中文分词语言模型和动态规划
来源:互联网 发布:黄金行情走势软件 编辑:程序博客网 时间:2024/05/02 02:59
===============================================================================
如有需要可以转载,但转载请注明出处,并保留这一块信息,谢谢合作!
部分内容参考互联网,如有异议,请跟我联系!
作者:刀剑笑(Blog:http://blog.csdn.net/jyz3051)
Email:jyz3051 at yahoo dot com dot cn('at'请替换成'@','dot'请替换成'.' )
===============================================================================
关键词:中文分词,分词语言模型
到目前为止,中文分词包括三种方法:1)基于字符串匹配的分词;2)基于理解的分词;3)基于统计的分词。到目前为止,还无法证明哪一种方法更准确,每种方法都有自己的利弊,有强项也有致命弱点。
综合这几种方法,建立一种"复方配剂"可能是一种有效的解决方案,我采用的方案需要能够综合运用这三类方法。方案的基础就是分词模型,该模型需要能够综合这三种方法,下面我将介绍我的"基于字符的中文分词模型"。
中文分词就是将连续的汉字字符系列拆分成一系列有意义中文词语的过程。下面给出模型中的各种表示:
(1)分词的基本单元是文档,记作D;
(2)待分词的文档通过分隔符,将该文档D分拆为一系列的字符串。将文档拆分为字符串的标志包括:
① 标点符号,如句号、逗号、顿号、引号、感叹号、书名号、破折号、省略号等;
② 分隔符,如分页符、分节符、段落符等;
③ 一些特征词,如"的、和、与"等,但是这种方法常常会导致错误,故很多分词系统都不采取这种策略;
(3)待分词的字符串S有n个字符组成,这里的字符可以是汉字,也可以是英文字母、数字、下划线、连字符等各种符号,每个字符用si表示,则S={s1s2s3s4s5s6s7s8s9……sn}。如待分词字符串为:"他购买了一盒Esselte品牌的SHA-PA型号24/6的订书钉"则s1="他",s2="购"……s32="钉",n=32,表示该字符串有32个字符。
(4)原子系列,将字符串系列进行初步处理,得到S的原子系列A={a1a2a3a4……am}(m<=n),其中原子ai表示一个或多个连续字符的组合,即ai=sj…sk。每个原子被认为是在中文分词环境下,不能再分的字符组合,如一个汉字、一个英文单词、连字符连接的两个字母、英语缩写等等。如"他购买了一盒Esselte品牌的SHA-PA型号24/6的订书钉"的原子系列为:"他#购#买#了#一#盒#Esselte#品#牌#的#SHA-PA#型#号#24/6#的#订#书#钉",m=18,表示有18个原子。将字符串分隔为原子系列的规则常常为:
① 一个汉字为一个原子;
② 一个英语单词为一个原子;
③ 连字符连接的两个英文字符串为一个原子;
④ 无空格的连续英文字符串为一个原子。
以上的四个过程是借助中科院的分词系统中采用的方法,我只不过规范化了该过程而已。到此为止,一个待分词的字符串S已经变成了多个原子的组合,即S=A1A2……Am,下面就进入了一个新的过程:如何将这些原子组合成正确的词语系列W={w1w2w3……wk},(其中k<=m)。即:A1A2……Am到w1w2w3……wk转换的过程,为了保证分词的准确性,在这一过程需要综合以上三种分词算法的思想。
首先,借鉴中科院分词系统的思路,首先在原子系列前后分别加上"起始"和"结尾"标志,这里假设"起始"标志为"S##S","结尾"标志为"E##E",则得到新的原子系列为:
S##SA1A2……Am E##E
则"S##S"的位置是0,A1的位置是1,依次类推,Am的位置是m,"E##E"的位置是m+1。
如借用别人的例子:"李胜利说的确实在理",原子系列为:"李/胜/利/说/的/确/实/在/理",故加上"起始"、"结束"标记后变成"S##S/李/胜/利/说/的/确/实/在/理/ E##E"。
中文分词需要将这个原子系列进行一系列的合并操作,最终得到一系列的中文词语。当然,一个原子系列常常能得到多种分词结果,我们希望得到最可能的一种分词系列,即:如果假设我们最终得到的分词为W*,则可以表示为maxP(W|A),其中P(W|A)表示原子系列A得到词语系列W的可能性。上面的说明也可以通过下面的过程加以说明:
P(W|A) = P(WA)/P(A) = P(A|W)*P(W)/P(A)
因为在词语系列W的情况下,获得原子系列A的概率是1,则上式可以变换成:
P(W|A) = P(WA)/P(A) = P(W)/P(A),故:W* = max P(W)/P(A) = max P(w1w2w3……wk)/P(A)。
从上面的过程可以发现,W*是所有可能分词中最有可能的一种。如果我们穷举所有的分词可能,然后计算每种分词的可能性,计算量将是非常巨大的,故常常将求W*的过程看作是一个动态规划的问题。下面我以上面的例子"S##S/李/胜/利/说/的/确/实/在/理/ E##E"来构建这个动态规划问题,即在从"S##S"到"E##E"的所有路径中,寻找一条路径,使该路径出现的可能性是所有路径中有最大可能性。这就包括两项任务:
①找出所有可能的从"S##S"到"E##E"的路径;
②找出所有路径中,有最大可能出现的路径;
对于①,至少要保证最优的那条路径存在于该路径集合中,故在这一步我们需要为该原子系列串增加尽可能多的路径才行,当然也要考虑计算量,尽量减少那些可能性小的路径。
对于②,首先我们要定义什么才叫最优路径,并建立一个动态规划方程,求解该方程,得到最终的分词系列。
如"S##S/李/胜/利/说/的/确/实/在/理/ E##E"得到如下的路径图:

从上图可以看出,这些路径中不存在正确的路径,即最优路径并不在这个路径集合中,故无法得到我们最后需要的路径,这里就涉及到未登录词识别的问题,这个问题将在后面的文章中讨论。
===============================================================================
如有需要可以转载,但转载请注明出处,并保留这一块信息,谢谢合作!
部分内容参考互联网,如有异议,请跟我联系!
作者:刀剑笑(Blog:http://blog.csdn.net/jyz3051)
Email:jyz3051 at yahoo dot com dot cn('at'请替换成'@','dot'请替换成'.' )
===============================================================================
关键词:中文分词,中文分词语言模型,动态规划
前面的文章中(详细请参见"中文分词的语言模型"),我们给出了能够融合三种分词算法的语言模型,该模型能够融合目前出现的所有三种分词算法,并将该语言模型用一个统一的概率模型表示出来:给出原子系列,最有可能出现的中文词语系列就是我们需要的最终分词结果,可表示如下:
W* = max P(W)/P(A) = max P(w1w2w3……wk)/P(A)
最后,我们给出了求解该模型的网络示意,中文分词就成为求解最大概率的路径,中文分词过程就变成了以下的两个过程:
① 找出所有可能的从"S##S"到"E##E"的路径;
② 找出所有路径中,有最大可能出现的路径;
下面我将这种介绍如何建立动态规划模型。
最优路径指从"S##S"到"E##E"最有可能出现的词语系列,这包括两个方面的问题:1)这些词语同时出现的概率,同时出现的概率越大,则该系列越有可能;2)这些词语以这个顺序出现的概率,以这个顺序出现的概率越大,则该系列越有可能;这中间还有一个隐含的问题没有揭露出来,即假设这些组合(原子或词语)就是所有的可能,所以并没有涉及到未登录词识别的问题。因为我要建立一个统一的分词框架,故应该还包括第三个问题:3)这些词语(或原子)出现的概率,词语(或原子)出现的可能性越大,则越有可能出现,成为最优路径。当然问题1)和问题2)可以合并,从而得到以下的两个问题:
- 这些词语(或原子)本身出现的概率多大;
- 这些词语(或原子)以这个顺序同时出现的概率多大;
两者综合的概率越大,则越有可能形成这个系列,从而越有可能成为我们的最优分词结果。
综合这两个问题,某个路径L出现的概率可以表示为:
P(L) = P(w2|w1)P(w3|w1w2) P(w4|w1w2w3) ……P(wk|w1w2w3…w(k-1))
*P(w1) P(w2) P(w3)…… P(wk)
如路径L1"李/胜利/说/的/确实/在理/ E##E"中,词语系列W={李,胜利,说,的,确实,在理},则这条路径出现的概率可以表示为:
P(L1) = P(胜利|李) * P(说|李胜利) * P(的|李胜利说) * P(确实|李胜利说的)
* P(在理|李胜利说的确实)
* P(李) P(胜利) P(说) P(的) P(确实) P(在理)
此时,需要得到各个词语的概率P(W),以及"李胜利"、"李胜利说"、"李胜利说的"、"李胜利说的确实"的概率。在实际应用系统中,前一种概率完全是可以穷举得到的,就是词典中词语出现的概率,而后一种字符串是无穷无尽的,全部计算它们的概率是几乎不可能的,故在实际应用中常常进行简化,即只认为后一个词语wi+1仅仅与前面一个词语wi相关,仅仅受wi的影响,而不受wi-1、wi-2、……w1等的影响,实践证明这种方法是一种很有效的方法。
在这个假设下,路径L的概率计算公式为:
P(L) = P(w2|w1) * P(w3|w2) * P(w4|w3) *……* P(wk|w(k-1))
*P(w1) * P(w2) * P(w3)…… * P(wk)
结合上面出现的"动态规划路径图"可以看出,p(wi|wi-1)表示在前一个词出现的情况下,后一个词出现的概率,即图形中"边"的权重,而P(wi)则表示某个词语出现的概率,即图中"结点"的权重。
此时,可以得到一个标注权重的"动态规划路径图",示意图如下:
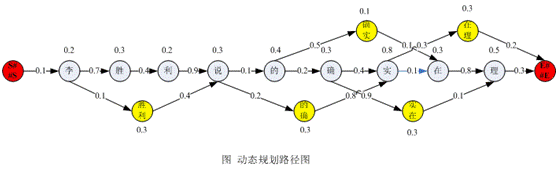
经过这个转换之后,我们就把中文分词过程(找出最大概率的词语系列)转换成了寻找一条从"S##S"到"E##E"最大可能路径的问题,很明显这是一个动态规划问题。其中:
(1) 结点上的权重表示该结点出现的可能性;
(2) 边上的权重表示两个“结点”按照该顺序出现的可能性;
- 中文分词语言模型和动态规划
- 中文分词语言模型和动态规划
- 动态规划和中文分词
- 动态规划的中文分词方法
- R语言:中文分词和聚类
- 【中文分词系列】 5. 基于语言模型的无监督分词
- 动态规划之字符串分词
- 中文分词1-传统模型
- R语言进行中文分词和聚类
- R语言进行中文分词和聚类
- R语言进行中文分词和聚类
- 动态规划-用金矿模型用通俗的语言讲解
- 概率语言模型分词方法
- 中文分词和搜索引擎
- 中文分词和搜索引擎
- 中文分词和搜索引擎
- 中文分词和搜索引擎
- 中文分词和搜索引擎
- HDOJ 2046 骨牌铺方格
- Linux世界开启传送门-预备第一天
- WebBrowser页面与WinForm交互技巧
- Memory Meaning on the bottom of android"running services"
- ld.so.conf 文件与PKG_CONFIG_PATH变量
- 中文分词语言模型和动态规划
- 自定义控件属性(attr.xml,TypedArray)
- 将后台窗口激活到前台的方法
- JDBC连接各种数据库的方式
- 单链表逆序
- form表单中get与post的区别
- Oracle: Use NVL() to convert a null value into another value.
- 如何将一个某个窗口提到最顶层
- struts2中ActionContext是什么东东???


