Keil uVision2 压缩编译后的程序大小
来源:互联网 发布:仁化网络问政 编辑:程序博客网 时间:2024/05/14 07:55
通过简单的设置Keil uVision2 可以将目标程序的大小进行最大限度的压缩,通常情况下可以把 目标文件例如 bin文件压缩10K左右。
第1步 打开工程属性,鼠标右键点击Target1,选择 “Options for Target 'Target 1'”
第2步 选中C51选项卡

在Code Optimization组中,选择 Level,把级别选中9,第9级“Common Block Subroutines”
点击确定后,重新编译你的程序,你会发现程序的目标文件已经大大的减小。
下面给出几个实验数据供参考:
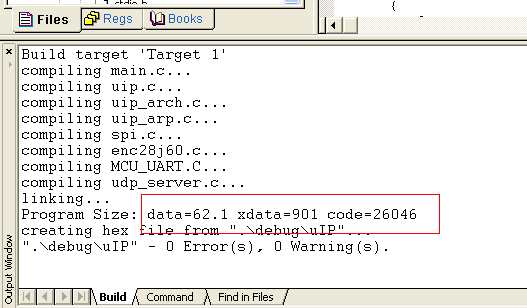
(1) 选择Level 0:Constant folding 时的编译结果
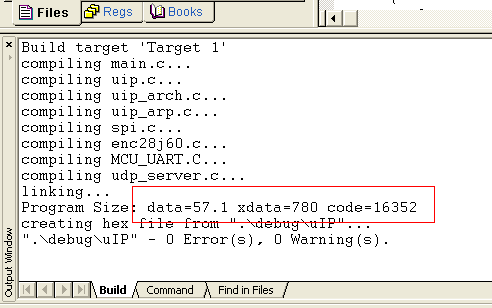
(2)选择Level 5:Common subexpression elimination时的编译结果
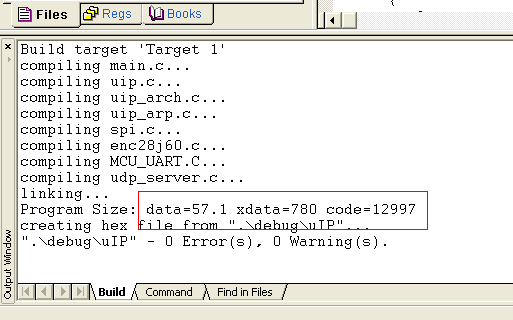
(3)选择Level 9 :Common Block Subroutines时的编译结果
从以上数据我们可以发现,不同的级别,Keil的优化方式是不一样的。
Progarm Size: data=62.1 xdata=901 code=26046
Progarm Size: data=57.1 xdata=780 code=16352
Progarm Size: data=57.1 xdata=780 code=12997
随着优化级别的深入,Keil的编译速度也会变的越来越慢。如果某些时候你的程序太大无法下载进入单片机时,你不妨试试这个方法。
附表: Keil C51中的优化级别及优化作用
第0级
常数合并:编译器预先计算结果,尽可能用常数代替表达式。包括运行地址计算。
第1级
死代码删除:没用的代码段被删除。
第2级
数据覆盖:适合静态覆盖的数据和位段被确定,并内部标识。BL51连接/定位器可以通过全局数据流分析,选择可被覆盖的段。
第3级
窥孔优化:清除多余的MOV指令。这包括不必要的从存储区加载和常数加载操作。当存储空间或执行时间可节省时,用简单操作代替复杂操作。
第4级
寄存器变量:如有可能,自动变量和函数参数分配到寄存器上。为这些变量保留的存储区就省略了。
优化扩展访问:IDATA、XDATA、PDATA和CODE的变量直接包含在操作中。在多数时间没必要使用中间寄存器。
局部公共子表达式删除:如果用一个表达式重复进行相同的计算,则保存第一次计算结果,后面有可能就用这结果。多余的计算就被删除。
Case/Switch优化:包含SWITCH和CASE的代码优化为跳转表或跳转队列。
第5级
全局公共子表达式删除:一个函数内相同的子表达式有可能就只计算一次。中间结果保存在寄存器中,在一个新的计算中使用。
第6级
循环优化:如果结果程序代码更快和有效则程序对循环进行优化。
第7级
扩展索引访问优化:适当时对寄存器变量用DPTR。对指针和数组访问进行执行速度和代码大小优化。
第8级
公共尾部合并:当一个函数有多个调用,一些设置代码可以复用,因此减少程序大小。
第9级
公共块子程序:检测循环指令序列,并转换成子程序。Cx51甚至重排代码以得到更大的循环序列。
不过当你选择了相应的优化级别后,有可能会导致你的程序无法再单片机上准确运行。(因此要注意)
- Keil uVision2 压缩编译后的程序大小
- Keil uVision2 压缩编译后的程序大小
- keil编译后code大小
- Keil-MDK编译完成后代码大小
- #单片机# ------ Keil uVision2 和 stc-isp 的使用(图文教程)
- Keil uVision2下项目文件组织
- Keil uVision2学习笔记1
- Keil ARM 编译的代码大小问题
- keil编译器--程序大小
- keil编译代码后的Program size
- 程序编译后FLASH和SRAM大小的计算
- keil编译的程序 “汉字显示不全、串口发送汉字接收后乱码缺失”问题
- [图]keil uvision2 中调试时候出现的时间“sec”单位是秒
- keil uvision2使用问题及解答
- keil编译的CODE.RW.RO.ZI的大小说明
- keil编译后生成的M51文件解析
- KEIL 编译后的芯片资源使用情况
- Delphi XE2及以后的版本编译后的程序大小问题
- XCode关于多视图切换不显示UIButton等控件的问题
- POJ 2195 Going Home 最小费用最大流 or KM算法
- 深入剖析MongoDB
- ORACLE、JAVA环境设置
- HBase之功能细节
- Keil uVision2 压缩编译后的程序大小
- GDI特效2
- Javascript 面向对象编程
- 计算机启动原理(X86机器)
- 在BlackBerry模拟器或者真机上高效测试WebWorks/PhoneGap程序--不需要重新打包编译
- hadoop作业调优参数整理及原理
- GDI特效3
- 再谈软件测试-工作感悟
- hadoop-eclipse-plugin 编译 打包


