网页信息抓取
来源:互联网 发布:淘宝差评解释语 编辑:程序博客网 时间:2024/04/29 11:07
准备工具:Dreamweaver,RegexBuddy
抓取分3步进行:
1)下载网页数据;
2)处理网页得到想要的数据;
3)保存数据
一、下载网页源代码
这个步骤有很多种方法可以实现,但是目的只有一个,那就是:给定网页Url,获得网页源代码.
1.使用WebClient下载:
//...//这里是WebClient需要使用的命名空间using System.Net;//...WebClient wbDown = new WebClient();string strResult = wbDown.DownloadString("http://www.baidu.com/");//OK,strResult就是下载到的网页源代码//...优点:方便,快捷,直接调用System.Net.WebClient就可以进行下载,大部分网页都可以下载下来
缺点:如果遇到需要用户名名和密码的网站,那就很麻烦了.
2.使用HttpWebRequest和HttpWebResponse
//...using System.Net;using System.IO;//引用的命名空间string strUrl = "http://www.baidu.com/";HttpWebRequest Request = (HttpWebRequest)WebRequest.Create(strUrl);HttpWebResponse Response = (HttpWebResponse)Request.GetResponse();StreamReader sr = new StreamReader(Response.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));string strResult = sr.ReadToEnd();//...优点:灵活性比较大,可以下载多种数据,设置以后可以下载带用户名密码的网页,可以传递cookie等;
缺点:代码比较多,不太优雅,建议封装后使用.
3.使用WebBrowser
WebBrower相当于一个小型的或者 mini IE,你可以在窗体中显示这个控件,然后查看具体的网页,而前面几种却不可以.当然,如果你愿意,也可以把它隐藏起来.
i)隐藏WebBrowser
//...string Url = @"http://www.baidu.com/";WebBrowser wb = new WebBrowser(){Url = new Uri(Url)};while (!wb.DocumentText.Contains("</html>")){if(DialogResult.OK == MessageBox.Show("数据下载中,请稍等..."))continue;}string strResult = wb.DocumentText;//...ii)显示WebBrowser
这个就不多说了,拖控件,改Url,你懂得.网页源代码 = 控件名.DocumentText.
优点:WebBrowser的优点有很多,比如可以查看网页的内容,特殊网页也能抓取...
缺点:拖着这么大一个控件,着实有点累赘...
//待添加其他方法
二、定位网页数据
这个过程我称之为定位数据,就是在整个网页中定位你想要的那个元素,比如一个<table>或者一段<div>等.
此过程目前有两种方法供大家选择:
1.正则表达式匹配;
2.使用HtmlAgilityPack;(不是很熟悉)
本文只提供正则表达式的方法供大家借鉴,还请读者见谅.
正则表达式定位
如果你是长期做数据采集工作,建议深入学习一下,这里是DeerChao的正则表达式入门,非常推荐.如果你只是想做一个课程设计,听听我的简介也无妨.
"定位"过程,主要使用了Regex.Match()方法,返回的结果是正则匹配的文本.也就是目标网页数据.
我大致解释一下,比如你有这样一段文本:
"I am 20 years old."
想得到年龄这个数据,也就是"20",如何使用正则捕获呢?
//...using System.Text.RegularExpressions;//导入正则表达式命名空间//...string strTest = @"I am 20 years old.";string strResult = "";strResult = Regex.Match(strTest, @"\d+").Value;Console.WriteLine(strResult);Console.ReadKey();
OK,捕获成功!但也许你会问,这个程序和定位有什么关系呢?恩,让我来解释下:
你可以多次使用: strResult = Regex.Match(strResult , @"正则").Value;一步一步缩小网页中数据的范围,最后定位到你想到的那部分数据.
类似"I am 20 years old."你可以分三步定位到"20"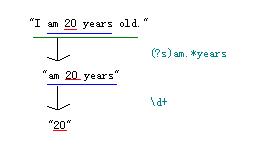
那么网页你可以用相同的方式定位到嵌套中的内容(当然,没有嵌套的部分, 你也可以尝试一次性捕获),
strResult = Regex.Match(strResult , "(?is)登录.*?更多").Value; strResult = Regex.Match(strResult , "(?is)<input.type=""submit"".*?>").Value;通过这两句代码,你就可以定位到百度的"百度一下"按钮,当然你也可以把前面一句删除,因为百度首页只有一个提交按钮.但是如果是其他网站,有多个提交按钮那就要重新考虑正则的写法.
FAQ
定位数据的原理基本介绍完了,相信读者会有很多疑问(文笔不好,见谅),我自己先写一些吧:
Q:匹配的结果有多个值怎么办?
A:匹配网页数据的时候,多会遇到匹配结果是多个的情况,比如多个table,多个div标签等,这个时候,我们可以使用MatchCollection来接受返回的结果集,例如:
MatchCollection mcResult = Regex.Matches(strHtml, @"(?is)<table.*?table>");
Q:你在正则里写的(?is)是什么意思?
A:这个是正则表达式的匹配选项,.Net里面也有对应的选项
(?i) 代表不区分大小写 等价于.net中RegexOptions.IgnoreCase选项;
(?s) 表示让"."号匹配换行,即"."代表了[\s\S] 等价于.net中RegexOptions.Singleline选项;
//当然还有其他问题,这里就先不列出来了,希望大家可以发表评论,我会尽力解答.
三、保存数据
保存数据有多种形式,比如XML格式,<table>标签内容,直接写入数据库,保存为txt....大家可以依照自己的需求来选择合适的方式进行保存.
但是,为了统一,我建议使用XML来保存内容,一来,一个网页中的数据基本上都可以转换为XML格式;二来,XML录入数据库,转换为其他形式都很方便;三来,XML操作数据方便,如果需要修改数据,有很多API类库之类的可以调用.总之是好处多多啊,呵呵.
@"Author:wushuai1346Description:不断完善中.版权所有,转载请注明出处,谢谢.Copyright (C) 2011 wushuai1346,All Rights ReservedUrl:http://blog.csdn.net/wushuai1346/article/details/7108424Createtime : 2011-12-28Updatetime : 2011-12-29"
- 网页信息抓取
- [Python]网页信息抓取
- Perl抓取网页信息
- HtmlAgilityPack 抓取网页信息
- php 抓取网页信息
- 抓取网页信息PHP
- c#信息抓取一:抓取网页源代码
- 使用Python抓取网页信息
- 使用Python抓取网页信息
- 网页中的信息抓取(stream)
- python 抓取网页网址信息
- python多线程抓取网页信息
- Python 抓取网页特定信息
- 网页信息抓取(Java htmlparser)
- Jsoup抓取网页信息学习
- python--parser抓取网页信息
- 学习curl抓取网页信息
- python3爬虫--抓取网页信息
- 循环前缀在OFDM中应用(一)
- Android应用开发之获取网络数据
- DataGrid常用的使用技巧
- Cmake
- Grid Service 学习1
- 网页信息抓取
- "sql statement not set"和"preparestatement:Dynamic sql error"
- CSS基础教程(上)
- jquery ajax 同步异步的执行 return值不能取得的解决方案
- CSS基础教程(下)
- 展现当前日期后三十一天的日历
- JS中手动触发事件的方法
- Android应用开发之获取web服务器xml数据
- 对android中MIME类型的理解


