linux下tc、htb、iptables基础知识及openwrt 下qos使用介绍
来源:互联网 发布:ubuntu怎么卸载软件 编辑:程序博客网 时间:2024/04/30 04:29
htb基础知识:Linux Htb队列规定指南中文版:http://wenku.baidu.com/view/64da046825c52cc58bd6beac.html
TC基础知识:Linux 的高级路由和流量控制LARTChttp://download.csdn.net/detail/wuwentao2000/3963140
iptables基础知识: 中文howto:http://man.chinaunix.net/network/iptables-tutorial-cn-1.1.19.html
来源一:http://www.right.com.cn/forum/viewthread.php?tid=71981&highlight=QOS
#现在开始用TC建立数据的上行和下行通道
TCA="tc class add dev br0"
TFA="tc filter add dev br0"
tc qdisc del dev br0 root
tc qdisc add dev br0 root handle 1: htb
tc class add dev br0 parent 1: classid 1:1 htb rate 1600kbit #这个1600是下行总速度
$TCA parent 1:1 classid 1:10 htb rate 200kbit ceil 400kbit prio 2 #这个是10号通道的下行速度,最小200,最大400,优先级为2
$TCA parent 1:1 classid 1:25 htb rate 1000kbit ceil 1600kbit prio 1 #这是我自己使用的特殊25号通道,下行速度最小1000,最大1600,优先级为1, 呵呵,待遇就是不一样
$TFA parent 1:0 prio 2 protocol ip handle 10 fw flowid 1:10
$TFA parent 1:0 prio 1 protocol ip handle 25 fw flowid 1:25
tc qdisc add dev br0 ingress
$TFA parent ffff: protocol ip handle 35 fw police rate 800kbit mtu 12k burst 10k drop #这是我自己使用的35号上行通道,最大速度800
$TFA parent ffff: protocol ip handle 50 fw police rate 80kbit mtu 12k burst 10k drop #这是给大伙使用的50号上行通道,最大速度80
#好了,现在用iptables来觉得哪些人走哪些通道吧,哈哈,由于dd wrt的iptables不支持ip range,所以只能每个IP写一条语句,否则命令无效
iptables -t mangle -A POSTROUTING -d 192.168.1.22 -j MARK --set-mark 10 #ip为192.168.1.22的走10号通道
iptables -t mangle -A POSTROUTING -d 192.168.1.22 -j RETURN #给每条规则加入RETURN,这样效率会更高.
iptables -t mangle -A POSTROUTING -d 192.168.1.23 -j MARK --set-mark 25 #ip为192.168.1.23的走25号特殊通道,23是我的ip,所以特殊点
iptables -t mangle -A POSTROUTING -d 192.168.1.23 -j RETURN #给每条规则加入RETURN,这样效率会更高.
iptables -t mangle -A PREROUTING -s 192.168.1.22 -j MARK --set-mark 50 #ip为22的走50号上行通道
iptables -t mangle -A PREROUTING -s 192.168.1.22 -j RETURN #给每条规则加入RETURN,这样效率会更高.
iptables -t mangle -A PREROUTING -s 192.168.1.23 -j MARK --set-mark 35 #ip为23的走35号上行通道,我自己的IP.呵呵
iptables -t mangle -A PREROUTING -s 192.168.1.23 -j RETURN #给每条规则加入RETURN,这样效率会更高.
#其他的我就不写了,大家自己换IP吧,想让谁走哪个通道,就把IP改了执行,现在发发慈悲,让大家开网页的时候走我使用25和35号通道吧,当然你也可以不发慈悲
iptables -t mangle -A PREROUTING -p tcp -m tcp --dport 80 -j MARK --set-mark 35 #http的端口号80,所以dport是80,这是发起http请求的时候
iptables -t mangle -A PREROUTING -p tcp -m tcp --dport 80 -j RETURN
iptables -t mangle -A POSTROUTING -p tcp -m tcp --sport 80 -j MARK --set-mark 25 #http的端口号80,所以sport是80,这是http响应回来的时候
iptables -t mangle -A POSTROUTING -p tcp -m tcp --sport 80 -j RETURN
-------------------------
现在来看看如何限制TCP和UDP的连接数吧,很NB的(不知道标准版本和简化版是否支持,一下语句不保证可用,因个人路由器环境而定):
iptables -I FORWARD -p tcp -m connlimit --connlimit-above 100 -j DROP #看到了吧,在FORWARD转发链的时候,所有tcp连接大于100 的数据包就丢弃!是针对所有IP的限制
iptables -I FORWARD -p udp -m limit --limit 5/sec -j DROP #UDP是无法控制连接数的, 只能控制每秒多少个UDP包, 这里设置为每秒5个,5个已经不少了,10个就算很高了,这个是封杀P2P的利器,一般设置为每秒3~5个比较合理.
如何查看命令是否生效呢?:
执行 iptables -L FORWARD 就可以看到如下结果:
DROP tcp -- anywhere anywhere #conn/32 > 100
DROP udp -- anywhere anywhere limit: avg 5/sec bu
如果出现了这2个结果,说明限制连接数的语句确实生效了, 如果没有这2个出现,则说明你的dd-wrt不支持connlimit限制连接数模块.
现在我想给自己开个后门,不受连接数的限制该怎么做呢?看下面的:
iptables -I FORWARD -s 192.168.1.23 -j RETURN #意思是向iptables的FORWARD链的最头插入这个规则,这个规则现在成为第一个规则了,23是我的IP,就是说,只要是我的IP的就不在执行下面的连接数限制的规则语句了,利用了iptables链的执行顺序规则,我的IP被例外了.
告诉大家一个查看所有人的连接数的语句:
sed -n 's%.* src=\(192.168.[0-9.]*\).*%\1%p' /proc/net/ip_conntrack | sort | uniq -c #执行这个就可以看到所有IP当前所占用的连接数
对于上面的脚本,有一些比较疑惑人的地方,现在来讲讲:
br0 : 这个是一个dd wrt的网桥, 这个网桥桥接了无线和有线的接口, 所以在这上面卡流量,就相当于卡了所有无线和有线的用户.具体信息可以输入ifconfig命令进行查看.
规则链顺序问题 : 在br0上iptables规则链的顺序是比较奇怪的, 正常的顺序 入站的数据包先过 PERROUTING链, 出站数据包先过POSTROUTING链,但是 dd wrt的br0网桥顺序与正常的顺序正好相反!
在ddwrt上入站的数据包被当成出站的,出站的数据包被当成入站的,所以上面的脚本会那么写.
不会不知道在哪里敲命令吧?
登陆ddwrt的web管理界面 ,管理里面, 开启SSH
用SSH CLIENT ,这里下载 : http://www.onlinedown.net/soft/20089.htm
输入路由器IP,用户密码,登陆,开始敲吧.
重要提醒: 大家要用ue这样的编辑器来写脚本,这样的编辑器才支持unix格式,windows下的记事本是不行的,因为这2个系统的换行符不一样,unix/linux下不认
-----------------------
来源二:http://www.right.com.cn/forum/thread-53500-1-1.html
很多人说OP的QOS不好用,开始我也是这么觉得的 。开了BT PPS 之类的根本没法干别的 ,游戏就更别提了。
但是很多人像我一样, 有脱机下载或者NAS下载之类的,也或者想最大效率利用带宽,同时游戏,上网,看视频,开BT,迅雷。为了完成这个想法,经过一段时间的努力,查阅了N多的QOS资料,目标基本实现了。兴奋之余,把大致的实现方法介绍给大家,动手能力强的可以作为参考。要完成自定义QOS,需要先把tc,iptable, htb算法, opendpi , xt_recent 这些都搞清楚,起码基本的命令都会用。否则就看看热闹好了。
命令很多人都懂,我就主要讲下思路。tc的流量控制很准确,前提是要对tc,htb有足够的了解。htb的分类主要以openwrt原版qos为基础,上传增加一个第五类。iptables的设置,也是以openwrt的原版为基础,将l7-filter换成opendpi作七层识别,并作了一些小改动来符合我的需求。
上传
1: root htb
|
1:1
/ / \
1:10 1:20 1:3
/ \ \
1:30 1:40 1:50
tc qdisc add dev eth1 root handle 1: htb default 40
tc class add dev eth1 parent 1: classid 1:1 htb rate 58kbps ceil 58kbps burst 5k cburst 5k
tc class add dev eth1 parent 1:1 classid 1:10 htb rate 10kbps ceil 58kbps prio 1
tc class add dev eth1 parent 1:1 classid 1:20 htb rate 15kbps ceil 58kbps prio 2
tc class add dev eth1 parent 1:1 classid 1:3 htb rate 15kbps ceil 45kbps
tc class add dev eth1 parent 1:3 classid 1:30 htb rate 10kbps ceil 45kbps prio 3 burst 2k cburst 2k
tc class add dev eth1 parent 1:3 classid 1:40 htb rate 5kbps ceil 45kbps prio 4
tc class add dev eth1 parent 1:3 classid 1:50 htb rate 5kbps ceil 45kbps prio 5
这是上传500kbit带宽的分类情况, 1:10是游戏, 1:20是dns, tcp syn,tcp ack ,ssh,QQ语音之类的, 1:30是网页、vpn、代理、rdp,1:40是BT,迅雷,PPS和其他未分类,包大小小于300的流量,1:50是BT,迅雷,PPS和未分类,包大小大于300的流量。
下载也作了tc和iptable的配置,不过相对来说没那么重要,就不帖了。主要思路跟上传差不多,没用imq而是用了ifb模块,也就是上传和下载都在同一个interface(即出口)上整形。好像ifb是在iptable之前,具体有空测试一下,所以iptable对下行来说也不重要了,但对于七层识别还是有点用,所以也加上了,openwrt的原版QOS在iptable中是不对下行作mark的。
按这个速率设定来用的话,开下载的同时,游戏的延迟是可以保证的。当然最重要的是在iptable 上把流量用mark分好类,我的分类是按端口和七层识别同时用,比如22,80,53都可以按端口来设,虽然有些应用也会用这些端口,但一般没多大影响。除非有特意改端口的,有影响了,那可以都用七层识别来做。opendpi在七层识别方面还是不错的,openwrt的开发者在几个月前已经开始计划用opendpi换掉l7-filter,不知道最近进展如何。不过我们可以自己编译到openwrt里。
另外,很多QOS的设定都会推荐限制连接数,我没有做方面的限制,至少在我这里没有什么问题。测试3M下行,500k上行的时候迅雷开了3个种子,基本满速,上行还有富余,游戏延迟没问题,QQ语音同时连3个人流畅。 测试20M下行,1M上行的时候,迅雷开20个种子,下行不满速,上行已经满了,迅雷上传显示0,游戏延迟没问题,QQ语音同时连3个人流畅。
因为我玩DOTA经常上浩方,所以自己分析了浩方的数据包特征,CS,WAR3都能匹配,最近去11平台玩DOTA,也分析了下,可以匹配了。opendpi对PPS支持很好,QQ需要修改匹配方法。迅雷和风行这种,只是部分能有些特征包,已经足够了,可以配合recent来mark,要改recent模块。
本来想贴几个图,想想没什么意义。如果有人感兴趣,可以联系我,帮忙写个脚本。
最后贴下iptable的统计信息。其中war3的匹配都在下行里,这里看不到,帖子长度的问题,就不贴了。
上行:
Chain Default (2 references)
pkts bytes target prot opt in out source destination
41447462 17211275535 CONNMARK all -- * * 0.0.0.0/0 0.0.0.0/0 CONNMARK restore
11384650 1499982652 Default_ct all -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x0
34 23446 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x1 length 400:65535 MARK and 0x0
24641 20134127 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x2 length 800:65535 MARK and 0x0
37746 5394916 MARK icmp -- * * 0.0.0.0/0 0.0.0.0/0 MARK set 0x1
2077725 101041304 MARK tcp -- * * 0.0.0.0/0 0.0.0.0/0 length 0:128 mark match !0x4 tcp flags:0x3F/0x02 MARK set 0x2
1418481 59188992 MARK tcp -- * * 0.0.0.0/0 0.0.0.0/0 length 0:128 mark match !0x4 tcp flags:0x3F/0x10 MARK set 0x2
6699462 697530975 MARK udp -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x0 length 0:65535 MARK set 0x4
896620 621880446 MARK tcp -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x0 length 0:65535 MARK set 0x4
2822843 3713061114 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x4 length 300:65535 MARK set 0x5
Chain Default_ct (1 references)
pkts bytes target prot opt in out source destination
379 18200 MARK tcp -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x0 tcp multiport ports 22,53 MARK set 0x2
27432 1704319 MARK udp -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x0 udp multiport ports 22,53 MARK set 0x2
144061 7137731 MARK tcp -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x0 tcp multiport ports 20,21,25,80,110,443,993,995,5190,3389,3390,5900,1080,1194 MARK set 0x3
364 23960 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x0 protocol HF MARK set 0x1
1 45 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x0 protocol COUNTERSTRIKE MARK set 0x1
0 0 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x0 protocol WARCRAFT3 MARK set 0x1
966 51955 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x0 protocol PT11 MARK set 0x1
174 31318 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x0 protocol QQ MARK set 0x2
727 256830 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x0 protocol HTTP MARK set 0x3
753 102156 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x0 protocol PPStream MARK set 0x4
0 0 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x0 protocol PPLive MARK set 0x4
683701 50272737 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x0 protocol Bittorrent MARK set 0x4
4534 268934 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x0 protocol Thunder/Webthunder MARK set 0x8
103919 7200135 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x0 recent: UPDATE seconds: 60 name: DEFAULT side:source port MARK set 0x4
4534 268934 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 mark match 0x8 recent: SET name: DEFAULT side:source port MARK set 0x4
11384650 1499982652 CONNMARK all -- * * 0.0.0.0/0 0.0.0.0/0 CONNMARK save
在Openwrt上自定义QOS
来源3:HTB HOME:http://luxik.cdi.cz/~devik/qos/htb/
HTB Linux queuing discipline manual - user guide
Manual: devik and Don Cohen
Last updated: 5.5.2002
New text is in red color. Coloring is removed on new text after 3 months. Currently they depicts HTB3 changes
- 1. Introduction
- 2. Link sharing
- 3. Sharing hierarchy
- 4. Rate ceiling
- 5. Burst
- 6. Priorizing bandwidth share
- 7. Understanding statistics
- 8. Making, debugging and sending error reports
1. Introduction
HTB is meant as a more understandable, intuitive and faster replacement for the CBQ qdisc in Linux. Both CBQ and HTB help you to control the use of the outbound bandwidth on a given link. Both allow you to use one physical link to simulate several slower links and to send different kinds of traffic on different simulated links. In both cases, you have to specify how to divide the physical link into simulated links and how to decide which simulated link to use for a given packet to be sent.This document shows you how to use HTB. Most sections have examples, charts (with measured data) and discussion of particular problems.
This release of HTB should be also much more scalable. See comparison at HTB home page.
Please read: tc tool (not only HTB) uses shortcuts to denote units of rate. kbps means kilobytes and kbit means kilobits ! This is the most FAQ about tc in linux.
2. Link sharing
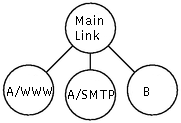 Problem: We have two customers, A and B, both connected to the internet via eth0. We want to allocate 60 kbps to B and 40 kbps to A. Next we want to subdivide A's bandwidth 30kbps for WWW and 10kbps for everything else. Any unused bandwidth can be used by any class which needs it (in proportion of its allocated share).
Problem: We have two customers, A and B, both connected to the internet via eth0. We want to allocate 60 kbps to B and 40 kbps to A. Next we want to subdivide A's bandwidth 30kbps for WWW and 10kbps for everything else. Any unused bandwidth can be used by any class which needs it (in proportion of its allocated share).HTB ensures that the amount of service provided to each class is at least the minimum of the amount it requests and the amount assigned to it. When a class requests less than the amount assigned, the remaining (excess) bandwidth is distributed to other classes which request service.
Also see document about HTB internals - it describes goal above in greater details.
Note: In the literature this is called "borrowing" the excess bandwidth. We use that term below to conform with the literature. We mention, however, that this seems like a bad term since there is no obligation to repay the resource that was "borrowed".
The different kinds of traffic above are represented by classes in HTB. The simplest approach is shown in the picture at the right.
Let's see what commands to use:
tc qdisc add dev eth0 root handle 1: htb default 12This command attaches queue discipline HTB to eth0 and gives it the "handle" 1:. This is just a name or identifier with which to refer to it below. The default 12 means that any traffic that is not otherwise classified will be assigned to class 1:12.
Note: In general (not just for HTB but for all qdiscs and classes in tc), handles are written x:y where x is an integer identifying a qdisc and y is an integer identifying a class belonging to that qdisc. The handle for a qdisc must have zero for its y value and the handle for a class must have a non-zero value for its y value. The "1:" above is treated as "1:0".
tc class add dev eth0 parent 1: classid 1:1 htb rate 100kbps ceil 100kbps tc class add dev eth0 parent 1:1 classid 1:10 htb rate 30kbps ceil 100kbpstc class add dev eth0 parent 1:1 classid 1:11 htb rate 10kbps ceil 100kbpstc class add dev eth0 parent 1:1 classid 1:12 htb rate 60kbps ceil 100kbps
The first line creates a "root" class, 1:1 under the qdisc 1:. The definition of a root class is one with the htb qdisc as its parent. A root class, like other classes under an htb qdisc allows its children to borrow from each other, but one root class cannot borrow from another. We could have created the other three classes directly under the htb qdisc, but then the excess bandwidth from one would not be available to the others. In this case we do want to allow borrowing, so we have to create an extra class to serve as the root and put the classes that will carry the real data under that. These are defined by the next three lines. The ceil parameter is described below.
Note: Sometimes people ask me why they have to repeat dev eth0 when they have already used handle or parent. The reason is that handles are local to an interface, e.g., eth0 and eth1 could each have classes with handle 1:1.
We also have to describe which packets belong in which class. This is really not related to the HTB qdisc. See the tc filter documentation for details. The commands will look something like this:
tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 \ match ip src 1.2.3.4 match ip dport 80 0xffff flowid 1:10tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 \ match ip src 1.2.3.4 flowid 1:11(We identify A by its IP address which we imagine here to be 1.2.3.4.)
Note: The U32 classifier has an undocumented design bug which causes duplicate entries to be listed by "tc filter show" when you use U32 classifiers with different prio values.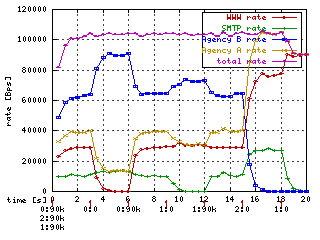
You may notice that we didn't create a filter for the 1:12 class. It might be more clear to do so, but this illustrates the use of the default. Any packet not classified by the two rules above (any packet not from source address 1.2.3.4) will be put in class 1:12.
Now we can optionally attach queuing disciplines to the leaf classes. If none is specified the default is pfifo.
tc qdisc add dev eth0 parent 1:10 handle 20: pfifo limit 5tc qdisc add dev eth0 parent 1:11 handle 30: pfifo limit 5tc qdisc add dev eth0 parent 1:12 handle 40: sfq perturb 10That's all the commands we need. Let's see what happens if we send packets of each class at 90kbps and then stop sending packets of one class at a time. Along the bottom of the graph are annotations like "0:90k". The horizontal position at the center of the label (in this case near the 9, also marked with a red "1") indicates the time at which the rate of some traffic class changes. Before the colon is an identifier for the class (0 for class 1:10, 1 for class 1:11, 2 for class 1:12) and after the colon is the new rate starting at the time where the annotation appears. For example, the rate of class 0 is changed to 90k at time 0, 0 (= 0k) at time 3, and back to 90k at time 6.
Initially all classes generate 90kb. Since this is higher than any of the rates specified, each class is limited to its specified rate. At time 3 when we stop sending class 0 packets, the rate allocated to class 0 is reallocated to the other two classes in proportion to their allocations, 1 part class 1 to 6 parts class 2. (The increase in class 1 is hard to see because it's only 4 kbps.) Similarly at time 9 when class 1 traffic stops its bandwidth is reallocated to the other two (and the increase in class 0 is similarly hard to see.) At time 15 it's easier to see that the allocation to class 2 is divided 3 parts for class 0 to 1 part for class 1. At time 18 both class 1 and class 2 stop so class 0 gets all 90 kbps it requests.
It might be good time to touch concept of quantums now. In fact when more classes want to borrow bandwidth they are each given some number of bytes before serving other competing class. This number is called quantum. You should see that if several classes are competing for parent's bandwidth then they get it in proportion of their quantums. It is important to know that for precise operation quantums need to be as small as possible and larger than MTU.
Normaly you don't need to specify quantums manualy as HTB chooses precomputed values. It computes classe's quantum (when you add or change it) as its rate divided by r2q global parameter. Its default value is 10 and because typical MTU is 1500 the default is good for rates from 15 kBps (120 kbit). For smaller minimal rates specify r2q 1 when creating qdisc - it is good from 12 kbit which should be enough. If you will need you can specify quantum manualy when adding or changing the class. You can avoid warnings in log if precomputed value would be bad. When you specify quantum on command line the r2q is ignored for that class.
This might seem like a good solution if A and B were not different customers. However, if A is paying for 40kbps then he would probably prefer his unused WWW bandwidth to go to his own other service rather than to B. This requirement is represented in HTB by the class hierarchy.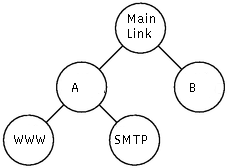
3. Sharing hierarchy
The problem from the previous chapter is solved by the class hierarchy in this picture. Customer A is now explicitly represented by its own class. Recall from above thatthe amount of service provided to each class is at least the minimum of the amount it requests and the amount assigned to it. This applies to htb classes that are not parents of other htb classes. We call these leaf classes. For htb classes that are parents of other htb classes, which we call interior classes, the rule is that the amount of service is at least the minumum of the amount assigned to it and the sum of the amount requested by its children. In this case we assign 40kbps to customer A. That means that if A requests less than the allocated rate for WWW, the excess will be used for A's other traffic (if there is demand for it), at least until the sum is 40kbps.Notes: Packet classification rules can assign to inner nodes too. Then you have to attach other filter list to inner node. Finally you should reach leaf or special 1:0 class. The rate supplied for a parent should be the sum of the rates of its children.
The commands are now as follows:
tc class add dev eth0 parent 1: classid 1:1 htb rate 100kbps ceil 100kbpstc class add dev eth0 parent 1:1 classid 1:2 htb rate 40kbps ceil 100kbpstc class add dev eth0 parent 1:2 classid 1:10 htb rate 30kbps ceil 100kbpstc class add dev eth0 parent 1:2 classid 1:11 htb rate 10kbps ceil 100kbpstc class add dev eth0 parent 1:1 classid 1:12 htb rate 60kbps ceil 100kbps
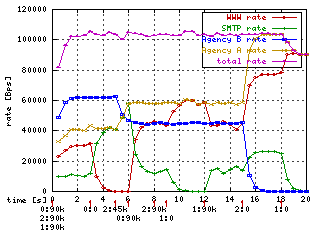
We now turn to the graph showing the results of the hierarchical solution. When A's WWW traffic stops, its assigned bandwidth is reallocated to A's other traffic so that A's total bandwidth is still the assigned 40kbps.
If A were to request less than 40kbs in total then the excess would be given to B.
4. Rate ceiling
The ceil argument specifies the maximum bandwidth that a class can use. This limits how much bandwidth that class can borrow. The default ceil is the same as the rate. (That's why we had to specify it in the examples above to show borrowing.) We now change the ceil 100kbps for classes 1:2 (A) and 1:11 (A's other) from the previous chapter to ceil 60kbps and ceil 20kbps.The graph at right differs from the previous one at time 3 (when WWW traffic stops) because A/other is limited to 20kbps. Therefore customer A gets only 20kbps in total and the unused 20kbps is allocated to B.
The second difference is at time 15 when B stops. Without the ceil, all of its bandwidth was given to A, but now A is only allowed to use 60kbps, so the remaining 40kbps goes unused.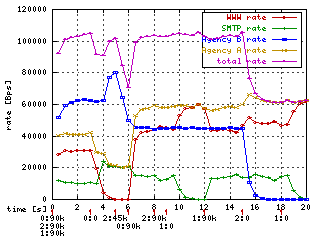
This feature should be useful for ISPs because they probably want to limit the amount of service a given customer gets even when other customers are not requesting service. (ISPs probably want customers to pay more money for better service.) Note that root classes are not allowed to borrow, so there's really no point in specifying a ceil for them.
Notes: The ceil for a class should always be at least as high as the rate. Also, the ceil for a class should always be at least as high as the ceil of any of its children.
5. Burst
Networking hardware can only send one packet at a time and only at a hardware dependent rate. Link sharing software can only use this ability to approximate the effects of multiple links running at different (lower) speeds. Therefore the rate and ceil are not really instantaneous measures but averages over the time that it takes to send many packets. What really happens is that the traffic from one class is sent a few packets at a time at the maximum speed and then other classes are served for a while. The burst and cburst parameters control the amount of data that can be sent at the maximum (hardware) speed without trying to serve another class.If cburst is smaller (ideally one packet size) it shapes bursts to not exceed ceil rate in the same way as TBF's peakrate does.
When you set burst for parent class smaller than for some child then you should expect the parent class to get stuck sometimes (because child will drain more than parent can handle). HTB will remember these negative bursts up to 1 minute.
You can ask why I want bursts. Well it is cheap and simple way how to improve response times on congested link. For example www traffic is bursty. You ask for page, get it in burst and then read it. During that idle period burst will "charge" again.
Note: The burst and cburst of a class should always be at least as high as that of any of it children.
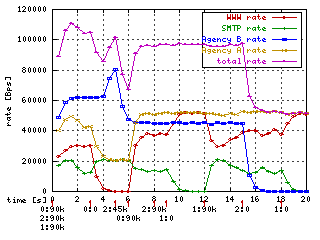 On graph you can see case from previous chapter where I changed burst for red and yellow (agency A) class to 20kb but cburst remained default (cca 2 kb).
On graph you can see case from previous chapter where I changed burst for red and yellow (agency A) class to 20kb but cburst remained default (cca 2 kb).
Green hill is at time 13 due to burst setting on SMTP class. A class. It has underlimit since time 9 and accumulated 20 kb of burst. The hill is high up to 20 kbps (limited by ceil because it has cburst near packet size).
Clever reader can think why there is not red and yellow hill at time 7. It is because yellow is already at ceil limit so it has no space for furtner bursts.
There is at least one unwanted artifact - magenta crater at time 4. It is because I intentionaly "forgot" to add burst to root link (1:1) class. It remembered hill from time 1 and when at time 4 blue class wanted to borrow yellow's rate it denied it and compensated itself.
Limitation: when you operate with high rates on computer with low resolution timer you need some minimal burst and cburst to be set for all classes. Timer resolution on i386 systems is 10ms and 1ms on Alphas. The minimal burst can be computed as max_rate*timer_resolution. So that for 10Mbit on plain i386 you needs burst 12kb.
If you set too small burst you will encounter smaller rate than you set. Latest tc tool will compute and set the smallest possible burst when it is not specified.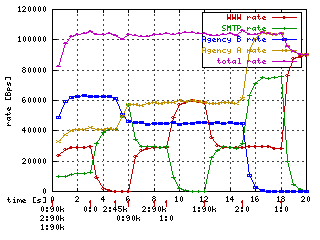
6. Priorizing bandwidth share
Priorizing traffic has two sides. First it affects how the excess bandwidth is distributed among siblings. Up to now we have seen that excess bandwidth was distibuted according to rate ratios. Now I used basic configuration from chapter 3 (hierarchy without ceiling and bursts) and changed priority of all classes to 1 except SMTP (green) which I set to 0 (higher).From sharing view you see that the class got all the excess bandwidth. The rule is that classes with higher priority are offered excess bandwidth first. But rules about guaranted rate and ceil are still met.
There is also second face of problem. It is total delay of packet. It is relatively hard to measure on ethernet which is too fast (delay is so neligible). But there is simple help. We can add simple HTB with one class rate limiting to less then 100 kbps and add second HTB (the one we are measuring) as child. Then we can simulate slower link with larger delays.
For simplicity sake I use simple two class scenario:
# qdisc for delay simulationtc qdisc add dev eth0 root handle 100: htbtc class add dev eth0 parent 100: classid 100:1 htb rate 90kbps# real measured qdisctc qdisc add dev eth0 parent 100:1 handle 1: htbAC="tc class add dev eth0 parent"$AC 1: classid 1:1 htb rate 100kbps$AC 1:2 classid 1:10 htb rate 50kbps ceil 100kbps prio 1$AC 1:2 classid 1:11 htb rate 50kbps ceil 100kbps prio 1tc qdisc add dev eth0 parent 1:10 handle 20: pfifo limit 2tc qdisc add dev eth0 parent 1:11 handle 21: pfifo limit 2
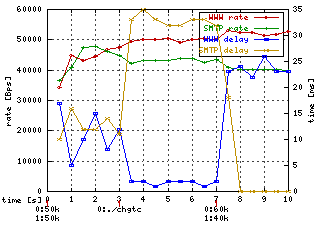 Note: HTB as child of another HTB is NOT the same as class under another class within the same HTB. It is because when class in HTB can send it will send as soon as hardware equipment can. So that delay of underlimit class is limited only by equipment and not by ancestors.
Note: HTB as child of another HTB is NOT the same as class under another class within the same HTB. It is because when class in HTB can send it will send as soon as hardware equipment can. So that delay of underlimit class is limited only by equipment and not by ancestors.In HTB under HTB case the outer HTB simulates new hardware equipment with all consequences (larger delay)
Simulator is set to generate 50 kbps for both classes and at time 3s it executes command:
tc class change dev eth0 parent 1:2 classid 1:10 htb \ rate 50kbps ceil 100kbps burst 2k prio 0As you see the delay of WWW class dropped nearly to the zero while SMTP's delay increased. When you priorize to get better delay it always makes other class delays worse.
Later (time 7s) the simulator starts to generate WWW at 60 kbps and SMTP at 40 kbps. There you can observe next interesting behaviour. When class is overlimit (WWW) then HTB priorizes underlimit part of bandwidth first.
What class should you priorize ? Generaly those classes where you really need low delays. The example could be video or audio traffic (and you will really need to use correct rate here to prevent traffic to kill other ones) or interactive (telnet, SSH) traffic which is bursty in nature and will not negatively affect other flows.
Common trick is to priorize ICMP to get nice ping delays even on fully utilized links (but from technical point of view it is not what you want when measuring connectivity).
7. Understanding statistics
The tc tool allows you to gather statistics of queuing disciplines in Linux. Unfortunately statistic results are not explained by authors so that you often can't use them. Here I try to help you to understand HTB's stats.First whole HTB stats. The snippet bellow is taken during simulation from chapter 3.
# tc -s -d qdisc show dev eth0 qdisc pfifo 22: limit 5p Sent 0 bytes 0 pkts (dropped 0, overlimits 0) qdisc pfifo 21: limit 5p Sent 2891500 bytes 5783 pkts (dropped 820, overlimits 0) qdisc pfifo 20: limit 5p Sent 1760000 bytes 3520 pkts (dropped 3320, overlimits 0) qdisc htb 1: r2q 10 default 1 direct_packets_stat 0 Sent 4651500 bytes 9303 pkts (dropped 4140, overlimits 34251)First three disciplines are HTB's children. Let's ignore them as PFIFO stats are self explanatory.
overlimits tells you how many times the discipline delayed a packet. direct_packets_stat tells you how many packets was sent thru direct queue. Other stats are sefl explanatory. Let's look at class' stats:
tc -s -d class show dev eth0class htb 1:1 root prio 0 rate 800Kbit ceil 800Kbit burst 2Kb/8 mpu 0b cburst 2Kb/8 mpu 0b quantum 10240 level 3 Sent 5914000 bytes 11828 pkts (dropped 0, overlimits 0) rate 70196bps 141pps lended: 6872 borrowed: 0 giants: 0class htb 1:2 parent 1:1 prio 0 rate 320Kbit ceil 4000Kbit burst 2Kb/8 mpu 0b cburst 2Kb/8 mpu 0b quantum 4096 level 2 Sent 5914000 bytes 11828 pkts (dropped 0, overlimits 0) rate 70196bps 141pps lended: 1017 borrowed: 6872 giants: 0class htb 1:10 parent 1:2 leaf 20: prio 1 rate 224Kbit ceil 800Kbit burst 2Kb/8 mpu 0b cburst 2Kb/8 mpu 0b quantum 2867 level 0 Sent 2269000 bytes 4538 pkts (dropped 4400, overlimits 36358) rate 14635bps 29pps lended: 2939 borrowed: 1599 giants: 0I deleted 1:11 and 1:12 class to make output shorter. As you see there are parameters we set. Also there are level and DRR quantum informations.
overlimits shows how many times class was asked to send packet but he can't due to rate/ceil constraints (currently counted for leaves only).
rate, pps tells you actual (10 sec averaged) rate going thru class. It is the same rate as used by gating.
lended is # of packets donated by this class (from its rate) and borrowed are packets for whose we borrowed from parent. Lends are always computed class-local while borrows are transitive (when 1:10 borrows from 1:2 which in turn borrows from 1:1 both 1:10 and 1:2 borrow counters are incremented).
giants is number of packets larger than mtu set in tc command. HTB will work with these but rates will not be accurate at all. Add mtu to your tc (defaults to 1600 bytes).
8. Making, debugging and sending error reports
If you have kernel 2.4.20 or newer you don't need to patch it - all is in vanilla tarball. The only thing you need is tc tool. Download HTB 3.6 tarball and use tc from it.You have to patch to make it work with older kernels. Download kernel source and use patch -p1 -i htb3_2.X.X.diff to apply the patch. Then use make menuconfig;make bzImage as before. Don't forget to enable QoS and HTB.
Also you will have to use patched tc tool. The patch is also in downloads or you can download precompiled binary.
If you think that you found an error I will appreciate error report. For oopses I need ksymoops output. For weird qdisc behaviour add parameter debug 3333333 to your tc qdisc add .... htb. It will log many megabytes to syslog facility kern level debug. You will probably want to add line like:
kern.debug -/var/log/debug
to your /etc/syslog.conf. Then bzip and send me the log via email (up to 10MB after bzipping) along with description of problem and its time.
- linux下tc、htb、iptables基础知识及openwrt 下qos使用介绍
- linux下tc、htb、iptables基础知识及openwrt 下qos使用介绍
- linux下TC+HTB流量控制
- TC+Iptables+htb
- Linux下QoS模块之tc(traffic control)操作简介
- Linux下QoS模块之tc(traffic control)操作简介
- linux下防火墙iptables原理及使用
- linux下防火墙iptables原理及使用
- linux下防火墙iptables原理及使用
- TC(HTB)+iptables作流量控制
- TC(HTB)+iptables作流量控制
- 【转】TC(HTB)+iptables作流量控制
- TC+Iptables+htb(样例)
- LINUX TC:HTB相关源码
- LINUX TC:HTB相关源码
- LINUX TC:HTB相关源码
- Linux下使用iptables
- LINUX环境下Iprouter2 + iptables + tc 双线策略路由(转)
- 从Java类库看设计模式(5)
- 1225
- 为什么难以设计出令人满意的室内导航应用
- Office Web apps可以利用Excel Web JavaScript编程
- 对ConcurrentHashMap的深入理解和学习
- linux下tc、htb、iptables基础知识及openwrt 下qos使用介绍
- 在方法签名中使用控制反转(IoC)
- Firefox在劫难逃?现在还言之过早
- Andorid:ExpandableListActivity控件
- android adapter
- python单元测试unittest
- 新任Sencha开发者关系负责人谈未来工作
- 什么是Node.js
- 基于QT的音乐播放器


