GOOGLE大学教程之Python字符串
来源:互联网 发布:装修淘宝店铺首页步骤 编辑:程序博客网 时间:2024/05/02 01:37
Python字符串
谷歌代码大学 > 编程语言
Python有一个内置的字符串类,名为“STR”与许多方便的功能(有一个名为“字符串”,你不应该使用的旧的模块)。双人床或单引号括字符串可以,虽然单引号是较为常用。反斜杠转义工作在单核和双引号的文字通常的方式 - 例如\ N \'\“(我没有做”,同样的单引号,双引号的字符串文字可以包含单引号,没有任何大惊小怪EG)。“字符串可以包含双引号字符串文字可以跨越多行,但必须有在每一行的末尾的反斜杠\逃脱三重引号内的字符串字面的换行符。,“”或''',可以多行文本。
Python字符串是“不可改变的”,这意味着他们不能改变后,他们创建(Java字符串也使用这种一成不变的风格)。由于字符串不能改变,我们构造*新*我们去代表计算值的字符串。因此,例如,表达式(“你好”+“中有”)2串'你好'和'有',并建立一个新的字符串“hellothere”。
字符串中的字符,可使用的标准[]语法,如Java和C + +,Python使用从零开始的索引,所以如果str是'你好'STR [1]是'E'。如果索引是字符串的界限,Python会引发一个错误。Python的风格(不像Perl)的停止,如果它不能告诉做什么,而不是正好弥补了默认值。也方便“片”的语法(下同)的作品,从字符串中提取任何的子串。LEN(字符串)函数返回一个字符串的长度。[]语法和LEN()函数实际上在任何序列类型 - 字符串,列表等。Python的尝试,其业务工作在不同类型中始终。Python的新手疑难杂症:不要使用“LEN”作为变量名,以避免阻塞len()函数。“+”操作符可以连接两个字符串。注意在下面的变量的代码没有预先宣布 - 只是分配给他们去。
= '您好' 打印的[ 1 ] #I 打印LEN () #2 打印小号+ “中有” ##您好
与Java不同,“+”不自动转换成数字或其他类型的字符串形式。str()函数的值转换成字符串的形式,使他们能够与其他字符串相结合。
PI = 3.14 ##文本='pi的值是“+ PI##没有,没有工作 文本= “pi的值是” + STR (PI ) ##是
对于数字,标准的运营商,+ / *,在通常的方式工作。有没有+ +操作符,但+ =,-=,等工作。如果你想整数除法,这是最正确的使用2斜线 - 如6 / / 5 1(以前的Python 3000,一个单/与整数的INT分工,但前进/ /是首选的方式来表示想要INT分工。)
“打印”操作员打印出一个或多个换行符(在项目结束时留下一个逗号抑制换行符)Python的项目。一个“R”和“原始”的字符串文字前缀,未经特殊处理的反斜杠传递所有的字符,通过,所以r'x \ NX“计算长度4串'X \ NX”。A“U”字头,让你写一个unicode字符串文字(Python有很多其他的Unicode支持功能 - 见下面的文档)。
原料= R '这个\ T \ n和“ 打印原料 #这\ T \ n和, 多= “”这是最好的时代 ,这是最坏的时代“。 “
字符串的方法
下面是一些最常见的字符串方法。一种方法是像一个函数,但它运行的“上”的对象。如果变量s是一个字符串,然后s.lower()的代码运行该字符串对象LOWER()的方法,并返回结果(这种方法在对象上运行的想法是对象的基本思路之一面向对象编程,面向对象)。下面是一些最常见的字符串方法:
- s.lower s.upper(),() - 返回字符串的小写或大写版本
- s.strip() - 返回一个空白字符串的开始和结束取消
- s.isalpha()/ s.isdigit()/ s.isspace ()... - 如果所有的字符串字符在各种字符类的测试
- s.startswith(“其他”),s.endswith(“其他”) - 测试,如果该字符串与其他字符串开始或结束
- s.find(“其他”) - 为给定的其他字符串(不是正则表达式)在S的搜索,并在那里开始的第一个索引或-1,如果没有找到返回
- s.replace('老','新') - 返回一个字符串出现的所有'老'已经由'新'取代
- s.split('DELIM“) - 返回一个给定的分隔符分隔的子字符串列表。delimiter不是正则表达式,它只是文字。“AAA,BBB,CCC'分裂(',') - > ['AAA','BBB','CCC']。作为一个方便的特殊情况下s.split()(不带参数)所有空白字符分割。
- s.join(名单) - split()的对面,加入在给定列表中的元素一起使用作为分隔符的字符串。如'---'.加入(['AAA','BBB','CCC']) - > AAA - BBB --- CCC
一个谷歌搜索“蟒蛇STR”应该引导你到官方python.org字符串的方法,它列出了所有的STR方法。
Python没有一个单独的字符类型。相反,这样的表情[8]返回一个字符串,长度为1包含的字符。与该字符串长度1,运营商==,<=,... ... 正如您所期望的所有工作,所以一般情况下,您并不需要知道,Python没有一个独立的标量“char”类型。
字符串片
“片”的语法是一种方便的方法是指序列的子部分 - 通常字符串和列表。切片[开始:结束]开始启动时,向上延伸,但不包括结束的元素。的假设,我们有S =“你好”
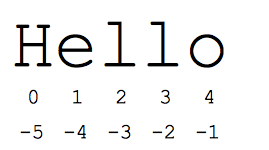
- [1:4] - “ELL”字符索引1处开始,向上延伸,但不包括指数4
- [1]是“ello” - 省略或者指数的默认字符串的开始或结束
- [:]是'你好' - 省略总是给我们的整个事情的副本(这是Python的方式来复制一个像一个字符串或列表序列)
- [1:100]是“ello” - 一个过大的指数,被截断的字符串的长度
标准的从零开始的索引号码方便地存取附近开始的字符串的字符。作为一种替代方法,Python使用负数容易获得的字符在字符串的结尾:[-1]是最后一个字符“O”,S [-2]是'L'下一个到最后CHAR,等等。负指数号码数从字符串的结尾:
- [-1]从最终是“O” - 最后一个字符(第1)
- [-4]“E” - 从年底的第四
- S [:-3]是'他' - 往上走,但不包括最后3个字符。
- [-3]“LLO” - 开始与结束的第三字符,并延伸到字符串的结尾。
这是一个片整齐不言而喻,对于任何指数n,S [:N] + [N] == S。这甚至n为负数或出界。或者把另一路S [:N]和S [N]总是分割成两部分字符串,节约所有的字符的字符串。正如我们将看到清单中的部分后,切片与列表。
字符串%
Python有一个printf()般的设施,把一个字符串。%操作符左侧(%ð INT,%s字符串%F /%G浮点),并在右边的一个元组的匹配值(一个元组是由一个printf类型的格式字符串分隔的值逗号,通常在括号内分组):
#%操作符的 文本= “%d的小猪出来,不然我就%s和%s和%s” % ( 3 , “一怒之下” , “噗” , “放空” )
上面一行是一种长 - 假设你要分解成单独的行。你不能只是拆分后的'%',你可能会在其他语言行,因为默认情况下,Python把每行作为一个单独的语句(加方,这就是为什么我们不需要上键入每个分号线)。为了解决这个问题,括在括号外的整个表达式 - 则表达式允许跨越多行。这行代码跨技术的工作原理与各分组构造详列如下:(),[],{}。
#添加括号,使长行的工作 :文本 = (“%ð三只小猪出来,不然我就%s和%s和%s “ % (3 ,“一怒之下“ ,“噗“ ,“放空 “ ))
i18n的字符串(UNICODE)
常规的Python字符串* * Unicode的,他们只是普通的字节。要创建一个Unicode字符串,字符串上使用的'U'前缀文字:
> ustring = U '的unicode \ u018e字符串\ XF1“ > ustring ü “一个unicode \ u018e字符串\ XF1”
一个unicode字符串是从普通的“STR”字符串对象的不同类型,但Unicode字符串兼容(它们共享的公共超类“basestring”),和各种库,如正则表达式的正常工作,如获通过,而不是一个Unicode字符串正常的字符串。
要转换一个unicode字符串的字节编码为“UTF - 8”等,调用ustring.encode(“UTF - 8”),Unicode字符串的方法。去其他方向,UNICODE(编码)功能转换成编码的纯字节的unicode字符串:
#(从上面unistring包含一个Unicode字符串)> S = unistring 。编码(“UTF - 8' )> S “的unicode \ XC6 \ x8e字符串\ XC3 \ xb1” #UTF - 8编码字节> T = UNICODE ( UTF - 8“ )#转换为字节的unicode字符串 > T == unistring #原,YAY!真正的
内置打印不完全与Unicode字符串。您可以编码()先打印在UTF - 8或其他。在文件阅读部分,有一个例子,显示如何打开一个文本文件,一些编码和读出的Unicode字符串。注意,Unicode处理Python 3000的是显著清理与Python 2.x的行为,这里描述的是一个面积。
如果声明
Python不使用{}括起来的代码块,如果/循环/功能等。相反,Python使用冒号(:)和缩进/空白组语句。这个词“ELIF”是相同长度字“:”为如果没有需要在括号内(从彗星+ + / Java的差异较大),和它可以有* elif的*和*其他*条款(助记符布尔测试其他“)。
作为一个测试,如果任何值都可以使用。“零”值全部为假计数:无,0,空字符串,空列表,空的字典。还有一个与布尔类型的两个值:True和False(转换为int,这些1和0)。Python有通常的比较操作:==,=,<,<=,>,> = Java和C不同,==重载,以正确处理字符串。布尔运算符列明字* * * *,*不*(Python不使用C风格的&&| |!)。这里的代码可能看起来像一个拉警察通过一个调速 - 注意每块then / else语句开始:和陈述其压痕分组:
如果速度> = 80 : 打印 '许可和登记,请 “ 如果心情== '可怕 ' 或速度> = 100 : 打印“你有权保持沉默。 “elif 的心情 =='坏 ' 或速度> = 90 : 打印 “我要去给你写一票。” write_ticket () 其他: 打印 “让我们尽量保持在80 OK?”
我觉得省略“:”是我最常见的语法错误,当输入在上面的代码排序,可能是因为这是一个额外的事情,与我的C + + / Java的习惯类型。另外,不要把中括号的布尔测试 - 这是一个C / JAVA的习惯。如果代码是短暂的,你可以在同一行上的代码“:”后,像这样(这也适用于功能,循环等方面也),虽然有些人觉得它的空间的东西在单独的行更具可读性。
如果速度> = 80 : 打印 “,以便破获” 其他: 打印 “有一个愉快的一天”
练习:string1.py
为了实践在本节中的材料,尝试 string1.py在行使基本练习 。
- GOOGLE大学教程之Python字符串
- GOOGLE Python大学教程之Python排序
- GOOGLE Python大学教程之Python的dict和文件
- GOOGLE Python大学课程之Python列表
- 读书记之《Unix&Linux大学教程》
- Python基础学习教程(一)之字符串的秘密
- Python基础学习教程(三)之字符串的秘籍
- 简明python教程学习笔记之十-DocStrings文档字符串
- 廖雪峰python教程阅读之字符串和编码
- Python学习教程(三)——序列之字符串
- 大学教程
- 大学教程
- google app engine简明教程---Python版
- Python 教程之零
- 【Python教程】python之路
- 数据结构大学教程之数据结构及其基本概念(1)
- 数据结构大学教程之数据结构及其基本概念(2)
- python之字符串处理
- 开心一刻
- 采用win32函数对文件的基本操作
- 默认情况下GC在服务器上回收中断时间太长.
- 修鞋师称马英九鞋子均修五六次才换鞋
- 通讯录开发学习4
- GOOGLE大学教程之Python字符串
- eclipse用cygwin提供的linux环境开发C++
- 深入浅出URL编码
- 希尔排序算法
- JQuery - live函数
- MySQL 用户及用户权限管理
- SOA基础概念【整理中】
- 配置sql server 2000以允许远程访问
- instantclient连接DB的操作记录


