NameNode对域名/IP的解析——DNSToSwitchMapping
来源:互联网 发布:sql union 多列 编辑:程序博客网 时间:2024/05/01 08:26
前面介绍Networktopology结构的时候就说过,NameNode把注册的DataNode节点按照他们的ip地址存储到一个树状网络拓扑图中(对应Networktopology的一个实例),然后NameNode调用ReplicationTargetChooser来为每一个数据块副本选择合适的存储节点。那么,NameNode是如何把一个数据节点按照它的ip解析到对应的树状网络拓扑图中的一个叶子节点呢?
实际上,这个过程很简单,NameNode把这个NameNode节点所在主机的ip地址按照用户设计的规则转换成一个对应的路径格式(如:/*/*/*/*),这个路径就对应了树状网络拓扑图中的一个非叶子节点,NameNode就把这个数据节点存放到这个非叶子节点下面,作为它的叶子节点。现在关键的问题就是NameNode如何把一个ip地址解析成一个路径的形式。刚才说了,NameNode是按照用户设计的转换规则来的,它自己并不知道如何转换,也就是说这个转换是交由用户自己来实现的。
HDFS将ip地址转换成路径的操作交给了用户自己来实现,即用户通过自己实现接口DNSToSwitchMapping,然后在配置文件中指明实现的这个类,NameNode就能够自动的调用用户的解析实现了。哦,对了,这个对应的配置项是:topology.node.switch.mapping.impl。
现在我想说一下,HDFS为什么要把ip地址的解析交给用户自己来实现?这是因为HDFS不得不把这个过程交给用户来实现,只有集群管理员即用户才知道哪些ip地址对应的机器被放在同一个机架下面,哪些机架在同一个路由器下面,说白了就是只有集群管理员才知道机器之间的网络距离。好了,现在就来具体看看与DNSToSwitchMapping相关的实现。
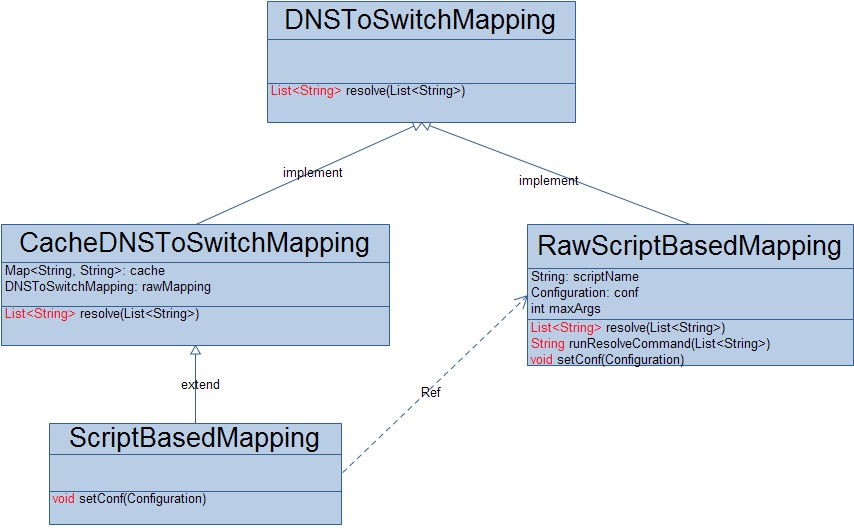
HDFS考虑到性能问题,一方面把DNSToSwitchMapping接口定义成一个批量解析任务,另一方面自己还定义了一个缓存类CacheDNSToSwitchMapping来保存解析的结果。同时,HDFS自己也定义了一个DNSToSwitchMapping的实现RawScriptBasedMapping,这个实现类被设计成了一个插件集成类,它通过执行shell脚本语言调用第三方的实现来获取一批ip地址的解析结果,这实际上还是将真正的解析过程交给了用户。在默认的情况下,NameNode使用ScriptBasedMapping来解析ip地址。现在来好好的分析一下这个RawScriptBasedMapping实现类。
RawScriptBasedMapping类主要包含三个参数:

scriptName:调用第三方ip解析实现的脚本命令;
maxArgs:第三方ip解析实现一次调用最多能解析多少个ip;
conf:通过配置文件获取scriptName和maxArgs;
RawScriptBasedMapping根据NameNode传过来的ip解析任务分批调用第三方ip解析器来执行这些ip的解析,每一批不能超过maxArgs个ip地址。调用的过程如下:
private String runResolveCommand(List<String> args) { int loopCount = 0; if (args.size() == 0) { return null; } StringBuffer allOutput = new StringBuffer(); int numProcessed = 0; if (maxArgs < MIN_ALLOWABLE_ARGS) { LOG.warn("Invalid value " + Integer.toString(maxArgs) + " for " + SCRIPT_ARG_COUNT_KEY + "; must be >= " + Integer.toString(MIN_ALLOWABLE_ARGS)); return null; } while (numProcessed != args.size()) { int start = maxArgs * loopCount; List <String> cmdList = new ArrayList<String>(); cmdList.add(scriptName); for (numProcessed = start; numProcessed < (start + maxArgs) && numProcessed < args.size(); numProcessed++) { cmdList.add(args.get(numProcessed)); } File dir = null; String userDir; if ((userDir = System.getProperty("user.dir")) != null) { dir = new File(userDir); } ShellCommandExecutor s = new ShellCommandExecutor(cmdList.toArray(new String[0]), dir); try { s.execute(); allOutput.append(s.getOutput() + " "); } catch (Exception e) { LOG.warn(StringUtils.stringifyException(e)); return null; } loopCount++; } return allOutput.toString(); } 现在我将举一个完整的例子,即自己实现一个第三方的ip解析插件,来详细的阐述整个实现与配置过程:1).自定义一个ip解析器
利用C语言写一个简单的程序,对每一个传入的ip地址,都输出对应的一个路径,然后编译连接生成一个可执行文件:ipresolve
#include<stdio.h>int main(int argc, char ** argv){ if(argc>1){ int i; for(i=1; i<argc; ++i) printf("/rack/rakc/rakc%d\n",i); } return 0;}2).在HDFS的配置文件core-site.xml中配置这个第三方插件
<property> <name>topology.script.file.name</name> <value>/home/**/ipresolve</value> <description>可执行文件ipresolve的绝对路径</description></property><property> <name>topology.script.number.args</name> <value>10</value> <description></description></property>
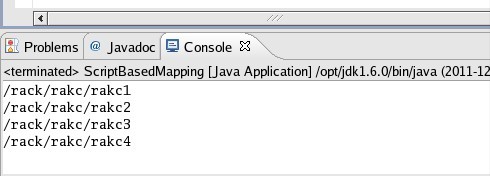
3).测试
public static void main(String[] args){ Configuration conf = new Configuration(); ScriptBasedMapping sbp = new ScriptBasedMapping(); sbp.setConf(conf); List<String> ips = new ArrayList<String>(); ips.add("127.0.0.1"); ips.add("127.0.0.2"); ips.add("127.0.0.3"); ips.add("127.0.0.4"); List<String> result = sbp.resolve(ips); for(int i=0; i<result.size(); ++i){ System.out.println(result.get(i)); } }4).测试输出
当然,对用户来说有两种方式来实现用户自定义的ip解析器,一中是直接实现DNSToSwitchMapping接口,并将这个实现类配置到配置文件的项;另一种就是上面的的插件方式。就性能而言,第一种方式为佳,就可扩展行而言,第二种方式为佳,不过,这最后还是取决于用户自己的应用场景。
- NameNode对域名/IP的解析——DNSToSwitchMapping
- ubuntu11.04 能够ping通外ip,但是解析不了域名—ubuntu的DNS配置
- DNS对域名的解析过程
- 单一IP地址对多域名-Ubuntu下的一IP多域名解决方案
- 域名和ip是多对多的关系
- 如何解析一个域名对应的IP是什么
- Python实现同域名下多个IP地址的解析
- Apache对域名的泛解析方法集锦
- Apache对域名的泛解析方法集锦
- 获取域名的ip
- 获取域名的IP
- 对TCP/IP分层的解析
- YTKNetWork源码解析——针对SSL自产证书认证如何随心所欲的游走在IP和域名之间并开启想要的验证
- 强悍的命令行 —— 命令行域名的解析
- Hadoop 获取Active Namenode的IP地址
- C++——通过域名获取ip
- 解析IP地址为主机域名
- 解析域名与IP地址(Linux编程)
- C# Dictionary
- sencha-touch1.1中的panel如何载入模板
- C++中的overload,overwritting,overriding
- Eclipse快捷键大全
- Java基础:数组Array转成List的几种方法
- NameNode对域名/IP的解析——DNSToSwitchMapping
- 深入CACHE
- C++ 工厂方法2
- MotionEvent的getX(),getY()与getRawX(),getRawY()区别
- C#发送邮件
- 一些好的学习网站
- EntityFrameworkOBE
- 将List转化成String数组
- FreeMarker的例子


