1->n MPI_Scatter MPI_Bcast
来源:互联网 发布:云帆搜索软件 编辑:程序博客网 时间:2024/04/28 03:38
1. 函数 MPI_Scatter
MPI_Scatter (&sendbuf,sendcnt,sendtype,&recvbuf,recvcnt,recvtype,root,comm)
Distributes distinct messages from a single source task to each task in the group.
2. 举例
#include<stdio.h>#include"mpi.h"#define SIZE 4int main(int argc, char *argv[]){ int totalNumTasks, rankID; float sendBuf[SIZE][SIZE] = { {1.0, 2.0, 3.0, 4.0}, {5.0, 6.0, 7.0, 8.0}, {9.0, 10.0, 11.0, 12.0}, {13.0, 14.0, 15.0, 16.0} }; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rankID); MPI_Comm_size(MPI_COMM_WORLD, &totalNumTasks); if(totalNumTasks == SIZE){ int source = 0; int sendCount = SIZE; int recvCount = SIZE; float recvBuf[SIZE]; //scatter data from source process to all processes in MPI_COMM_WORLD MPI_Scatter(sendBuf, sendCount, MPI_FLOAT, recvBuf, recvCount, MPI_FLOAT, source, MPI_COMM_WORLD); printf("my rankID = %d, receive Results: %f %f %f %f, total = %f\n", rankID, recvBuf[0], recvBuf[1], recvBuf[2], recvBuf[3], recvBuf[0] + recvBuf[1] + recvBuf[2] + recvBuf[3]); }else if(totalNumTasks == 8){ int source = 0; int sendCount = 2; int recvCount = 2; float recvBuf[2]; MPI_Scatter(sendBuf, sendCount, MPI_FLOAT, recvBuf, recvCount, MPI_FLOAT, source, MPI_COMM_WORLD); printf("my rankID = %d, receive result: %f %f, total = %f\n", rankID, recvBuf[0], recvBuf[1], recvBuf[0] + recvBuf[1]); }else{ printf("Please specify -n %d or -n %d\n", SIZE, 2*SIZE); } MPI_Finalize(); return 0;}3. 编译执行
[amao@amao991 mpi-study]$ mpicc collectiveScatter.c [amao@amao991 mpi-study]$ mpiexec -n 4 -f machinefile ./a.out my rankID = 0, receive Results: 1.000000 2.000000 3.000000 4.000000, total = 10.000000my rankID = 1, receive Results: 5.000000 6.000000 7.000000 8.000000, total = 26.000000my rankID = 3, receive Results: 13.000000 14.000000 15.000000 16.000000, total = 58.000000my rankID = 2, receive Results: 9.000000 10.000000 11.000000 12.000000, total = 42.000000[amao@amao991 mpi-study]$ mpiexec -n 8 -f machinefile ./a.out my rankID = 6, receive result: 13.000000 14.000000, total = 27.000000my rankID = 7, receive result: 15.000000 16.000000, total = 31.000000my rankID = 4, receive result: 9.000000 10.000000, total = 19.000000my rankID = 0, receive result: 1.000000 2.000000, total = 3.000000my rankID = 1, receive result: 3.000000 4.000000, total = 7.000000my rankID = 5, receive result: 11.000000 12.000000, total = 23.000000my rankID = 3, receive result: 7.000000 8.000000, total = 15.000000my rankID = 2, receive result: 5.000000 6.000000, total = 11.000000[amao@amao991 mpi-study]$ mpiexec -n 2 -f machinefile ./a.out Please specify -n 4 or -n 8Please specify -n 4 or -n 8
4. 总结
(1) 由于集合通信是阻塞的,因此,每个进程自动等待,完成接收后,执行printf语句
(2) 为了能够平均划分数据,本例执行时最好-n 4 或者-n 8
(3) 在每个进程接受到数据后,可以对其求和。若要把每个进程的求和结果汇总到某个进程,要用n->1即就是MPI_Gather或者MPI_Reduce函数。
-----------------------------------------------------
1. 函数
MPI_Bcast (&buffer,count,datatype,root,comm)
Broadcasts (sends) a message from the process with rank "root" to all other processes in the group.
2. 图示
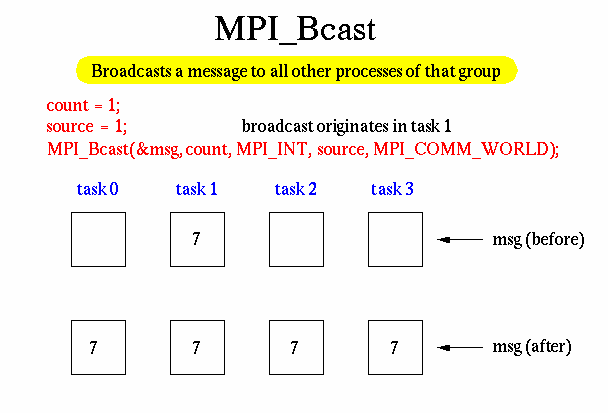
3. 举例
#include<stdio.h>#include"mpi.h"int main(int argc, char *argv[]){ int rankID, totalNumTasks; MPI_Init(&argc, &argv); MPI_Barrier(MPI_COMM_WORLD); double elapsed_time = -MPI_Wtime(); MPI_Comm_rank(MPI_COMM_WORLD, &rankID); MPI_Comm_size(MPI_COMM_WORLD, &totalNumTasks); int sendRecvBuf[3] = {0, 0, 0}; if(!rankID){ sendRecvBuf[0] = 3; sendRecvBuf[1] = 6; sendRecvBuf[2] = 9; } int count = 3; int root = 0; MPI_Bcast(sendRecvBuf, count, MPI_INT, root, MPI_COMM_WORLD); //MPI_Bcast can be seen from all processes printf("my rankID = %d, sendRecvBuf = {%d, %d, %d}\n", rankID, sendRecvBuf[0], sendRecvBuf[1], sendRecvBuf[2]); elapsed_time += MPI_Wtime(); if(!rankID){ printf("total elapsed time = %10.6f\n", elapsed_time); } MPI_Finalize(); return 0;}4. 编译执行[amao@amao991 mpi-study]$ mpicc broadcast.c
[amao@amao991 mpi-study]$ mpiexec -f machinefile -n 5 ./a.outmy rankID = 0, sendRecvBuf = {3, 6, 9}total elapsed time = 0.000045my rankID = 2, sendRecvBuf = {3, 6, 9}my rankID = 4, sendRecvBuf = {3, 6, 9}my rankID = 1, sendRecvBuf = {3, 6, 9}my rankID = 3, sendRecvBuf = {3, 6, 9}
5. 总结
(1) 在记录起始时间之前,用MPI_Barrier(MPI_COMM_WORLD);对所有进程做同步
(2) MPI_Bcast(sendRecvBuf, count, MPI_INT, root, MPI_COMM_WORLD);
要对所有进程可见,若只对process 0可见,是错误的。其他进程也需要知道它而接收啊!
- 1->n MPI_Scatter MPI_Bcast
- MPI学习-MPI_Bcast and MPI_Scatter
- MPI_Bcast
- 采用MPI_Send 和MPI_Recv 编写代码来实现包括MPI_Bcast、MPI_Alltoall、MPI_Gather、MPI_Scatter 等MPI 群集通信函数的功能
- MPI散播(MPI_Scatter)
- MPI_Bcast函数的用法
- n&n-1 n&-n
- n&-n n&n-1
- MPI_Bcast广播操作的通信开销测试
- MPI聚合通信之MPI_Bcast函数
- n&(n-1) 与 n&-n
- n & (n-1) 和 n & (-n)
- 求值:1!/n+3!/n*n*n+5!/n*n*n*n*n+....k!/n*n*n*n....n*n(有k个n);
- n & (n-1)
- n&(n-1)
- n&(n-1)作用
- n&(n-1)妙用
- n&(n-1)
- 在WIN7下安装ORACLE需要注意的问题
- 使用pssh批量管理服务器
- 使用remote_listener实现数据库与监听器分离 | HelloDML
- Redis详细介绍
- javascript正则表达式
- 1->n MPI_Scatter MPI_Bcast
- Mysql Master/Slave的配置
- 源码安装mysql
- ArcGIS API for Silverlight 学习笔记
- [jQuery一点一滴]jQuery简介
- VS2003编译OGRE error C2065: '__in' : undeclared identifier 解决
- group by 、 having 、 order by
- stagefright框架(五)-Video Rendering
- 在Apache中整合JSP和PHP


