Linux上posix线程库实现原理讨论
来源:互联网 发布:linux断点续传命令 编辑:程序博客网 时间:2024/05/20 01:38
原文:来自论坛一处讨论http://bbs.chinaunix.net/thread-497496-2-1.html
说明一下,这个问题困扰我好长时间,因为正如使用C编程会希望了解进程的内存映象一样,使用POSIX线程库我们也会想去了解其实现的原理。目前只是查过一些资料,或许仍然有误解的地方,请大家继续指正 ![]()
首先我们需要了解线程(threads)是个什么概念。在传统UNIX中,进程(process,就是Intel所谓的task)是调度的最小单位,复杂的大型软件往往需要有多个进程,fork+exev是很常用的技巧。但是随着需求的扩大,特别是网络服务的复杂性增长,fork的开销就成为一个瓶颈问题。为此产生了vfork和copy-on-write技术,都是为了减小fork的开销。
pthreads的引入也是为了解决fork开销问题,同时能够支持SMP(对称多处理器)。在SMP机器上,一个进程内的多个线程可以分布在各个处理器上并行运行。
由于历史原因,2.5.x以前的linux对pthreads没有提供内核级的支持,所以在linux上的pthreads实现只能采用n:1的方式,也称为库实现。下面先说一下pthreads的3种实现方式。
pthreads的实现有3种方式:
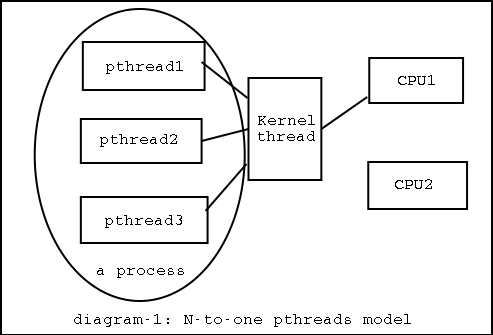
第一,多对一,也就是库实现。模型图如下。
这种实现没有OS的支持,线程对OS来说是不可见的,OS不知道线程的存在与否,也不负责对它们进行调度。所有的此类工作由线程库来完成。
可想而知,既然调度不是由OS进行的,那么SMP机器的优势完全用不上。一个进程只能运行在一个CPU上,不管它包含多少线程。
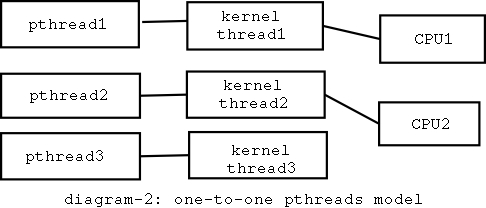
第二种,1:1模式。(好象Solaries就是这种模式?)
1:1模式中,每个线程对应存在一个内核线程。也就是说,OS知道每个线程的生老病死,对它们进行调度。
1:1模式适合CPU密集型的机器。我们知道,进程(线程)在运行中会由于等待某种资源而阻塞,可能是I/O资源,也可能是CPU。在多CPU机器上1:1模式是个很不错的选择。因此1:1的优点就是,能够充分发挥SMP的优势。
这种模式也有它的缺点。由于OS为每个线程建立一个内核线程,导致内核级的内存空间(IA32机器的4G虚存空间的最高1G)的大开销。第二个缺点在于,在传统意义上,在mutex互斥锁和条件变量上的操作要求进入内核态,这是因为OS负责调度,它要为线程的转态转换负全责。后面我们会看到,Linux的NPTL库避免了这个缺点,它的互斥锁与条件变量的操作在用户态完成。
下面是1:1模式的示意图:
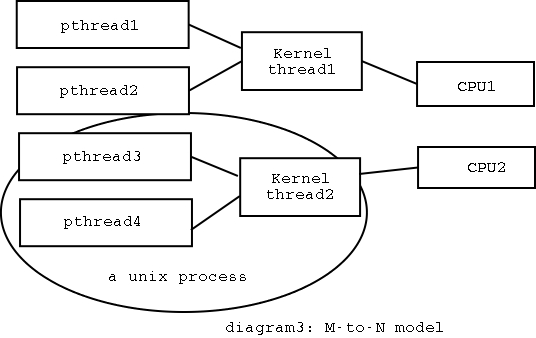
第三种,M:N模式。
这种模式试图兼有上面2种模式的优点。它要求一个分层的模型。比方说,某个进程内有4个线程,其中每2个线程对应一个内核线程。这样,OS知道2个实体的存在,负责它们的调度。而在一个实体内有2个线程,这2个线程间的调度就是OS不加干涉、也不知道的了。
简单的说,M:N模型的OS级调度上,跟1:1模型相似;线程间调度上,跟n:1模型相似。
优点是,既可以在进程内利用SMP的优势,又可以节省系统空间内存的消耗,而且环境切换大多在用户态完成。
缺点是显然的:复杂。
下面是M:N模型的示意图: 下面开始胡说八道了,说说Linux上的posix线程库实现。这个问题困扰我好长时间,从昨天开始才查了一大堆资料,囫囵理解了一些东西,可能bugs非常多的说
1, Linux上的posix线程库最初实现是n:1模型,就是没有OS支持的库实现。这也是狭义上的“LinuxPthreads”,它支持2.0及以后的Linux。Linux Kernel Mailing List FAQ上一位Hacker曾大大推崇这种方式,拿来与Solaries的1:1模型相比较并证明这种模型是优秀的。至少拿现在的情况来说他的观点是不正确的。这观点曾让偶糊涂了很久。
2, IBM公司实现的NGPT。它采用M:N模式,好象与第一种的LinuxPthreads合作工作。
3, NPTL。1:1模型。今后Linux平台的POSIX线程库事实上的标准实现。
在2002年8、9月份,一直不肯松劲的Linus Torvalds先生终于被说服了,Ingo Molnar把一些重要特性加入到2.5开发版官方内核中。这些特性大体包括:新的clone系统调用,TLS系统调用,posix线程间信号,exit_group(exit的一个变体),等等。有了OS的支持,Ingo Molnar先生同Ulrich Drepper(glibc的LinuxThreads库的维护者,NPTL的设计者与维护者,现工作于RedHat公司)和其他一些Hackers开始NPTL的完善工作。题外话一句:IBM公司给了他们很大的赞助。
在Linux上,可以用getconf GNU_LIBPTHREAD_VERSION来查看你的posix线程库到底是那一个实现,什么版本。Drepper先生做过测试,据他的测试数据,IA32机器上启动撤销10万个线程,以前的库实现需要15分钟,而NPTL只需要2s。
理论上应当是M:N模型最高效,但是Linux内核提供支持后,反倒是1:1模型的NPTL比M:N的NGPT好要快4倍!为什么会这样呢?目前偶只知道它把环境切换放到用户态了,别的不懂。
参考:
1。The Native POSIX Thread Library for Linux。Ulrich Drepper的亲笔大作,可以从http://people.redhat.com/drepper/nptl-design.pdf下载
2。POSIX多线程程序设计,David Butenhof,中国电力
3。Linux内核源代码情景分析。不用说了吧?
P.S. 我觉得《情景分析》有一个错误,作者在介绍进程时说:
红色部分显然是错误的。pthreads的必要行完全不能由内核线程取代。事实上,倘若这句话正确,pthreads就变成多余的了
- Linux上posix线程库实现原理讨论
- Linux上posix线程库实现原理讨论 .
- linux thread model . Linux上posix线程库实现原理讨论
- POSIX 线程取消点的 Linux 实现
- POSIX 线程取消点的 Linux 实现
- POSIX 线程取消点的 Linux 实现
- POSIX 线程取消点的 Linux 实现
- Linux POSIX线程实现wait_group功能
- POSIX线程库API(全)(上)
- Linux POSIX线程详解
- linux程序设计:POSIX线程
- 本地POSIX线程库(NPTL)(经典,说明了真实linux系统的实现)
- POSIX 线程取消点的 Linux 实现(zz)
- POSIX线程库
- posix线程库1
- posix线程库<一>
- linux的线程(posix thread)
- Linux Programing -- ch12-- POSIX 线程
- android简介
- 用 PHP 开发健壮的代码: 编写可重用函数
- 计算机系列经典书籍
- "当前不会命中断点。源代码与原始版本不同”的问题的有效解决办法
- jQuery-强大的jQuery选择器 (详解)
- Linux上posix线程库实现原理讨论
- 用 PHP 开发健壮的代码
- Reverse Proxy Web Sockets with Nginx and Socket.IO
- 仿baidu,google的查询分页技术
- .NET 与 COM 互操作原理
- 要做个工作事件备忘录了
- Java 生产者消费者问题
- 我们的爱,我理解
- 任务计划


