通过设置起止时间将表按照指定时间段自动分区,但之后依然需要手动指定每个分区的文件组。
制定好分区方案之后可以通过Estimate sotrage预估每个分区的行数、空间占用情况,不过除非需要以占用空间或行数来规划你的分区策略,一般不建议在这里进行预估,因为如果对空表来说,预估的结果当然都是0,而如果表中已经包含大量数据,预估则会花费比较长的时间。
创建分区
通过以上设置,分区已经基本完毕,在向导的最后,可以选择是创建脚本还是立即执行分区操作。
我们可以查看在不同情况下创建分区的脚本的情况:
1.在表没有索引的情况下:
BEGIN TRANSACTIONCREATE PARTITION FUNCTION [TestFunction](datetime) AS RANGE LEFT FOR VALUES (N'2010-01-01T00:00:00', N'2010-02-01T00:00:00', N'2010-03-01T00:00:00', N'2010-04-01T00:00:00', N'2010-05-01T00:00:00', N'2010-06-01T00:00:00')CREATE PARTITION SCHEME [TestScheme] AS PARTITION [TestFunction] TO ([PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY])CREATE CLUSTERED INDEX [ClusteredIndex_on_TestScheme_634025264502439124] ON [dbo].[Account] ( [birthday])WITH (SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [TestScheme]([birthday])DROP INDEX [ClusteredIndex_on_TestScheme_634025264502439124] ON [dbo].[Account] WITH ( ONLINE = OFF )COMMIT TRANSACTION
这里先创建Partition Function以及Partition Scheme,之后在分区列上创建聚集索引并按照分区方案分区,最后删除了这一索引。</>
2.在表有索引的情况下:
如果原先没有聚集索引:
CREATE CLUSTERED INDEX [ClusteredIndex_on_TestScheme_634025229911990663] ON [dbo].[Account] ( [birthday])WITH (SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [TestScheme]([birthday])DROP INDEX [ClusteredIndex_on_TestScheme_634025229911990663] ON [dbo].[Account] WITH ( ONLINE = OFF )
这和没有索引的情况一样,如果表原先存在聚集索引,则脚本变为:
CREATE CLUSTERED INDEX [IX_id] ON [dbo].[Account] ( [id] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = ON, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [TestScheme]([birthday])
可以看到原有的聚集索引(IX_id)在分区方案上被重建了。
如果选择了“对齐索引”选项,则会对所有索引都应用分区:
CREATE CLUSTERED INDEX [IX_id] ON [dbo].[Account] ( [id] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = ON, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [TestScheme]([birthday])CREATE NONCLUSTERED INDEX [UIX_birthday] ON [dbo].[Account] ( [birthday] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = ON, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [TestScheme]([birthday])CREATE NONCLUSTERED INDEX [UIX_name] ON [dbo].[Account] ( [name] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = ON, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
这里不仅对聚集索引IX_id进行了分区,也对非聚集索引UIX_name和UIX_birthday进行了分区。
注意事项
- 对一张表分好区后不可以进行再次分区,同时也没有直接取消表分区的方法。
- 如果要查看已分区表的分区状态以及每个分区中的行数和占用空间,可以通过Storage-》Management Compression查看。同时可以在这里为每个分区指定压缩方式。
- 如果分区表索引没有对齐,则不可以对该表进行切入切出(Switch in/out)操作,同样也不能执行滑动窗口操作。
- 分区实际上是在每个分区表都添加了约束,相应的插入操作的性能也会受到影响。
- 即使进行了分区,如果查询的条件字段和分区列并没有关联,性能也未必会得到提升。
附:对分区并行查询的说明
由于我在实际操作中主要考虑并行查询方面的效率,所以文章里只是略略带过,但评论中有人提到,所以摘录整理一些资料在下面:
- 并行查询肯定需要多核支持,单核下并行是不可能的。
- 在2005中,如果有两个以上的Partition,一个线程对应一个Partition,所以如果有10个线程,却只有3个分区的话,就会有7个线程被浪费。
- 在2008中,这一问题被改进,所有的线程都被投入到所有的Partition中。具体可以参看Partitioning enhancements in SQL Server 2008。
转自:http://www.cnblogs.com/smjack/archive/2010/02/23/1671943.html
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
管理分区:
正如上一篇文章SqlServer性能优化——Partition(创建分区)中所述,分区并不是一个一劳永逸的操作,对一张表做好分区仅仅是开始,接下来可能需要频繁的变更分区,管理分区。
在企业管理器中,虽然有“管理分区”的菜单,里面的内容却可能与你的预想不同,这里并没有提供直接对分区进行操作的方法,所以一些普通的操作,比如“增加分区”、“删除分区”之类的操作就需要通过脚本实现了。
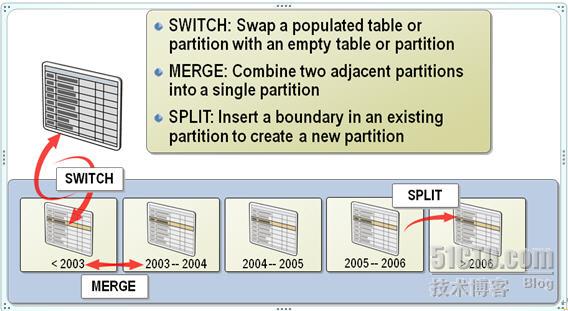
增加分区(Split Partition)
“增加分区”事实上就是将现有的分区分割开,基于此,在SQL Server中应用的是Split操作。在分离分区的时候,不仅仅要在Partition Function上指定分割的分界点,同样需要在Partition Scheme上指定新分区应用的文件组:
--指定下一个分区应用文件组PRIMARYALTER PARTITION SCHEME [MyPartitionSchema] NEXT USED [PRIMARY]--指定分区分界点为5000ALTER PARTITION FUNCTION MyPartitionFunction()SPLIT RANGE (5000)
需要注意的一点是,新增的分区中非聚簇索引的压缩模式会被置为None。
删除分区(Merge Partition)
“删除分区”同样可以认为是将原来分离的分区合并在一起,所以对应的是Merge操作,而且由于并没有新增的分区,Partition Scheme并不需要改变:
ALTER PARTITION FUNCTION MyPartitionFunction ()MERGE RANGE (5000)
切换分区(Switch Partition)
“切换分区”可能是一个比看上去会应用的更频繁的操作,它的意义在于将一个分区的数据从一张表切换到另一张表中。这里定义被切换分区的表为“源表”,被切换到的表为“目标表”,则执行切换操作的前提是:
- 源表和目标表拥有同样的表结构,即同样的字段、字段类型,同样的索引结构(聚簇和非聚簇),同样的压缩格式。但不要求默认值约束一致(Default Constaint),也不要求目标表设置了和源表一样的自增长列。
- 源表如果有索引且分区,则其索引必须对齐。
- 源表中被切换的分区范围必须包含于目标表或者目标表将要被切换到的分区范围。这里有如下几种情况:
- 将源表的源分区切换到目标表的目标分区中,则目标分区范围>=源分区;
- 将源表的源分区切换到目标表中(目标表未分区),则目标表没有设约束,或约束范围>=源分区;
- 将源表切换到目标表中(源表、目标表都未分区),则只要目标表没有设约束就可以了(虽然Switch是分区提出的操作,但一个没有分区的表同样可以被看做一个大分区,所以可以对没有分区的表进行Switch操作)。
- 目标表或目标分区不能含有数据。
下面的操作将源表的第二个分区切换到目标表的第二个分区中。
ALTER TABLE [STable] SWITCH PARTITION 2 TO [DTable] PARTITION 2
分区管理操作的性能
分割、合并以及切换分区是元数据上的操作而不是对数据的移动,所以操作的效率要比直接操作数据高很多。
- 对于分割分区,操作时间和被分割分区的数据量相关,数据越大则分割花费的时间会越长。
- 对于合并分区,如果将两个空的分区合并,自然不会耗什么时间;如果两个分区都有数据,则和分割分区一样,数据越大花费的时间越长;如果两个分区中有一个没有数据,笔者的经验是如果有大数据量的分区在右(>分界值),则消耗的时间较短,如果有大数据量的分区在左(<分界值),则会消耗较多的时间。
- 对于切换分区,即使是上千万级别的数据,也可以在不到1秒的时间完成分区的切换。所以虽然从表面上看,切换分区和调用Select或者Insert语句移动数据的结果是一样的,但效率却是不可同日而语的。
查看分区信息
除了利用上文提到的通过“管理压缩”的方式查看某张表的分区信息之外,SQL Server还提供了一张系统表查看数据库中的分区情况:
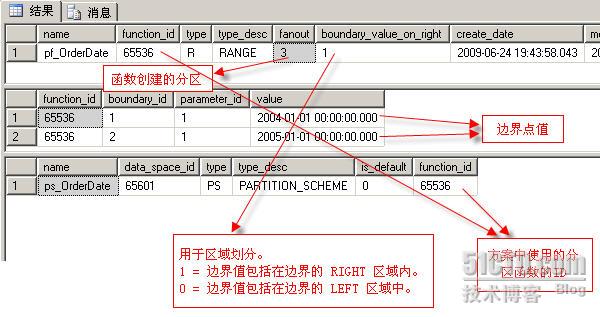
- SYS.PARTITION_SCHEMES,数据库中所有分区方案的信息,包括对应的分区函数的ID。
- SYS.PARTITION_FUNCTIONS,数据库中所有分区函数的信息,包括分区数等信息。
- SYS.PARTITION_RANGE_VALUES,每个分区范围的信息,可以和SYS.PARTITION_FUNCTIONS联查。
比如可以通过如下的脚本,查出分区函数MyPartitionFunc的第一个分区的右边界:
SELECT value FROM sys.partition_range_values, sys.partition_functions WHERE sys.partition_functions.function_id = sys.partition_range_values.function_id AND sys.partition_functions.name = 'MyPartitionFunc' AND boundary_id = 1
还可以通过如下脚本,获取分区表中各分区的数据情况(行数,最大值,最小值):
SELECT partition = $PARTITION.MyParitionFunc([ParitionDate]) ,rows = COUNT(*) ,min = MIN([ParitionDate]) ,max = MAX([ParitionDate])FROM [MyTable]GROUP BY $PARTITION.MyParitionFunc([ParitionDate])ORDER BY PARTITION
具体可以参照MSDN:从已分区表和索引中查询数据和元数据
相关资料:
http://msdn.microsoft.com/zh-cn/library/ms188706.aspx
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
实战:
(
NAME = N'Sales',
FILENAME = N'C:\Sales.mdf',
SIZE = 3MB,
MAXSIZE = 100MB,
FILEGROWTH = 10%
),
FILEGROUP FG1
(
NAME = N'File1',
FILENAME = N'C:\File1.ndf',
SIZE = 1MB,
MAXSIZE = 100MB,
FILEGROWTH = 10%
),
FILEGROUP FG2
(
NAME = N'File2',
FILENAME = N'C:\File2.ndf',
SIZE = 1MB,
MAXSIZE = 100MB,
FILEGROWTH = 10%
),
FILEGROUP FG3
(
NAME = N'File3',
FILENAME = N'C:\File3.ndf',
SIZE = 1MB,
MAXSIZE = 100MB,
FILEGROWTH = 10%
)
LOG ON
(
NAME = N'Sales_Log',
FILENAME = N'C:\Sales_Log.ldf',
SIZE = 1MB,
MAXSIZE = 100MB,
FILEGROWTH = 10%
)
GO
GO
CREATE PARTITION FUNCTION pf_OrderDate (datetime)
AS RANGE RIGHT
FOR VALUES ('2003/01/01','2004/01/01') --n不能超过 999,创建的分区数等于 n + 1
GO
GO
CREATE PARTITION SCHEME ps_OrderDate
AS PARTITION pf_OrderDate
TO (FG1, FG2, FG3)
GO
GO
CREATE TABLE dbo.Orders
(
OrderID int identity(10000,1),
OrderDate datetime NOT NULL,
CustomerID int NOTNULL,
CONSTRAINT PK_Orders PRIMARY KEY (OrderID, OrderDate)
)
ON ps_OrderDate (OrderDate)
GO
CREATE TABLE dbo.OrdersHistory
(
OrderID int identity(10000,1),
OrderDate datetime NOT NULL,
CustomerID int NOTNULL,
CONSTRAINT PK_OrdersHistory PRIMARY KEY (OrderID, OrderDate)
)
ON ps_OrderDate (OrderDate)
GO
GO
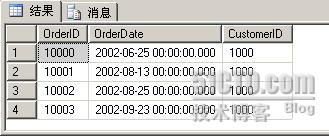
INSERT INTO dbo.Orders (OrderDate, CustomerID)VALUES ('2002/6/25', 1000)
INSERT INTO dbo.Orders (OrderDate, CustomerID)VALUES ('2002/8/13', 1000)
INSERT INTO dbo.Orders (OrderDate, CustomerID)VALUES ('2002/8/25', 1000)
INSERT INTO dbo.Orders (OrderDate, CustomerID)VALUES ('2002/9/23', 1000)
GO
GO
INSERT INTO dbo.Orders (OrderDate, CustomerID)VALUES ('2003/6/25', 1000)
INSERT INTO dbo.Orders (OrderDate, CustomerID)VALUES ('2003/8/13', 1000)
INSERT INTO dbo.Orders (OrderDate, CustomerID)VALUES ('2003/8/25', 1000)
INSERT INTO dbo.Orders (OrderDate, CustomerID)VALUES ('2003/9/23', 1000)
GO
SELECT * FROM dbo.OrdersHistory
FROM dbo.Orders
WHERE $PARTITION.pf_OrderDate(OrderDate) = 1
FROM dbo.Orders
WHERE $PARTITION.pf_OrderDate(OrderDate) = 2
COUNT(*) AS [COUNT]
FROM dbo.Orders
GROUP BY $PARTITION.pf_OrderDate(OrderDate)
ORDER BY Partition ;
GO
ALTER TABLE dbo.Orders SWITCH PARTITION 1TO dbo.OrdersHistory PARTITION 1
GO
SELECT * FROM dbo.OrdersHistory
GO
ALTER TABLE dbo.Orders SWITCH PARTITION 2TO dbo.OrdersHistory PARTITION 2
GO
GO
ALTER PARTITION SCHEME ps_OrderDate NEXT USED FG2
ALTER PARTITION FUNCTION pf_OrderDate() SPLIT RANGE ('2005/01/01')
GO
GO
ALTER PARTITION FUNCTION pf_OrderDate() MERGE RANGE ('2003/01/01')
GO
FROM dbo.OrdersHistory
WHERE $PARTITION.pf_OrderDate(OrderDate) = 2
FROM dbo.OrdersHistory
WHERE $PARTITION.pf_OrderDate(OrderDate) = 1
select * from sys.partition_range_values
select * from sys.partition_schemes
本文出自 “李涛的技术专栏” 博客,请务必保留此出处http://terryli.blog.51cto.com/704315/169601
- Sql Server性能优化——分区表及示例
- SQL SERVER性能优化--分区表
- SQL server 分区表示例
- SQL Server安全及性能优化
- SQL server 2005 中的分区表(代码示例)
- SQL Server性能优化
- SQL Server性能优化
- SQL Server性能优化
- SQL Server 性能优化
- SQL Server性能优化
- SQL SERVER 性能优化
- Sql Server CPU 性能排查及优化的相关 Sql
- SQL Server性能优化——等待——SLEEP_BPROOL_FLUSH
- SQL Server 性能优化(一)——简介
- SQL Server 查询性能优化——索引与SARG
- SQL Server查询性能优化——创建索引原则
- SQL Server 查询性能优化——覆盖索引
- SQL Server 性能优化之——重复索引
- 类(3)
- 修改Oracle XE Listener 占用的1521、8080端口
- ContentProvider和Uri详解
- 浏览器的调试软件
- netbox将asp程序打包
- Sql Server性能优化——分区表及示例
- PHP中spl_autoload_register函数的用法
- Android数据存储之文件存储
- hibernate 联合主键 merge
- 09 harbin现场赛 DLX
- 2011秋季课表
- 类4
- 类5
- 我的wscite 配置


