HDFS中的数据存储路径——StorageDirectory
来源:互联网 发布:深圳网络服务公司 编辑:程序博客网 时间:2024/05/14 13:39
在HDFS中,无论是NameNode节点还是DataNode节点都需要使用它们所在的本地文件系统来存储与自己相关的数据,如:NameNode节点存储系统命名空间的元数据,DataNode节点存储文件的数据块数据。对于NameNode节点或是DataNode节点,我们多可以为它们配置多个本地文件系统的存储路径,不同的是,NameNode节点中的所有存储路径存储的数据基本上是一样的,而DataNode节点中的存储路径会分别存储不同的文件数据块。HDFS对节点存储路径的实现被抽象成了一个StorageDirectory类。
StorageDirectory类主要包含三个属性:

root:节点存储目录所在本地文件系统的目录;
lock:排它锁,同步控制节点对该存储目录的操作;
dirType:存储路径所属的节点类型(NameNode/DataNode);
无论是NameNode节点还是DataNode节点,StorageDirectory都会把它们出过来的数据保存到自己的子目录current/下,同时为了保证数据的一致性,在子目录current/下都会有一个版本文件VERSION。但是,NameNode节点和DataNode节点的存储目录下的版本文件VERSION的内容有一点不同,如
NameNode存储目录的版本文件:

DataNode存储目录的版本文件:

在HDFS集群中,每一个DataNode节点的每一个存储路径的namespaceID必须与NameNode节点的namespaceID保持一致,否则该DataNode节点将中止启动,NameNode节点的namespaceID在它format是生成,也就是说NameNode节点没格式化一次,就会产生一个新的namespaceID。另外,storageID是DataNode节点向NameNode节点第一次注册时,NameNode为它分配的一个分布式存储器标识,一个DataNode节点中所有存储路径的storageID是一样的。当然,NameNode和DataNode的存储路径中存储的数据文件也是不一样的。
NameNode存储目录current/中的文件包括:

DataNode存储目录current/中的文件包括:

StorageDirectory除了提供保存节点数据的功能外,还提供了对存储数据的粗粒度事务操作如:备份/恢复/提交等。那么,StorageDirectory是如何实现这些事务性操作的呢?
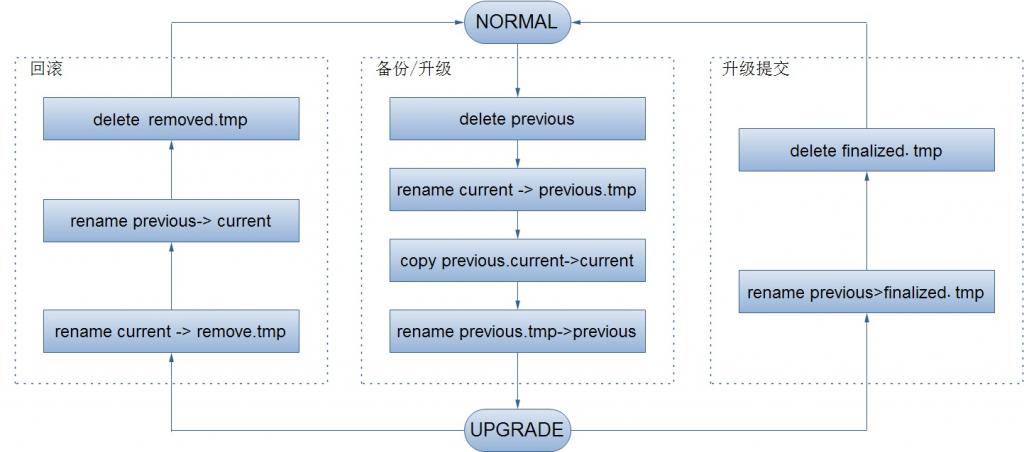
通过上面操作流程图,对于存储路径中的数据的备份(升级)/恢复/提交操作可以说是一目了然,但是还有一个问题就是当节点在执行上面操作的某一个过程中突然宕机了,那么这个节点在下一次启动如何进行恢复上一次的中断操作呢?其实,StorageDirectory在在恢复它存储的数据之前会先分析自己所出的状态(analyzeStorage()方法),然后根据自己当前作出的状态来执行相应的恢复操作(doRecover()方法)。这个分析过程及对应的恢复操作如下:

- HDFS中的数据存储路径——StorageDirectory
- 关于HDFS数据存储路径
- Hadoop学习——HDFS数据存储和删除
- 【Hadoop】数据存储----HDFS
- 辅助线——hdfs 存储
- HDFS数据存储和删除
- UISenior —— 数据存储之沙盒路径
- NSUserDefaults 数据存储路径
- iOS数据存储路径
- //数据存储的路径-----
- 数据存储路径
- 客户端读取HDFS中的数据
- 数据存储—读取Assets中的数据test
- HDFS Datanode数据存储格式分析
- HDFS数据存储位置与复制详解
- HDFS Datanode数据存储格式分析
- HDFS Datanode数据存储格式分析
- 用HDFS存储海量的视频数据
- CSE技术大盘点:一款堪比Python与Ruby的脚本语言
- Android中发送Http请求实例(包括文件上传、servlet接收)
- 正则表达式
- php开启错误
- 简单爆破java程序
- HDFS中的数据存储路径——StorageDirectory
- windwos下Websphere6.1部署的相关问题及解决方法
- Ie6的Bug
- WAS61升级补丁步骤
- 做一个高效率的开发者必须做的11件事
- 16.1 使用事件有反应的编程
- windows下查看端口对应的进程和进程号
- php重构优化一例——模板方法模式应用
- String的CompareTo方法


