Hadoop中Map任务的执行框架
来源:互联网 发布:淘宝助理导出csv出错 编辑:程序博客网 时间:2024/05/01 12:30
在前面的一片博文中,我重点讲述了Task被TaskTracker调度执行的原理及过程,但是在详细的介绍执行Task的过程细节之前,我想先来认真的讨论一下Map Task和Reduce Task的执行框架。当然本文主要集中在Map Task上,至于Reduce Task的相关内容,我会在下一篇博文中谈到。在这篇文章中,我将尽量给出一个最抽象的Map模型
在Hadoop的MapRduce中,Map任务最重是交给Map任务执行器org.apache.hadoop.mapreduce.Mapper来执行的,在底层必定会采用JDK的泛型编程的。还是来了解一下与Map任务执行器相关的Mapper类吧。

对于上面与Map任务执行框架相关的类,我想我不得不详细的解释一下。任何Map任务在Hadoop中都会被一个MapTask对象所详细描述,MapTask会最终调用Mapper的run方法来执行它对应的Map任务,当然Mapper要执行Map任务,就必须要有相关的所有输入输出信息,而这些信息都包含在了Map任务对应的Context中了,也就是说Mapper从Context中获得一系列的输入数据记录,然后又将这些处理后的记录写入Context中,同时输入、输出的数据格式都是交由用户来实现/设置的。那么,Context的输入数据有来自哪个地方,又将处理后的数据写往何处呢?其实,Context是通过RecordReader来获取输入数据,通过RecordWriter保存被Mapper处理后的数据。至此,Map任务的真个执行框架我们可以这样来抽象:

关于上面我抽象出来的这个Map任务执行框架,还需要补充的是,在Map任务对应的上下文执行环境Context中有个任务报告器TaskReporter,它被用来不断的向这个Map任务的TaskTracker报告任务的执行进度(这个精度只是一个估计值,不一定很准确)。另外,有人可能会问这个Map任务的输入文件和结果输出文件的有关信息Context是如何获悉的?其实,Map任务的输入文件文件保存在InputSplit中,这个InputSplit保存了文件的路径、范围、位置;Map任务的输出文件信息是在执行过程中动态生成的,因为Map任务的结果输出实际上就是Reduce任务的输入,它相当于只是全局作业中的一个中间过程,所以这个Map任务的输出结果的保存对于用户来说是透明的,而用户往往也只关心Reduce任务的最后汇总结果。
下面再来看看这个框架具体的执行步骤:
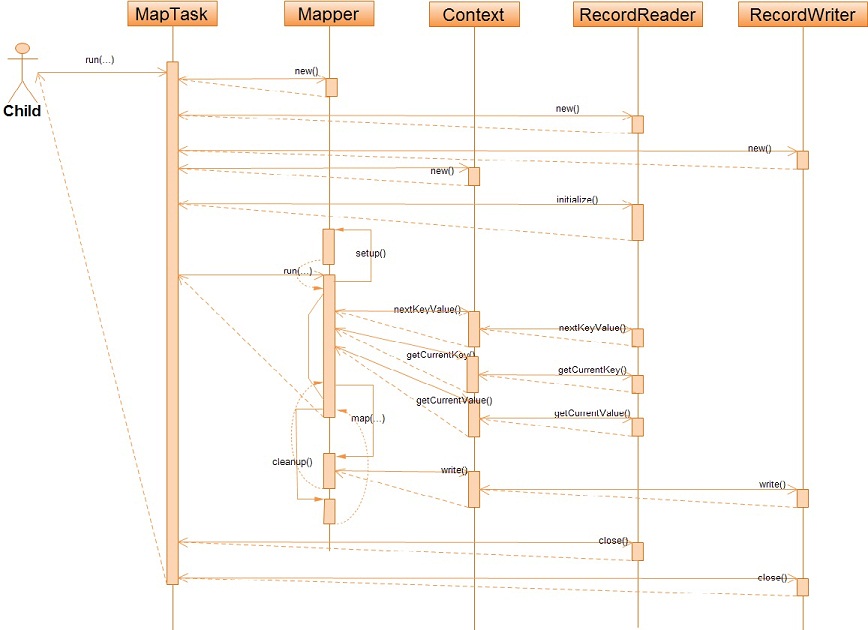
本文所介绍的只是抽象的Map任务执行框架,至于MapReduce内部是如何具体实现的,我还会在以后进行详细的阐述。(上文都是本人的一些个人见解,若有不当或错误之处尽请指出,以便帮助我学习进步,谢谢!)
- Hadoop中Map任务的执行框架
- Hadoop中Map任务的执行框架
- Hadoop中Reduce任务的执行框架
- Hadoop中Reduce任务的执行框架
- hadoop的map和reduce任务的执行步骤
- Hadoop的MapReduce框架中map和reduce的各自任务(能力工场--整理)
- Hadoop对Map执行框架的实现(客户端)
- Hadoop对Map执行框架的实现(TaskTracker端)
- 如何控制hadoop中map和reduce任务的数量
- 如何在Hadoop中控制Map&Reduce任务的数量
- hadoop任务的执行过程
- 【hadoop】 4004-Hadoop-2.4.1 版本中map任务待处理split大小的计算方法
- 浅析Hadoop中MapReduce任务执行流程
- hadoop mapreduce任务中,map任务数的确定
- map-reduce任务的执行流程
- hadoop的mapreduce任务的执行流程
- Hadoop的map任务和reduce任务的数量
- Hadoop 任务执行方面的优化
- ios简单使用core data
- C语言库函数
- 网页设计的发展历史
- java.lang.IllegalMonitorStateException
- C语言——运算符优先级问题
- Hadoop中Map任务的执行框架
- int main(int argc,char* argv[])详解
- red5源码分析(转)
- struts2 action执行2次
- 流量数据API使用说明
- Building UCSniff on Fedora
- 嵌入式经典面试题
- 嵌入式软件工程师笔试题(含答案)
- TIdTCPClient 详解


