带你体验串行到并发的旅途--第一部分
来源:互联网 发布:淘宝现货指的是什么 编辑:程序博客网 时间:2024/05/01 10:35
首先给出一个数组求和的例子,通过下面的图示可以很清楚的看明白,我也就不说过多的废话了,当然当你看完下面的这幅图的时候,就会面对三组程序,这些都是在并行下的程序代码,分别是OpenMP以及Windows Threads还有POSIX Pthreads下的改编代码,均实现了并发的作用,至于串行下的代码,这里没有给出,我想这么简单的求和代码你一定闭着眼睛都能写出来的。我们的体验就从这里出发,后面会在接下来的文章中逐一体验这种将串行改编成并行代码的玩乐之旅。
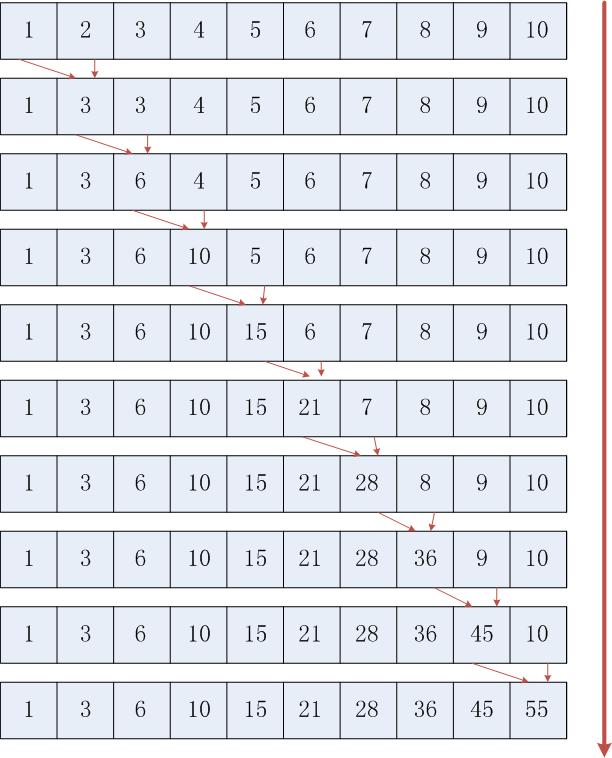
对于上面简要的给予说明,就是对于数组进行求和运算的一个过程,下面是三部分的代码,串行的程序代码你很清楚怎么写,很简单。
首先是OpenMP的并行代码示例:
OpenMP///////////////////////////////#include "stdafx.h"#include <iostream>using namespace std;int main(int argc, char *argv[]){ int sum=0; int X[10]={1,2,3,4,5,6,7,8,9,10};#pragma omp parallel for reduction(+:sum) for(int i=0;i<10;i++) { sum = sum+X[i]; } cout<<sum<<endl; system("pause"); return 0;}//////////////////////////////////这部分是Windows Threads代码示例:#include "stdafx.h"#include <windows.h>#define NUM_THREADS 2int X[10]={1,2,3,4,5,6,7,8,9,10};int gSum[NUM_THREADS];DWORD WINAPI Summation(LPVOID pArg){ int tNum=(int)pArg; int lSum=0; int start, end; start=(10/NUM_THREADS)*tNum; end =(10/NUM_THREADS)*(tNum+1); if (tNum == (NUM_THREADS-1)) { end=10; } for(int i=start; i<end; i++) { lSum+=X[i]; } gSum[tNum]=lSum; return 0;}int main(int argc, char *argv[]){ int j, sum=0; HANDLE tHandles[NUM_THREADS]; for (j=0;j<NUM_THREADS;j++) { DWORD threadID; tHandles[j]=CreateThread(NULL, 0 ,Summation, (LPVOID)j, 0, &threadID); } for (j=0; j<NUM_THREADS; j++) { WaitForSingleObject(tHandles[j],INFINITE); sum += gSum[j]; } printf("sum is %d\n", sum); system("pause"); return 0;}////////////////////////////////////////////////////////////////////////////////////////////下面给出POSIX Pthreads下的并行代码:
////////////////////////////////////////////////#include <pthread.h>#include <stdio.h>#include <stdlib.h>#define NUM_THREADS 2int X[10]={1,2,3,4,5,6,7,8,9,10};int gSum[NUM_THREADS];void* Summation(void *pArg){ int tNum=*((int*)pArg); int lSum=0; int start, end; start=(10/NUM_THREADS)*tNum; end =(10/NUM_THREADS)*(tNum+1); if (tNum == (NUM_THREADS-1)) { end=10; } for(int i=start; i<end; i++) { lSum+=X[i]; } gSum[tNum]=lSum; free(pArg);}int main(int argc, char *argv[]){ int j, sum=0; pthread_t tHandles[NUM_THREADS]; for (j=0;j<NUM_THREADS;j++) { int *threadNum=new(int); *threadNum=j; pthread_create(&tHandles[j], NULL, Summation, (void*)threadNum); } for (j=0; j<NUM_THREADS; j++) { pthread_join(tHandles[j], NULL); sum += gSum[j]; } printf("sum is %d\n", sum); system("pause"); return 0;}///////////////////////////////////////////////////////////////////////////////////////////////////通过上面的程序,你或许会说这不就是多线程啊,没什么东西,对了,你说对了,这是个引例,没有什么不过是不可或缺的开始,通过将串行代码修改成并行代码有很多中方式,你可以使用OPenMP,TBB,也可以使用不同环境下的线程来做。下面你将看到这篇文章的真正的开始,如何将串行修改成并行,达到在多核情况下的效率提升:

从上图你看明白我们要实现什么吗,我们需要实现每项是之前项的和,下面是实现的串行代码:
#include <iostream.h>int main(int argc, char *argv[]){ int A[8]={3,5,2,5,7,9,4,6}; for (int i=1;i<8;i++) { A[i]=A[i-1]+A[i]; } for (int j=0;j<8;j++) { cout<<A[j]<<" "; } cout<<endl; return 0;} 下面我来看看并发的修改方式,图示如下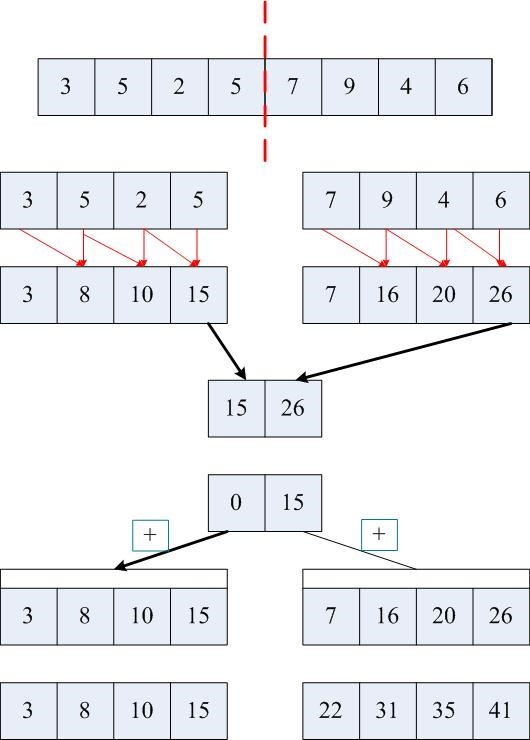
下面是实现的代码,上面的过程分为三部分来实现,在程序里面体现出来,希望这些会给你帮助
#include <iostream.h>#include <windows.h>#include <process.h> #define NUM_THREADS 2 int A[8]={3,5,2,5,7,9,4,6};int inTotals[NUM_THREADS],outTotals[NUM_THREADS];HANDLE doneStep1[NUM_THREADS];HANDLE doneStep2; unsigned _stdcall prefixScan(LPVOID pArg){ int tNum=*((int *)pArg); int start,end,i; int lPrefixTotal; free(pArg); start=(8/NUM_THREADS)*tNum; end=(8/NUM_THREADS)*(tNum+1); if (tNum == (NUM_THREADS-1)) { end=8; } for (i=start+1;i<end;i++) { A[i]=A[i-1]+A[i]; } inTotals[tNum]=A[end-1]; SetEvent(doneStep1[tNum]); WaitForSingleObject(doneStep2, INFINITE); lPrefixTotal=outTotals[tNum]; for (i=start; i<end;i++) { A[i]=lPrefixTotal+A[i]; } return 0;} int main(int argc, char *argv[]){ int i,j; HANDLE tHandles[NUM_THREADS]; for (i=0;i<NUM_THREADS;i++) { doneStep1[i]=CreateEvent(NULL,TRUE,FALSE,NULL); } doneStep2=CreateEvent(NULL,TRUE,FALSE,NULL); for (i=0;i<NUM_THREADS;i++) { int *tnum=new int; *tnum=i; tHandles[i]=(HANDLE)_beginthreadex(NULL, 0, prefixScan, (LPVOID)tnum, 0, NULL); } WaitForMultipleObjects(NUM_THREADS, doneStep1, TRUE, INFINITE); outTotals[0]=0; for (j=1;j<NUM_THREADS;j++) { outTotals[j]=outTotals[j-1]+inTotals[j-1]; } SetEvent(doneStep2); WaitForMultipleObjects(NUM_THREADS, tHandles, TRUE, INFINITE); for (int ti=0;ti<8;ti++) { cout<<A[ti]<<" "; } cout<<endl; return 0;}//////////////////////////////////////////////////////////////
当数据量很大时,再加之内核数量的提升,并发将会带来极大的效率上面的提高。希望对你有用。
由于时间不足,这篇文章后面还有修正添加。
- 带你体验串行到并发的旅途--第一部分
- 你的态度,你的旅途风景
- 带你走入Debian--第一部分.基础知识和安装
- Flex 3 体验:AdvancedDataGrid的使用(第一部分)
- Flex 3 体验:AdvancedDataGrid的使用(第一部分)
- 编写你的第一个Django应用, 第一部分
- 关于《Java并发编程实战》 -- 第一部分的阅读笔记
- 带你体验正规的运维工作是什么的!
- 古藤堡带你体验别样的田园生活
- Postcss、css4带你体验一种独特的优雅
- Toaster Step-by-step 一步一步带你构造MD-SAL烤面包机 第一部分:定义烤面包机
- 带你实现一个简单的MyApacheTomcat,迷你并发服务器
- 并发调度的可串行性
- 数据库 - 并发调度的可串行性
- 并发调度的可串行性
- 并发调度的可串行性
- 帮你快速理解同步 ,异步,并发/并行,串行
- 你永远不应该做的事,第一部分
- Linux Top 命令解析 比较详细
- Ubuntu11.04--Wireshark配置
- 数组 桶排序
- 差距
- Linux 源码安装工具 CheckInstall
- 带你体验串行到并发的旅途--第一部分
- Windows下vim配置
- 读取文件夹下所有文件内容
- shell命令行的一些快捷键汇总
- PHP操作MongoDB学习笔记
- Android——ImageButton按下效果设计
- C语言:extern 讲解
- joj2474
- 编程之美 中国象棋将帅问题 位操作


