postgresql中plantree内存结构
来源:互联网 发布:淘宝店铺私活价格 编辑:程序博客网 时间:2024/05/16 19:55
postgresql中plantree内存结构
|||
上次写完了 postgresql中querytree内存结构,接下来就是又让你激动,又让你觉得神秘的plantree了。
先看看src/backend/optimizer的readme:
Optimizer
=========
These directories take the Query structure returned by the parser, and generate a plan used by the executor.
在看看readme下面的:
Optimizer Data Structures
-------------------------
PlannerGlobal - global information for a single planner invocation
PlannerInfo - information for planning a particular Query (we make a separate PlannerInfo node for each sub-Query)
RelOptInfo - a relation or joined relations
RestrictInfo - WHERE clauses, like "x = 3" or "y = z"
(note the same structure is used for restriction and
join clauses)
Path - every way to generate a RelOptInfo(sequential,index,joins)
SeqScan - a plain Path node with pathtype = T_SeqScan
IndexPath - index scans
BitmapHeapPath - top of a bitmapped index scan
TidPath - scan by CTID
AppendPath - append multiple subpaths together
ResultPath - a Result plan node (used for FROM-less SELECT)
MaterialPath - a Material plan node
UniquePath - remove duplicate rows
NestPath - nested-loop joins
MergePath - merge joins
HashPath - hash joins
EquivalenceClass - a data structure representing a set of values known equal
PathKey - a data structure representing the sort ordering of a path
上面把optimizer用到的数据结构都说明了用途。
我们再看看8.4 的document:
在43.5.1. Generating Possible Plans有:
The planner/optimizer starts by generating plans for scanning each individual relation (table) used in the query. The possible plans are determined by the available indexes on each relation. There is always the possibility of performing a sequential scan on a relation, so a sequential scan plan is always created.
看样子 sequential scan plan是必须的了,由于我们pois表没建索引,所以我们可以想象,我们的plan是没有index相关的path的。等有时间再写一篇涉及index和整个优化器有关的文章。
好,有了这些基本概念,我们开工。
再次写一下我们的前提条件:
假定我们数据库中已经有如下表,并填充了数据:
CREATE TABLE pois
(
uid integer not null,
catcode VARCHAR(32) not null,
);
现在我们用psql发送请求:select catcode from pois;
程序已经执行完了querytree_list = pg_analyze_and_rewrite(parsetree, query_string, NULL, 0);
接下来就是执行我们神秘的 stmt = (Node *) pg_plan_query(query, cursorOptions, boundParams);了。
首先看调用堆栈:
postgresql Thread [C/C++ Attach to Application]
gdb Debugger (5/1/10 10:16 AM) (Suspended)
Thread [1] (Suspended)
17 set_plain_rel_pathlist() /home/postgres/develop/.../src/backend/optimizer/path/allpaths.c:264
16 set_rel_pathlist() /home/postgres/develop/.../src/backend/optimizer/path/allpaths.c:201
15 set_base_rel_pathlists() /home/postgres/develop/.../src/backend/optimizer/path/allpaths.c:157
14 make_one_rel() /home/postgres/develop/.../src/backend/optimizer/path/allpaths.c:93
13 query_planner() /home/postgres/develop/.../src/backend/optimizer/plan/planmain.c:252
12 grouping_planner() /home/postgres/develop/.../src/backend/optimizer/plan/planner.c:1006
11 subquery_planner() /home/postgres/develop/.../src/backend/optimizer/plan/planner.c:481
10 standard_planner() /home/postgres/develop/.../src/backend/optimizer/plan/planner.c:190
9 pg_plan_query() /home/postgres/develop/.../src/backend/tcop/postgres.c:697
8 pg_plan_queries() /home/postgres/develop/.../src/backend/tcop/postgres.c:756
7 exec_simple_query() /home/postgres/develop/.../src/backend/tcop/postgres.c:921
6 PostgresMain() /home/postgres/develop/.../src/backend/tcop/postgres.c:3617
5 BackendRun() /home/postgres/develop/.../src/backend/postmaster/postmaster.c:3449
4 BackendStartup() /home/postgres/develop/.../src/backend/postmaster/postmaster.c:3063
3 ServerLoop() /home/postgres/develop/.../src/backend/postmaster/postmaster.c:1387
2 PostmasterMain() /home/postgres/develop/.../src/backend/postmaster/postmaster.c:1040
1 main() /home/postgres/develop/.../src/backend/main/main.c:188
我之所以把堆栈写到 set_plain_rel_pathlist()来,是因为这是建立我们最终顺序扫描path的调用函数。具体调用代码为:
static void set_plain_rel_pathlist(PlannerInfo *root, RelOptInfo *rel, RangeTblEntry *rte){
if (rel->reloptkind == RELOPT_BASEREL && relation_excluded_by_constraints(root, rel, rte)) {
set_dummy_rel_pathlist(rel);
return;
}
check_partial_indexes(root, rel);
set_baserel_size_estimates(root, rel);
if (create_or_index_quals(root, rel)) {
check_partial_indexes(root, rel);
set_baserel_size_estimates(root, rel);
}
add_path(rel, create_seqscan_path(root, rel));
create_index_paths(root, rel);
create_tidscan_paths(root, rel);
set_cheapest(rel);
}
add_path(rel, create_seqscan_path(root, rel));即为实际增加我们的path的调用,本身该调用非常简单,就是估算从硬盘读page和时间+处理所有tuple的时间,然后填充path。
我把程序执行完下面这条语句之前的数据结构画张图,如下:
line1064: result_plan = optimize_minmax_aggregates(root,
tlist,
best_path);
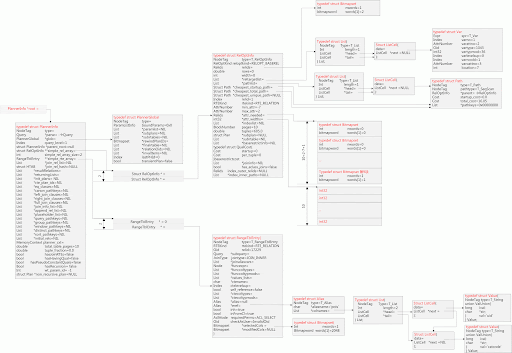
下图是最终的内存结构图,为完整起见,我把PlannerInfo及相应的数据结构都保留下来:
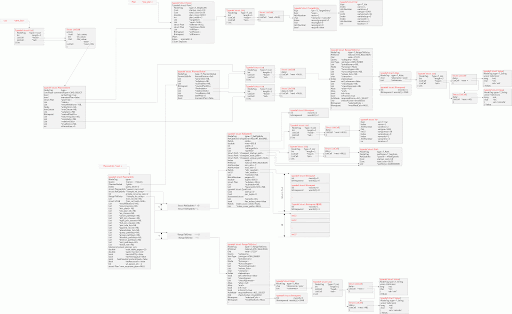
图太大,picasa不让传超过1M的图片,只好上传到filefront.com/,看大图的可以从这里下载。
下图是只包含plan tree的图:
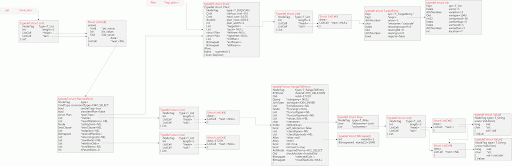
至此,全部结束。
http://blog.sciencenet.cn/home.php?mod=space&uid=419883&do=blog&id=317833
先看看src/backend/optimizer的readme:
Optimizer
=========
These directories take the Query structure returned by the parser, and generate a plan used by the executor.
- The /plan directory generates the actual output plan,
- the /path code generates all possible ways to join the tables,
- and /prep handles various preprocessing steps for special cases.
- /util is utility stuff.
- /geqo is the separate "genetic optimization" planner--- it does a semi-random search through the join tree space, rather than exhaustively considering all possible join trees.
在看看readme下面的:
Optimizer Data Structures
-------------------------
PlannerGlobal - global information for a single planner invocation
PlannerInfo - information for planning a particular Query (we make a separate PlannerInfo node for each sub-Query)
RelOptInfo - a relation or joined relations
RestrictInfo - WHERE clauses, like "x = 3" or "y = z"
(note the same structure is used for restriction and
join clauses)
Path - every way to generate a RelOptInfo(sequential,index,joins)
SeqScan - a plain Path node with pathtype = T_SeqScan
IndexPath - index scans
BitmapHeapPath - top of a bitmapped index scan
TidPath - scan by CTID
AppendPath - append multiple subpaths together
ResultPath - a Result plan node (used for FROM-less SELECT)
MaterialPath - a Material plan node
UniquePath - remove duplicate rows
NestPath - nested-loop joins
MergePath - merge joins
HashPath - hash joins
EquivalenceClass - a data structure representing a set of values known equal
PathKey - a data structure representing the sort ordering of a path
上面把optimizer用到的数据结构都说明了用途。
我们再看看8.4 的document:
在43.5.1. Generating Possible Plans有:
The planner/optimizer starts by generating plans for scanning each individual relation (table) used in the query. The possible plans are determined by the available indexes on each relation. There is always the possibility of performing a sequential scan on a relation, so a sequential scan plan is always created.
看样子 sequential scan plan是必须的了,由于我们pois表没建索引,所以我们可以想象,我们的plan是没有index相关的path的。等有时间再写一篇涉及index和整个优化器有关的文章。
好,有了这些基本概念,我们开工。
再次写一下我们的前提条件:
假定我们数据库中已经有如下表,并填充了数据:
CREATE TABLE pois
(
uid integer not null,
catcode VARCHAR(32) not null,
);
现在我们用psql发送请求:select catcode from pois;
程序已经执行完了querytree_list = pg_analyze_and_rewrite(parsetree, query_string, NULL, 0);
接下来就是执行我们神秘的 stmt = (Node *) pg_plan_query(query, cursorOptions, boundParams);了。
首先看调用堆栈:
postgresql Thread [C/C++ Attach to Application]
gdb Debugger (5/1/10 10:16 AM) (Suspended)
Thread [1] (Suspended)
17 set_plain_rel_pathlist() /home/postgres/develop/.../src/backend/optimizer/path/allpaths.c:264
16 set_rel_pathlist() /home/postgres/develop/.../src/backend/optimizer/path/allpaths.c:201
15 set_base_rel_pathlists() /home/postgres/develop/.../src/backend/optimizer/path/allpaths.c:157
14 make_one_rel() /home/postgres/develop/.../src/backend/optimizer/path/allpaths.c:93
13 query_planner() /home/postgres/develop/.../src/backend/optimizer/plan/planmain.c:252
12 grouping_planner() /home/postgres/develop/.../src/backend/optimizer/plan/planner.c:1006
11 subquery_planner() /home/postgres/develop/.../src/backend/optimizer/plan/planner.c:481
10 standard_planner() /home/postgres/develop/.../src/backend/optimizer/plan/planner.c:190
9 pg_plan_query() /home/postgres/develop/.../src/backend/tcop/postgres.c:697
8 pg_plan_queries() /home/postgres/develop/.../src/backend/tcop/postgres.c:756
7 exec_simple_query() /home/postgres/develop/.../src/backend/tcop/postgres.c:921
6 PostgresMain() /home/postgres/develop/.../src/backend/tcop/postgres.c:3617
5 BackendRun() /home/postgres/develop/.../src/backend/postmaster/postmaster.c:3449
4 BackendStartup() /home/postgres/develop/.../src/backend/postmaster/postmaster.c:3063
3 ServerLoop() /home/postgres/develop/.../src/backend/postmaster/postmaster.c:1387
2 PostmasterMain() /home/postgres/develop/.../src/backend/postmaster/postmaster.c:1040
1 main() /home/postgres/develop/.../src/backend/main/main.c:188
我之所以把堆栈写到 set_plain_rel_pathlist()来,是因为这是建立我们最终顺序扫描path的调用函数。具体调用代码为:
static void set_plain_rel_pathlist(PlannerInfo *root, RelOptInfo *rel, RangeTblEntry *rte){
if (rel->reloptkind == RELOPT_BASEREL && relation_excluded_by_constraints(root, rel, rte)) {
set_dummy_rel_pathlist(rel);
return;
}
check_partial_indexes(root, rel);
set_baserel_size_estimates(root, rel);
if (create_or_index_quals(root, rel)) {
check_partial_indexes(root, rel);
set_baserel_size_estimates(root, rel);
}
add_path(rel, create_seqscan_path(root, rel));
create_index_paths(root, rel);
create_tidscan_paths(root, rel);
set_cheapest(rel);
}
add_path(rel, create_seqscan_path(root, rel));即为实际增加我们的path的调用,本身该调用非常简单,就是估算从硬盘读page和时间+处理所有tuple的时间,然后填充path。
我把程序执行完下面这条语句之前的数据结构画张图,如下:
line1064: result_plan = optimize_minmax_aggregates(root,
tlist,
best_path);
下图是最终的内存结构图,为完整起见,我把PlannerInfo及相应的数据结构都保留下来:
图太大,picasa不让传超过1M的图片,只好上传到filefront.com/,看大图的可以从这里下载。
下图是只包含plan tree的图:
至此,全部结束。
http://blog.sciencenet.cn/home.php?mod=space&uid=419883&do=blog&id=317833
- postgresql中plantree内存结构
- postgresql中query tree内存结构
- Postgresql Executor 阶段内存结构
- PostgreSQL服务过程中的那些事二:Pg服务进程处理简单查询五:规划成plantree
- PostgreSQL启动过程中的那些事七:初始化共享内存和信号十七:shmem中初始化AutoVacuum相关结构
- PostgreSQL启动过程中的那些事七:初始化共享内存和信号十九:shmem中初始化BTree相关结构
- PostgreSQL学习第十一篇 进程及内存结构
- PostgreSQL启动过程中的那些事七:初始化共享内存和信号十八:shmem中初始化WalSender和WalRecv相关结构
- PostgreSQL启动过程中的那些事七:初始化共享内存和信号二十:shmem中初始化堆同步扫描、pg子进程相关结构
- 关于Java中内存结构
- 内存中结构体的内存对齐
- postgresql进程结构
- PostgreSQL源码结构
- PostgreSQL源码结构
- PostgreSQL源码结构
- PostgreSQL源码结构
- postgresql导出表结构
- Postgresql逻辑结构整理
- linux php mysql 中文乱码解决方案
- NeatUpload的安装使用,可传大文件,显示进度条
- 在Linux环境下编译安装配置PostGIS/PostgreSQL全过程
- rhel6+postgresql8.4+postgis1.4+eclipse CDT3.6 调试环境搭建
- 什么是Node.js?
- postgresql中plantree内存结构
- linux 启动mysql 命令
- JPA复合属性映射
- Ubuntu11搭建QT开发环境
- 约瑟夫问题的解法-良好接口的重要性
- PostgresMain()中重要的几个初始化
- 博客及博主简介
- Extjst系统集成与应用开发平台(一)
- windows2003 IIS6 发布 Silverlight + Ria Services


