运行于Windows中的GIZA++( GIZA++ working inWindows Platform)
来源:互联网 发布:小卖家申请淘宝直播 编辑:程序博客网 时间:2024/05/01 22:05
摘 要:Linux环境中,大部分基于短语的统计机器翻译系统可以很方便的利用GIZA++训练得出的词语对齐结果。然而,对于许多习惯在Windows系统中从事科学研究的科研工作者却享受不到这种便利。虽然我们可以使用Cygwin或者虚拟机在Windows系统下模拟Linux系统,但是有时这样来回的切换很不方便。本文主要是想和大家分享一下我们如何在Windows系统中使用GIZA++进行词语对齐的一些经验。
正文:
词语对齐是自然语言处理领域的一个基本的问题,许多基于双语语料库的应用(比如统计机器翻译(SMT)、基于实例的机器翻译(EBMT)、词义消歧(WSD)、词典编撰)都需要词汇级别的对齐。一般来讲,对齐可以有篇章(section)、段落(paragraph)、句子(sentence)、短语(phrase)、词语(word)等不同的级别的对齐,其目的就是从双语互译的文本中找出互译的片段。其中篇章、段落、句子的对齐技术主要用于语料库的整理,而短语和词语对齐,就是要找出相互翻译的文本中对应的词与词、词与短语、短语和短语之间的相互翻译对。现今的基于短语的统计机器翻译系统中,很大一部分程度依赖于词语对齐(word alignment)[Och et al.,2000;Yarowsky et al.,2000]。现在使用最多的词语对齐方法就是使用双语语料库来抽取词语对齐[Smadja et al.,1996;Melamed,2000],其中典型的代表也是本文中将使用的对齐软件就是GIZA++[Och,2000;Och et al.,2003]。
GIZA++的前身是GIZA(GIZA是由是统计机器翻译工具Egypt的一部分,Egypt是在1999年约翰霍普金斯大学统计机器翻译夏季讨论班上,由一些研究人员共同合作开发的统计机器翻译工具包。[1]),GIZA++实现了IBM公司提出的5个模型[Brown et al.,1993]和隐马尔科夫模型(HMM)[Och et al.,2003],其主要思想是利用EM算法对双语语料库进行迭代训练,由句子对齐得到词语对齐。由于GIZA++不依赖于具体的语言对,现在的统计机器翻译系统中几乎都使用了GIZA++进行词语对齐。表1是从GIZA++对齐文件中取出的一个稍加改进的例子。其中x是目标语言句子、y是源语言句子、a是对齐结果,比如“3-2”的意思就是说中文句子的第二个单词“在”对齐到英文的第四个单词“in”(英文句子从0开始标注)。
表 1. 词语对齐示例
x
I0 am1 studying2 in3 the4 university5 of6 Macau7 .8
y
NULL ({ 4 }) 我 ({ 0 }) 在({ 3 }) 澳门大学 ({ 5 6 7 }) 读书 ({ 1 2 }) 。({ 8 })
a
4-0 0-1 3-2 5-3 6-3 7-3 1-4 2-4 8-5
在基于短语的统计机器翻译系统中,比如Moses[Koehn et al.,2007]词语对齐就显得非常重要,究其原因就是统计机器翻译的质量很大程度取决于一个叫做短语翻译(phrase table)的文件,而这个短语翻译表就来自于GIZA++的词语对齐结果。词语对齐工具GIZA++通过EM算法对给定的双语语料库进行双向对齐,通过交集(intersection)和并(union)的操作最终得到较好的词语对齐结果。通过以下两个条件,统计机器翻译系统利用短语对齐的结果进行短语的抽取[Galbrun,2009]:
(1)分别从源语言句子f中和目标语言句子e中抽取连续的单词序列f'和e',并且单词序列的长度不能超过k个单词。
(2)连续的单词序列f' 和e' 的对齐信息a' 要由源语言和目标语言的对齐信息a构建而来,其中a' 至少要在a中包含一个连接。
表2给出了一个利用GIZA++中英对齐结果进行短语抽取的例子。
其中对齐为:<I-我><am-能够><able-能够><to-能够><do-做><it-它><well-好><.-。>
表 2. 利用GIZA++对其结果进行短语抽取示例
词语对齐
短语表
(我 ||| I);
(我 能够 ||| I am able to );
(我 能够 做 ||| I am able to do);
(我 能够 做 好 它 ||| I am able to do it well);
(我 能够 做 好 它 。||| I am able to do it well .);
(能够 ||| am able to );
(能够 做 ||| am able to do);
(能够 做 好 它 ||| am able to do it well);
(能够 做 好 它 。||| am able to do it well .);
(做 ||| do);
(做 好 它 ||| do it well);
(做 好 它 。 ||| do it well .);
(好 ||| well);
(好 它 ||| it well);
(好 它 。||| it well .);
(它 ||| it);
(它 。 ||| it .);
(。||| .)
现在步入正题:在实际的科研过程中,很多科研工作者经常使用Windows系统进行科学研究,而GIZA++现在运行于Linux, Irix and SUN等这些操作系统中,对Windows系统还不支持,这就给广大的科研工作者,尤其是熟悉Windows环境的学者带来了不方便。虽然中国有个网名叫做Blue Gene的人成功的把GIZA++移植到了Windows系统[2],可是仍然要像在Linux环境下一样在DOS界面中输入好多命令,并且要修改很多代码,很是费时。当然我们也可以借助于虚拟机在Windows中安装Linux系统,也可以借用Linux模拟工具Cygwin来操作GIZA++,可是仍然离不开命令行参数的输入。本文中我们的目的就是利用GIZA++生成的可执行程序来直接进行词语对齐,这样我们既可以完整的保留GIZA++的完整性,也可以节省了开发时间提高了科研效率。
系统开发过程中,我们利用Cygwin生成GIZA++的可执行文件,然后借用批处理技术,再加上微软的Visual Studio 2008,最终开发出了一个方便操作的词语对齐系统。
具体的方法就是:
首先使用Cygwin在windows中,编译GIZA++ ,生成可执行文件,主要需要:mkcls.exe,plain2snt.out, snt2cooc.out, GIZA++.exe
然后,把这些编译好的可执行文件,放入一个批处理文件中,表3给了一个例子:其中,chinese和english是我所采用的双语语料库文件名。
表 3. giza.bat批处理文件内容示例
giza.bat批处理文件命令行参数
mkcls.exe -c80 -n10 -pchinese -Vchinese.vcb.classes opt
mkcls.exe -c80 -n10 -p english -V english vcb.classes opt
plain2snt.out chinese english
GIZA++.exe -S chinese.vcb -T english.vcb -C chinese_english.snt
再其次就是使用VS 2008进行界面设计了。这里面的关键是如何去调用这些可执行文件。下面给出实用的函数等。
表4. 使用shellExecute()函数调用可执行文件
控制shellExecute()函数是否运行结束的方法
SHELLEXECUTEINFO sei; //定义变量
memset(&sei, 0, sizeof(SHELLEXECUTEINFO)); //在内存中填充数值
sei.cbSize = sizeof(SHELLEXECUTEINFO);
sei.fMask = SEE_MASK_NOCLOSEPROCESS;
sei.lpVerb = _T("open"); //打开可执行程序
sei.lpFile =_T( "GIZA++.exe"); //调用的程序名
sei.nShow = SW_HIDE; //调用的过程中不显示GIZA++的运行界面
ShellExecuteEx(&sei); //执行调用可执行文件
WaitForSingleObject(sei.hProcess, INFINITE); //等待程序运行后才执行其它程序
CloseHandle(sei.hProcess); //关闭进程
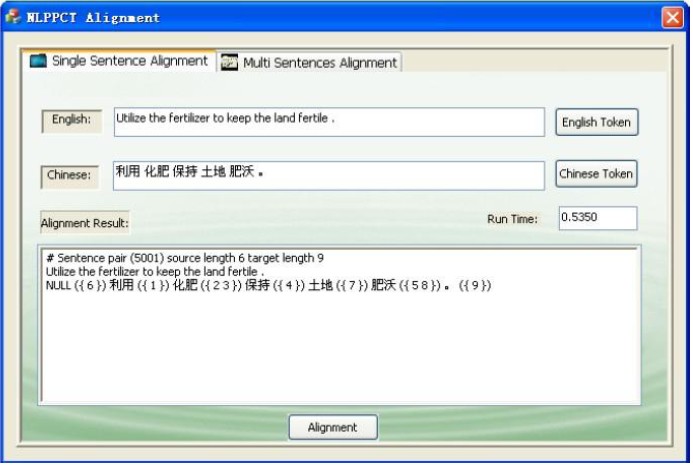

图二,最新的不再采用GIZA++的对齐界面,这是多语句的对齐
1 http://www-i6.informatik.rwth-aachen.de/Colleagues/och/software/GIZA++.html
2 http://www.pudn.com/downloads135/sourcecode/windows/detail575412.html
- 运行于Windows中的GIZA++( GIZA++ working inWindows Platform)
- GIZA++运行详细报告
- About Giza++
- GIZA++运行情况记录和结果对比
- GIZA++ 使用说明书
- ubuntu15.04 32位下基于IRSTLM,GIZA++和Moses的统计翻译系统的环境搭建及运行
- 使用GIZA++进行平行语料的词对齐
- GIZA++实现了IBM模型1~5 IBM Model 1详解
- jar 独立运行文件制作(于windows平台)
- Windows Azure Platform (六) Windows Azure应用程序运行环境
- windows运行中的命令
- 防火墙 windows 错误1079 此服务的账户不同于运行于同一进程中的其他服务账户
- Working with Windows Registry
- 微软WINDOWS AZURE PLATFORM(云系统)
- 浑天码(原“广陵码”)成功安装运行于Windows Vista
- 在ubuntu13.1中用于运行Windows程序
- 让ASP程序运行于非Windows平台
- windows下关于程序安装运行的权限问题
- web服务器控件—导航控件—SiteMapPath
- 程序员面试题精选100题(55)-不用+、-、×、÷数字运算符做加法
- 不定参数函数
- forward redirct 转向和重定向区别;通过el和java代码在jsp页面取出参数,jsp:param注意事项
- 哈工大java实验 文件分割与合并
- 运行于Windows中的GIZA++( GIZA++ working inWindows Platform)
- 推荐图书:我的职场十年
- 常见SSL证书格式转换
- 2011年10月30日夜记梦
- MongoDB试用
- 迷茫的CODE MONKEY
- 虚拟机的网络连接方式
- Poechant 解读 Java API —— 借助货币格式化,初识 Locale 和 NumberFormat
- 用CSS实现水平虚线的两种方法


