HBase vs. Cassandra: NoSQL 战争!
来源:互联网 发布:java web即时通讯框架 编辑:程序博客网 时间:2024/06/05 03:07
HBase vs. Cassandra: NoSQL Battle! [转]
from http://www.roadtofailure.com/2009/10/29/hbase-vs-cassandra-nosql-battle/
目前分布式的,可扩展的数据库正被猛烈的需要着,从社会媒体新兴公司需要构建海量数据仓库,到生物公司的蛋白质链分析。“大数据”每一天都变得更重要了。尽管Hadoop目前已经是大数据问题处理方面事实存在的标准。但仍然存在一些其他的分布式数据库,每个都有他们独特的优势。
有两个数据库获得了最多的关注:HBase 和 Cassandra。关于这两个雄心勃勃的项目的分歧可以归纳为特性和架构方面的不同。HBase 像是山寨版的BigTable。而Cassandra 声称是BigTable/Dynamo 的混血儿。
就我看来,尽管Cassandra宣称“写不会失败”是其优势,在大多数使用场景下,HBase 是一个更健壮的数据库。Cassandra 主要依赖Key-Value对作为存储对象,辅以类似表结构的方式增加数据的健壮性。一个事实是,尽管近来两者越来越相似了,相对Cassandra 来说,当前使用HBase的人要更多。
CAP 和你的关注点
本文简短描述一下 CAP理论(Consistency一致性, Availability 可获得性, Partitioning tolerance 分区容忍)以及 起源于BigTable的HBase 和 起自Dynamo的Cassandra 在这方面有什么不一样。
在我们进一步深入前,让我们做个简单的分解
Consistency 一致性:“我当前正看到的数据和其他某个地方的别人看到的是一致的吗?”
Availability: 可用性:“如果我的数据库宕机了,会发生什么事情,数据还能访问吗?”
Partitioning tolerance 分区容忍:“如果网络间连接中断,被分割在各自独立的子网络中,会发生什么事,数据还能访问吗”
(此处原文和我的翻译都不是很好,关于CAP理论,可参考http://pt.alibaba-inc.com/wp/dev_related_728/brewers-cap-theorem.html中描述)
CAP理论指出分布式系统不得不在三种因素中做妥协。HBase认为高一致性和高可用性更有价值。Cassandra 认为高可用性和分区容忍更有价值。复制是一种设计上的折中处理。HBase目前还不支持复制,但正准备支持。Cassandra 支持复制,但附带一些告诫和不利后果
让我们对这两种数据存储做一些比较吧:
功能比较
1)处理能力
HBase 是Hadoop生态系统的一部分,有许多有用的分布式处理框架支持,比如PIG,Cascading, Hive, 等等。这是的复杂的数据分析变得相对简单一些,没有重排序和手工编码的需要。另一方面,在Cassandra上有效的运行MapReduce 是比较复杂的,因为它的所有键存放在一个大“空间”中,因此MapReduce 框架不知道如何顺利的分解和分配数据。这需要一些hackery 去处理这种情况(不知道怎么翻译这句话)。
事实上,这儿就有些补丁代码用来集成 Cassandra/Hadoop
+ /*
+ FIXME This is basically a huge kludge because we needed access to
+ cassandra internals, and needed access to hadoop internals and so we
+ have to boot cassandra when we run hadoop. This is all pretty
+ fucking awful.
+
+ P.S. it does not boot the thrift interface.
+ */
这让我感到害怕。
概要来说,Cassandra 也许在存储方面是比较有效的,但是在数据处理方面,HBase更具有优势。
2)安装和易用性
Cassandra 是简单的Rubygems方式安装,这让人印象深刻。但你仍需要做相当部分的手工配置。然而,HBase 是一种.tar格式的安装文件,你需要自己一步步的安装和设置。HBase 有详尽的文档,这让安装过程变得简单了些。
HBase同时还发布了一个非常好的Ruby shell,简化了数据库的创建和修改、设置和检索数据。我们经常地用它来测试我们的代码。而Cassandra 并没有这样的shell脚本,只有基本的API。HBase 此外还有很好的基于Web的UI,你可以用来查看集群状态,确定哪个节点存储了什么样的数据,等等操作。Cassandra 缺少WEB UI支持和Shell脚本支持使得它操作起来不太方便。
总的来说,Cassandra 安装上比较容易,但是可用性不如HBase。
3) 架构
Cassandra 和HBase 的思想和架构上的基础性差异引起了很多的争议,争议的主题是“谁是更好的”。
立刻,Cassandra 宣称“写操作永远不会失败”,而对HBase来说,如果目标region归属的region server 宕机的话。写操作将被阻塞,直到该region被重新调配到新的regionserver上。当然这个情况发生概率非常小,但是在足够大规模情况下,确实会发生。此外,HBase 有一个单点故障点(Hadoop NameNode),但随之Hadoop的进化,这将不是很大的问题。HBase有行级锁,但是Cassandra 没有。
应用程序通常假设获取数据时,数据是正确性和且不会被改变,所以“最终一致(Eventually Consistent)”的思想是有问题的。Cassandra 有内部的vector clocks 方法解决一致性问题,(一种复杂的,但是可工作的方法,这种方法下,通常是时间戳最新的数据胜利了)。HBase或Bigtable则把解决数据一致性冲突的问题推给了应用程序,因为他们把所有的数据都用时间戳做多版本控制。
另外一个架构上的批评意见是Cassandra 每次安装只支持一张表。这意味着你不能故意多拷贝一份数据使得分析变得更容易进行。(新版本已经解决)Cassandra 更像一个键值存储,而不是数据仓库。此外,Schema发生改变时,需要集群重启.
Cassandra JIRA说Schema发生改变时,需要做如下的事情:
Kill Cassandra Start it again and wait for log replay to finish
Kill Cassandra AGAIN Make your edits (now there is no data in the commitlog)
Manually remove the sstable files (-Data.db, -Index.db, and -Filter.db) for the CFs you removed, and rename files for CFs you renamed
Start Cassandra and your edits should take effect
缺乏时间戳控制的多版本功能,缺乏最终一致性、没有regions(导致MapReduce变得困难),每次安装只能支持一张表。基于这些问题,很难宣称Cassandra 实现了BigTable模型。
(原文如此,With the lack of timestamp versioning, eventual consistency, no regions (making things like MapReduce difficult), and only one table per install,
it’s difficult to claim that Cassandra implements the BigTable model.
可能翻译的不准确)
4)复制
Cassandra 对由高速光纤连接的小型数据中心(几百个节点左右)是最佳的。这部分来自Amazon的Dynamo的遗产。HBase 基于Google研究的产物,适合处理散布在全球各地的节点,连接它们的网络是“缓慢”且不可预料的Internet网。
一个主要的差别是它们在多数据中心见复制方式的差别。Cassandra 使用P2P共享方式,Hbase(即将到来的版本)更多使用了数据加日志备份的方式,又被称为‘log shipping’.每种方式都有自己的优势场景。为了更好的理解,下面画两个图来解释:
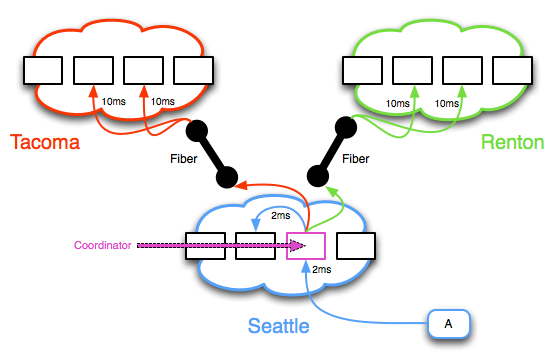
第一幅图是Cassandra 的复制模型
1)The value is written to the “Coordinator” node
2)A duplicate value is written to another node in the same cluster
3)A third and fourth value are written from the Coordinator to another cluster across the high-speed fiber
4)A fifth and sixth value are written from the Coordinator to a third cluster across the fiber
任何的冲突都在cluster内部解决,通过检查时间戳来决定谁是最合适的。这种场景最大的问题就是现实世界中需要的可审计性。节点是最终一致的--如果一个数据中心失败了,无法知道有多少副本需要被更新。这在实际场景中会非常痛苦--当你的一个数据中心失败了。你通常希望知道准确的,什么时候可以恢复数据一致性,这样后续的恢复操作才能平稳进行。
需要着重申明的是Cassandra 依赖数据中心之间的告诉光纤。如果你的写操作耗费1-2ms的话,没有什么问题。但是当数据中心宕机,你不得不回归到在中国的第二个数据中心,而不是20公里外的第一个数据中心。无法想象的延迟会导致写超时和严重的数据不一致。
让我们看看HBase复制模型(注:这将在.21版本发布)
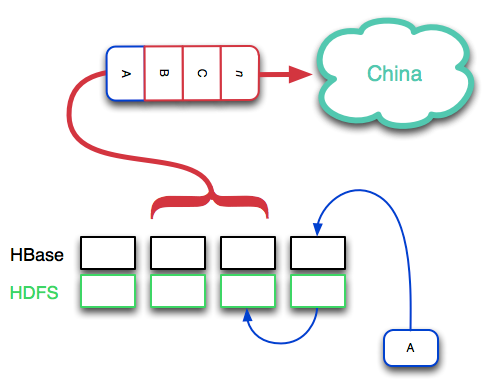
事情是这样的:
数据首先被写到HBase 内存的Write-ahead-log 中,然后数据又被刷到磁盘上。因为Hadoop 分布式文件系统的特性,磁盘上的文件自动的被复制。数据进入到“复制日志”中,“复制日志”被管道传送到另外一个数据中心。通过HBase/Hadoop精心设计的事件序列,数据中心间的一致性是非常高的。一般情况下,同一时间段内只有一个数据片。如果不是,HBase的时间戳允许你的代码来衡量们那个版本的数据是正确的,而不是cluster自己选择。因为“日志复制”的天性,你可以始终知道数据一致性差异情况--一个很有用的工具,当另外一个数据中心宕机的时候。此外,使用这种方式,使得网络高延迟场景下恢复变得容易了,比如洲际数据传输情况。
5)知道选择谁
Amazon 和 google的商业背景解释了Cassandra 和HBase各自强调的不同功能
Cassandra 设想的是数据中心间高速的网络连接,这是Amazon’s Dynamo的产物:Amazon 数据中心从历史上看就是彼此靠的非常近(几十公里远),通过高速网络连接。Google 拥有横贯大陆的数据中心,都通过标准的internet连接,这意味着需要更可靠的复制机制。
如果你需要高可靠性的写操作和最终一致性,那么Cassandra 是最好的一个。然而很多程序并不希望看到最终一致性,并且它仍然缺乏很多特性。此外尽管写不会失败,当变更schema时,Cassandra 的集群需要宕机重启。HBase更多的关注在读,但是可以出来很高的读写负载。它更接近数据仓库的概念,能服务每秒百万请求。和MapReduce 的结合使HBase 更有价值,更多才多艺。
- HBase vs. Cassandra: NoSQL 战争!
- NOSQL数据库大比拼:Cassandra vs MongoDB vs CouchDB vs Redis vs Riak vs HBase
- NOSQL数据库大PK:Cassandra vs MongoDB vs CouchDB vs Redis vs Riak vs HBase 数据库
- NoSQL数据库 Cassandra vs MongoDB vs CouchDB vs Redis vs Riak vs HBase comparison
- NOSQL数据库大比拼:Cassandra vs MongoDB vs CouchDB vs Redis vs Riak vs HBase
- NoSQL 比较 - Cassandra vs MongoDB vs Redis vs ElasticSearch vs HBase
- NoSQL对比:Cassandra vs MongoDB vs CouchDB vs Redis vs Riak vs HBase vs Membase vs Neo4j
- NoSQL比较:Cassandra vs MongoDB vs CouchDB vs Redis vs Riak vs HBase vs Membase vs Neo4j
- Cassandra vs HBase
- HBase vs Cassandra
- Cassandra VS. HBase
- HBase VS Cassandra
- HBase vs Cassandra
- SQL vs NoSQL 没有硝烟的战争!
- NoSQL数据库对比:MongoDB vs.Cassandra
- HBase vs Cassandra: why we moved
- HBase vs Cassandra: why we moved
- HBase vs Cassandra-装载
- 2011-10-27 jsp
- HTML 页面中 DIV 居中技巧
- Jsp应用
- 查询gcc配置信息
- (第四篇)在FFilmation场景中创建定义来用
- HBase vs. Cassandra: NoSQL 战争!
- 没有IT工作经验找工作难吗?
- Installation error: INSTALL_FAILED_INSUFFICIENT_STORAGE
- Excel VBA - Workbook对象
- java初学者必须看的 也应该懂得
- 如何得到指定文件的公司名称,文件描述,内部名称,合法版权,原始文件名,产品名称,产品版本等一系列信息
- 在Eclipse3.4中安装Freemarker插件
- LARGE_INTEGER类型 和 QueryPerformanceFrequency()
- Android项目打包


